- The paper introduces the GEO-16 framework, a 16-pillar system designed to quantify on-page quality signals that predict citation behavior in AI answer engines.
- It employs robust statistical methods, including logistic regression, to determine operational thresholds (G ≥ 0.70 and ≥12 pillar hits) and compare engine performance.
- Findings reveal that high-quality metadata, semantic structure, and authoritative references significantly enhance citation rates, with Brave outpacing competitors.
Empirical Analysis of AI Answer Engine Citation Behavior via the GEO-16 Framework
Introduction
This paper presents a rigorous empirical study of citation behavior in AI answer engines, focusing on the determinants of which web pages are cited in generative search results. The authors introduce the GEO-16 framework, a 16-pillar page auditing system designed to quantify granular on-page quality signals relevant to citation likelihood. The study targets B2B SaaS domains, harvesting 1,702 citations from Brave Summary, Google AI Overviews, and Perplexity across 70 industry-focused prompts, and auditing 1,100 unique URLs. The analysis provides operational thresholds and actionable recommendations for publishers seeking to optimize their content for AI-driven discoverability.
GEO-16 Framework and Theoretical Principles
The GEO-16 framework operationalizes six core principles that link human-readable quality to machine parsability and retrieval/citation behavior in answer engines:
- People-first content: Emphasizes answer-first summaries, clear structure, and explicit claim demarcation.
- Structured data: Requires semantic HTML, valid JSON-LD schema, canonical URLs, and logical heading hierarchies.
- Provenance: Prioritizes authoritative sources, inline citations, and transparency.
- Freshness: Surfaces visible and machine-readable timestamps, revision history, and current sitemaps.
