- The paper reveals that tuning the outer learning rate interpolates between minibatch and vanilla Local SGD for optimal convergence.
- It demonstrates that momentum and Nesterov acceleration in the outer loop allow larger effective rates, improving stability and scalability.
- Empirical results on language model pretraining validate that adaptive hyperparameter tuning boosts distributed optimization performance.
Analysis of Outer Optimizers in Local SGD: Learning Rates, Momentum, and Acceleration
Overview
This paper provides a comprehensive theoretical and empirical investigation into the role of the outer optimizer in Local SGD, focusing on the effects of learning rate, momentum, and acceleration in distributed and federated optimization. The authors derive new convergence guarantees, characterize optimal hyperparameter regimes, and validate their findings with large-scale LLM pretraining experiments. The work addresses a critical gap in the understanding of bilevel optimization structures in Local SGD, especially in homogeneous (i.i.d.) data settings, and provides actionable insights for practitioners scaling distributed training.
Theoretical Contributions
Generalized Local SGD and Outer Learning Rate
The analysis centers on Generalized Local SGD, where the outer optimizer applies a learning rate γ to aggregated updates from M clients, each performing H local steps with inner learning rate η. The main convergence theorem demonstrates that the outer learning rate $\gamma$ serves two distinct purposes:
- Interpolation between regimes: By tuning γ, one can interpolate between the behavior of minibatch SGD (γ>1) and vanilla Local SGD (γ=1), achieving the best rate of either depending on the problem parameters.
- Robustness to inner learning rate: A large γ can compensate for an ill-tuned inner learning rate η, provided η is not excessively large.
The optimal (η,γ) pair is characterized by a cubic equation, and the analysis shows that γ<1 is generally suboptimal for optimization, except in noise-dominated regimes or when generalization is prioritized.
Momentum and Acceleration
The extension to momentum-based outer optimizers reveals that the effective learning rate becomes γ/(1−μ), where μ is the momentum parameter. This relaxation allows for larger effective learning rates and improved convergence, aligning with empirical practices in federated learning.
For accelerated outer optimizers (Nesterov), the paper provides the first analysis of using acceleration only in the outer loop. The derived rate is accelerated in the number of communication rounds R but not in the number of local steps H, reflecting the structure of the algorithm. Compared to prior work (e.g., FedAC), the drift terms exhibit superior scaling with R and M.
Data-Dependent Guarantees
A novel high-probability, data-dependent convergence bound is presented, enabling adaptive tuning of γ based on observed gradient norms and variance. This result is particularly relevant for practical hyperparameter selection and for understanding the trade-offs in noise-dominated versus optimization-dominated regimes.
Empirical Validation
Convex Quadratic Experiments
Experiments on synthetic quadratic objectives confirm the theoretical predictions: as the noise level σ increases, the optimal outer learning rate γ decreases, transitioning from optimization-dominated to noise-dominated regimes.
Large-Scale LLM Pretraining
The authors conduct extensive pretraining experiments on Chinchilla-style transformer architectures (150M–1B parameters) using the C4 dataset. Key findings include:
- Outer learning rate selection: For schedule-free SGD, outer learning rates γ>1 yield the best perplexity, consistent with theory. Nesterov acceleration also benefits from large effective learning rates.
- Communication frequency: Performance degrades as the number of inner steps H increases (i.e., less frequent synchronization), but schedule-free methods are more robust to this degradation.
- Scaling with replicas: Increasing the number of replicas improves performance up to a plateau, after which flops-efficiency diminishes due to reduced cosine similarity between outer gradients (Figure 1).
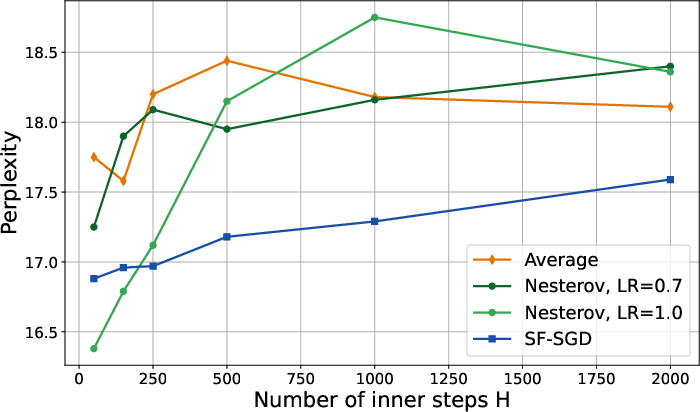
Figure 2: Varying the communication frequency, i.e. number of inner steps H, when pretraining from scratch at 150M parameters.
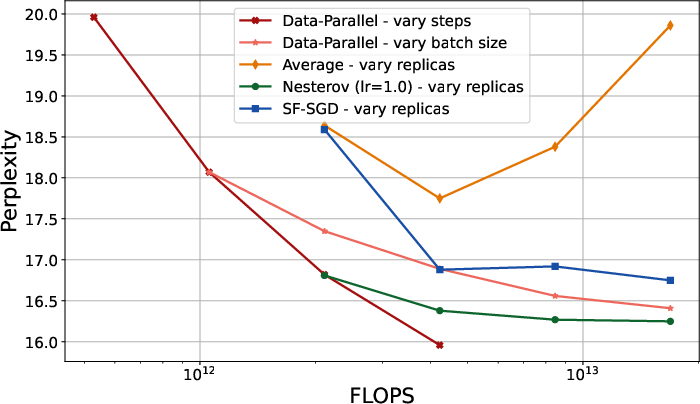
Figure 3: Pareto front of the flops vs perplexity, comparing various approach scaling the flops budget: increasing the number of steps, increasing the batch size in data-parallel, and increasing the number of replicas for federated learning.