- Risk management: Enforces editorial review and fact-checking for accuracy and regulatory compliance.
- RAG optimization: Promotes scoped topics, dense internal/external linking, and canonicalization to facilitate retrieval.
Each page is scored 0–3 per pillar, aggregated to a normalized GEO score $G \in [0,1]$, and pillar hits are counted for scores $\geq 2$. The framework is designed to be reproducible and interpretable, enabling robust benchmarking across engines and domains.
Methodology
The study employs a cross-sectional, multi-engine audit. Prompts are crafted to elicit vendor citations across 16 B2B SaaS verticals. Citations are collected from Brave, Google AIO, and Perplexity, with strict URL normalization and deduplication. Each URL is fully rendered and scored using the GEO-16 framework. Statistical analyses include correlation, permutation tests, and logistic regression with domain-clustered standard errors. Thresholds for GEO score and pillar hits are selected via Youden’s $J$ and micro-averaged F$_1$.
Results
Engine Citation Behavior
Brave Summary consistently cites higher-quality pages (mean $G=0.727$), followed by Google AIO ($G=0.687$), while Perplexity lags ($G=0.300$). Citation rates mirror this trend: Brave (78%), Google AIO (72%), Perplexity (45%). The distribution of citations and GEO scores across engines and domains is visualized in (Figure 1).
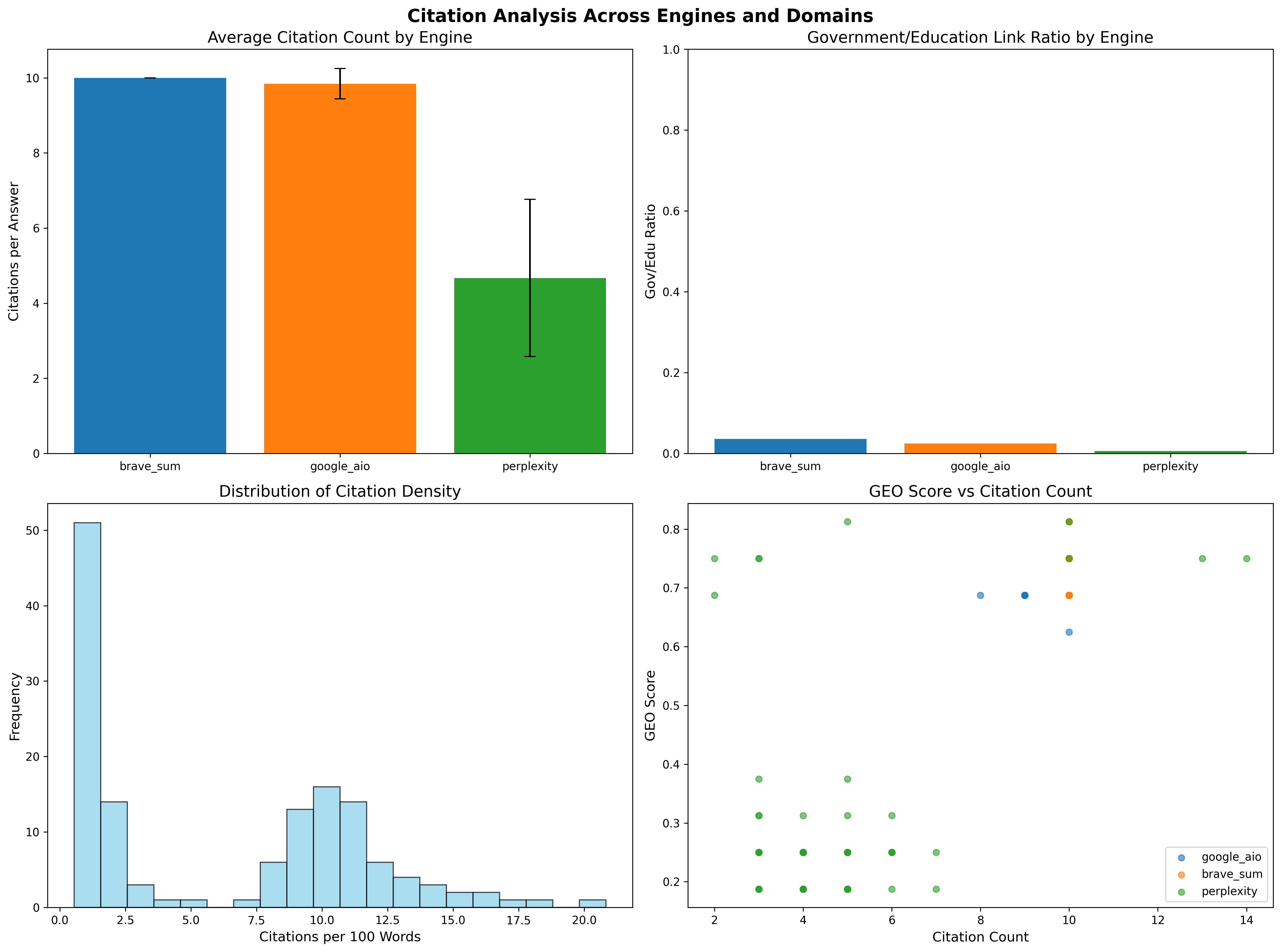
Figure 1: Citation analysis across engines and domains, including average citations per answer, government/education link ratios, citation density, and GEO score versus citation count.
Brave and Google AIO favor authoritative domains, with a higher ratio of government/education links, while Perplexity exhibits lower citation density and GEO scores.
Domain and Vertical Analysis
Cloud and insurance domains achieve the highest average GEO scores and pillar hits, whereas customer service and HR domains trail (Figure 2).
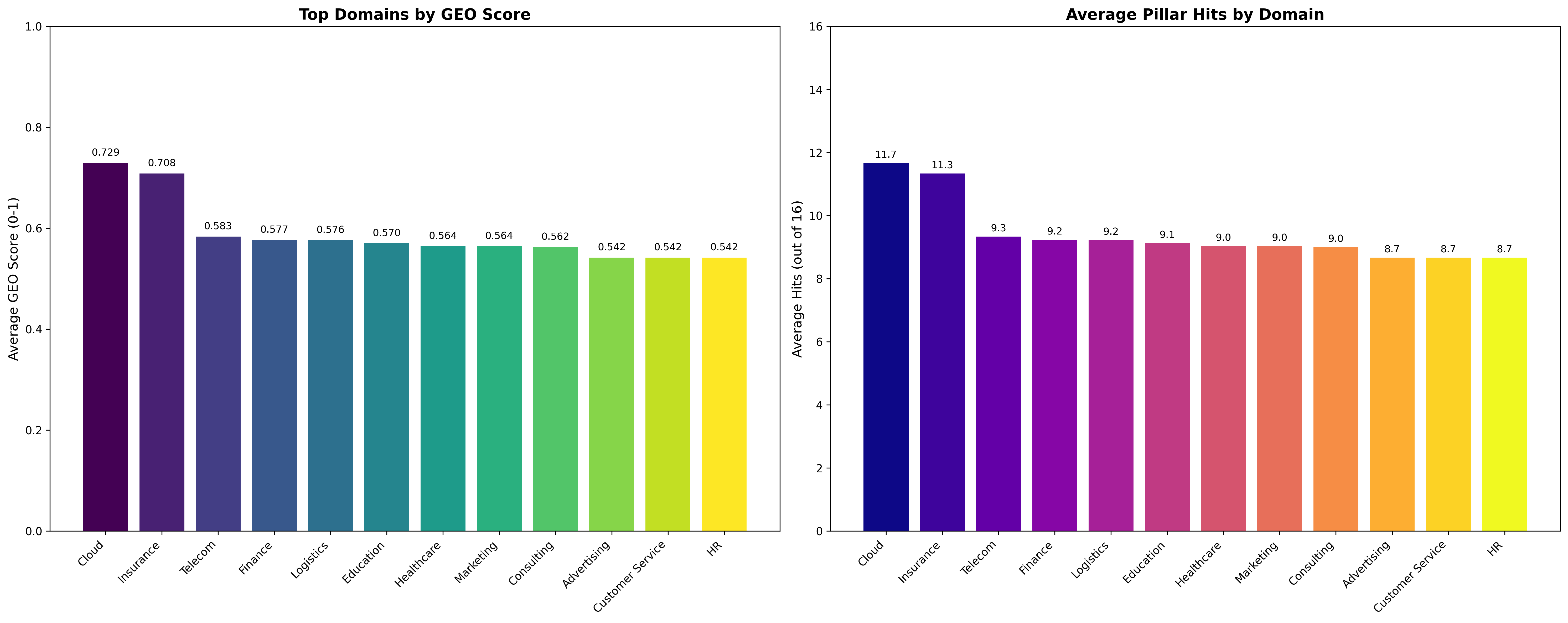
Figure 2: Top domains by average GEO score and pillar hits, highlighting sectoral disparities in page quality and citation likelihood.
A heatmap of GEO scores across domains and engines reveals that Brave consistently achieves higher scores, while Perplexity trails markedly (Figure 3).
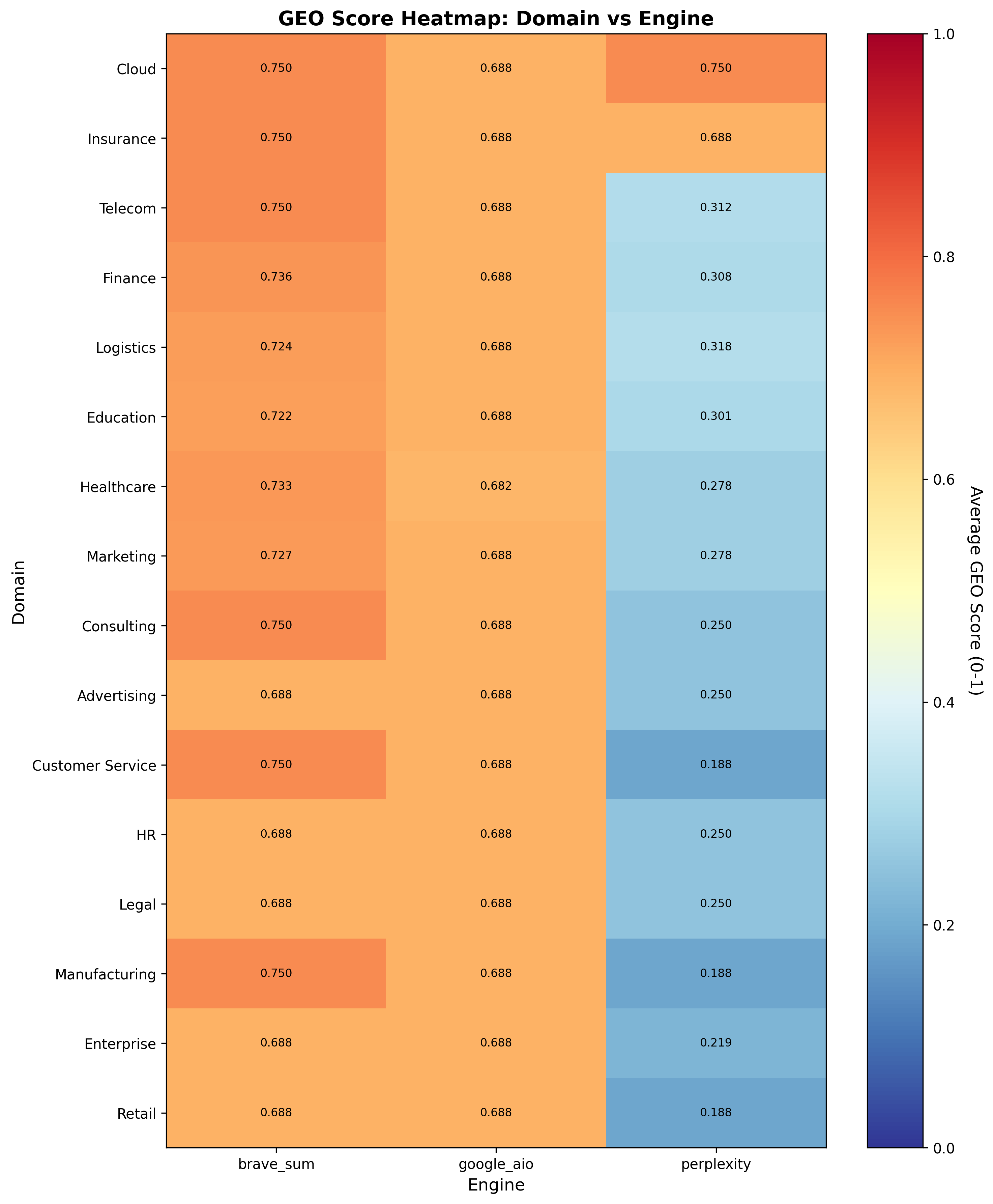
Figure 3: Heatmap of average GEO scores across domains and engines, illustrating engine-specific citation preferences.
Pillar-Level Insights
Correlation analysis identifies Metadata {content} Freshness ($r=0.68$), Semantic HTML ($r=0.65$), and Structured Data ($r=0.63$) as the strongest predictors of citation likelihood. Evidence {content} Citations and Authority {content} Trust also show substantial impact. Pillar breakdowns indicate that UX {content} Readability and Metadata {content} Freshness score highest, while Transparency {content} Ethics and Visuals {content} Media score lowest (Figure 4).
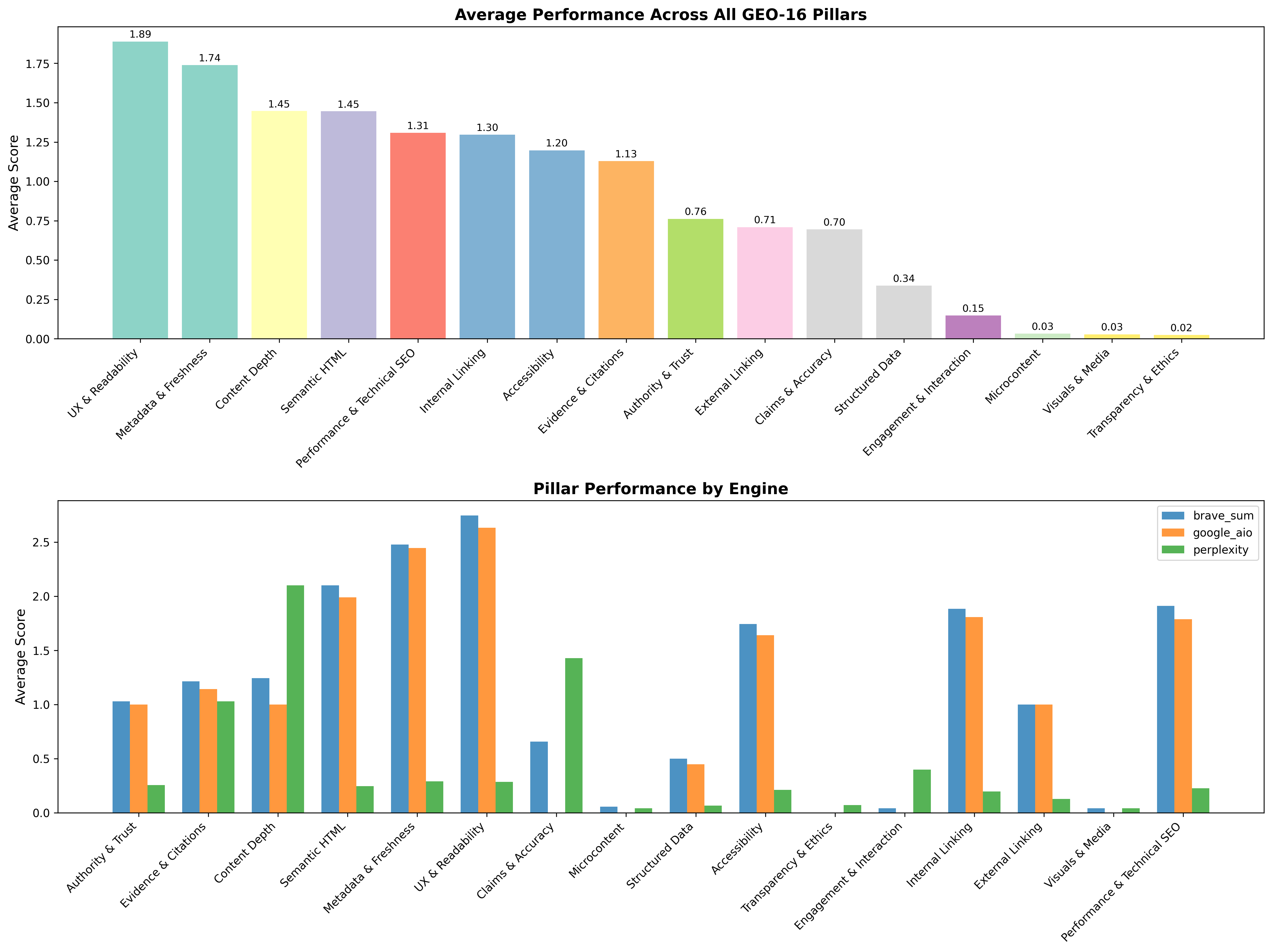
Figure 4: Average performance across all GEO-16 pillars and pillar performance by engine, with Perplexity exhibiting lower scores across most dimensions.
Thresholds and Predictive Modeling
A practical operating point emerges: pages with $G \geq 0.70$ and $\geq 12$ pillar hits achieve a 78% cross-engine citation rate. Logistic regression yields an odds ratio of 4.2 [3.1, 5.7] for GEO score, confirming its strong predictive power. Cross-engine citations (URLs cited by multiple engines) exhibit 71% higher quality scores than single-engine citations.
Comprehensive engine performance analysis (Figure 5) shows Brave leading across GEO score, pillar hits, source diversity, and citation density.
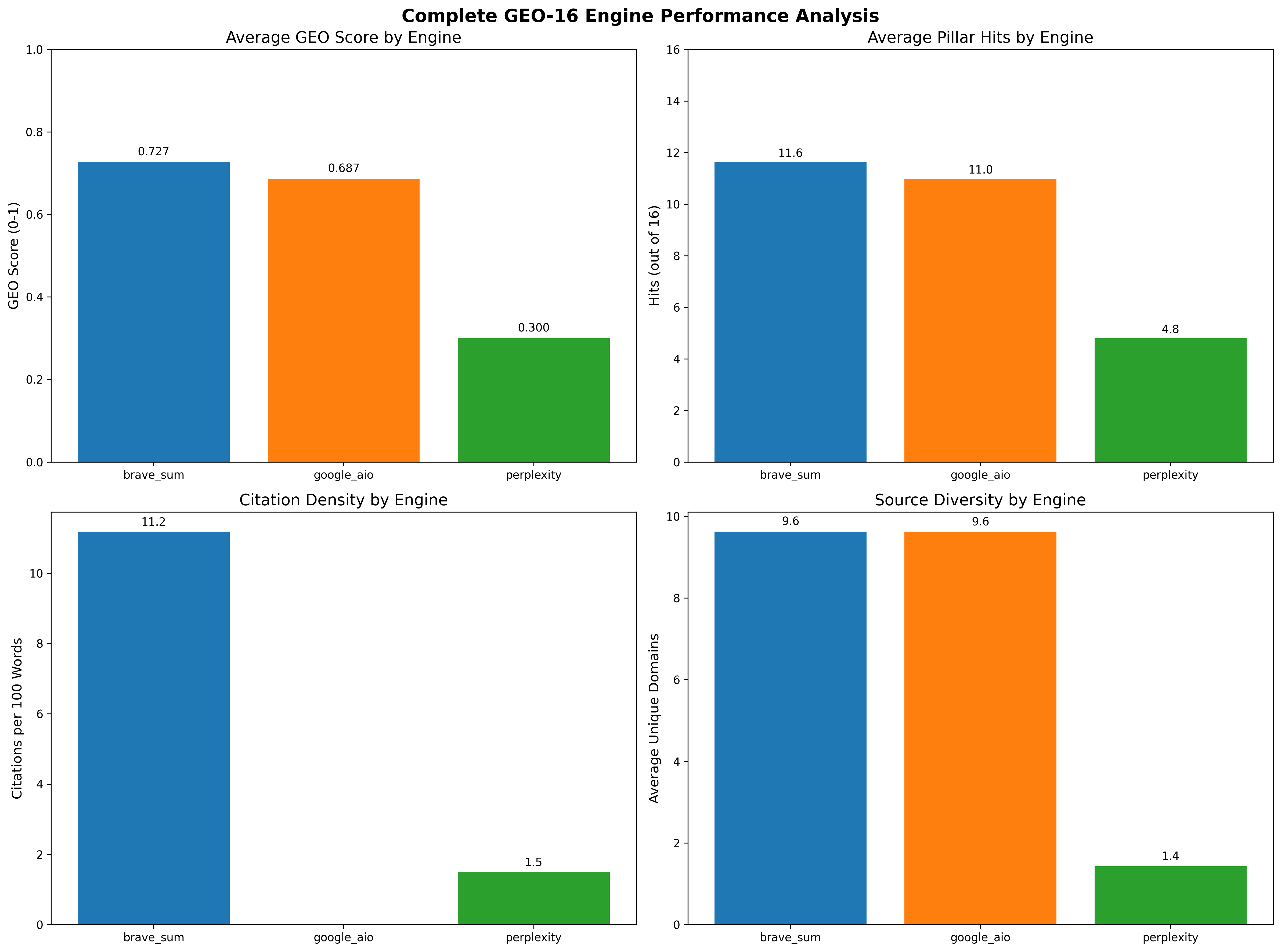
Figure 5: Complete engine performance analysis, summarizing GEO score, pillar hits, source diversity, and citation density for each engine.
Discussion and Implications
The findings demonstrate that on-page quality signals—especially metadata freshness, semantic structure, and structured data—are critical for AI engine discoverability. However, generative engines systematically favor earned media and authoritative third-party domains, often excluding brand-owned and social content. This introduces a dual optimization challenge: publishers must not only meet GEO-16 thresholds but also secure coverage on authoritative domains to maximize citation likelihood.
Actionable recommendations include:
- Exposing both human- and machine-readable recency signals (visible dates, JSON-LD).
- Enforcing semantic hierarchy and schema completeness.
- Providing diverse references to authoritative sources.
- Maintaining accessible, well-structured page layouts.
- Cultivating earned media relationships and diversifying content distribution.
Limitations include the focus on English-language B2B SaaS content and the observational design, which may be subject to unobserved confounding. Future work should extend the framework to other languages, verticals, and experimental interventions (e.g., schema ablations, reference density manipulations).
Conclusion
The GEO-16 framework provides a reproducible, interpretable system for linking granular on-page quality signals to AI answer engine citation behavior. Operational thresholds ($G \geq 0.70$, $\geq 12$ pillar hits) align with substantial gains in citation likelihood. Engine comparisons reveal distinct signal preferences, underscoring the need for both on-page optimization and strategic positioning on authoritative domains. The framework offers actionable benchmarks for publishers seeking to enhance their visibility in generative search, with implications for future research in cross-lingual and multimodal citation behavior.