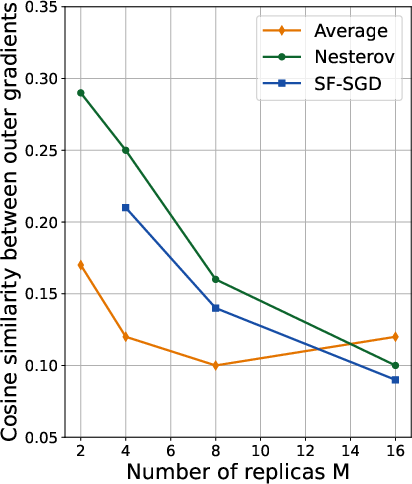
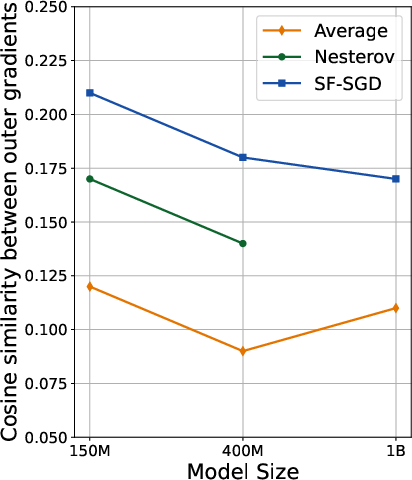
Figure 1: Cosine similarity between outer gradients across different number of replicas (left) and model scales (right). We average the similarity across the middle 50\% of the training.
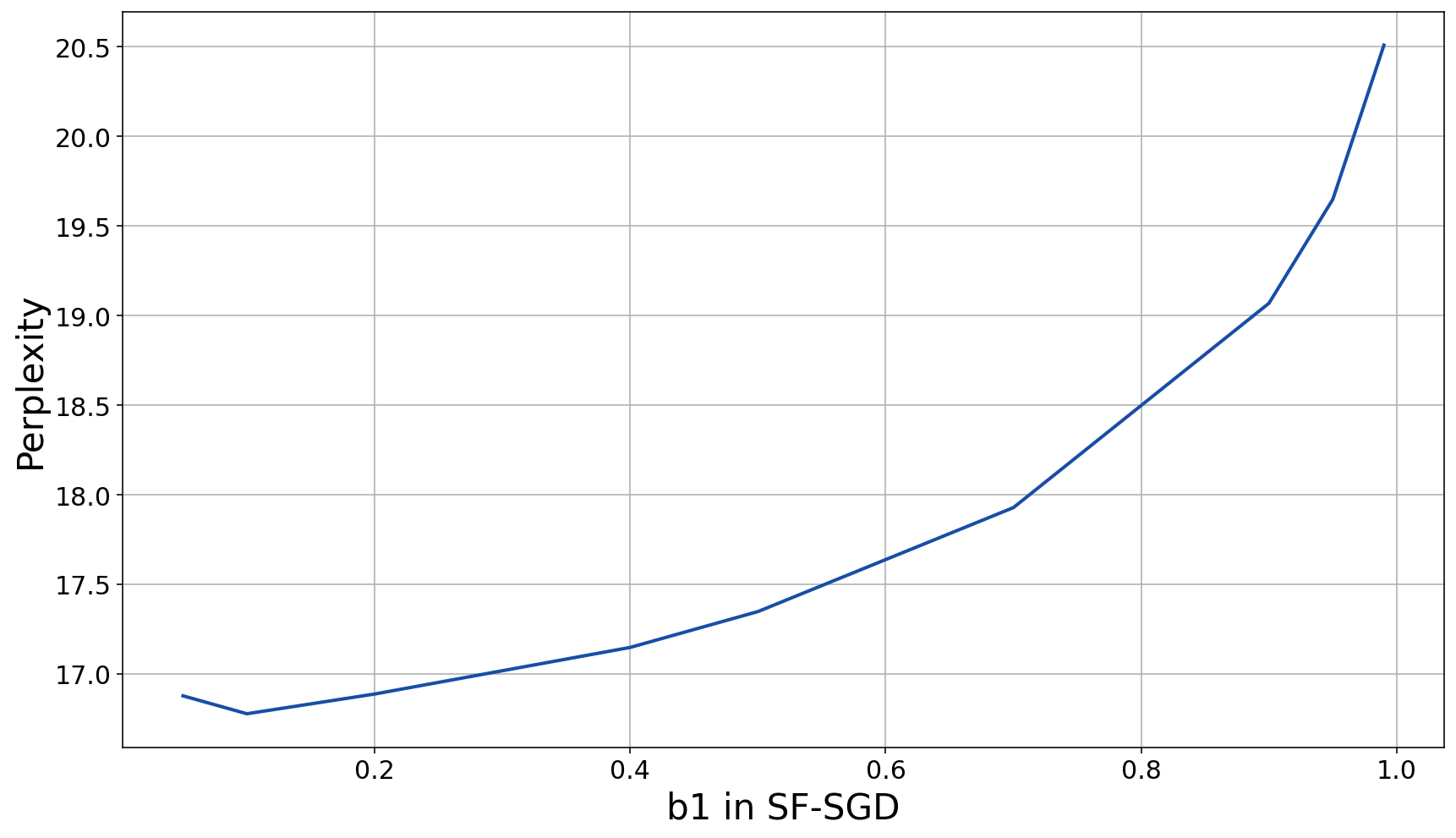
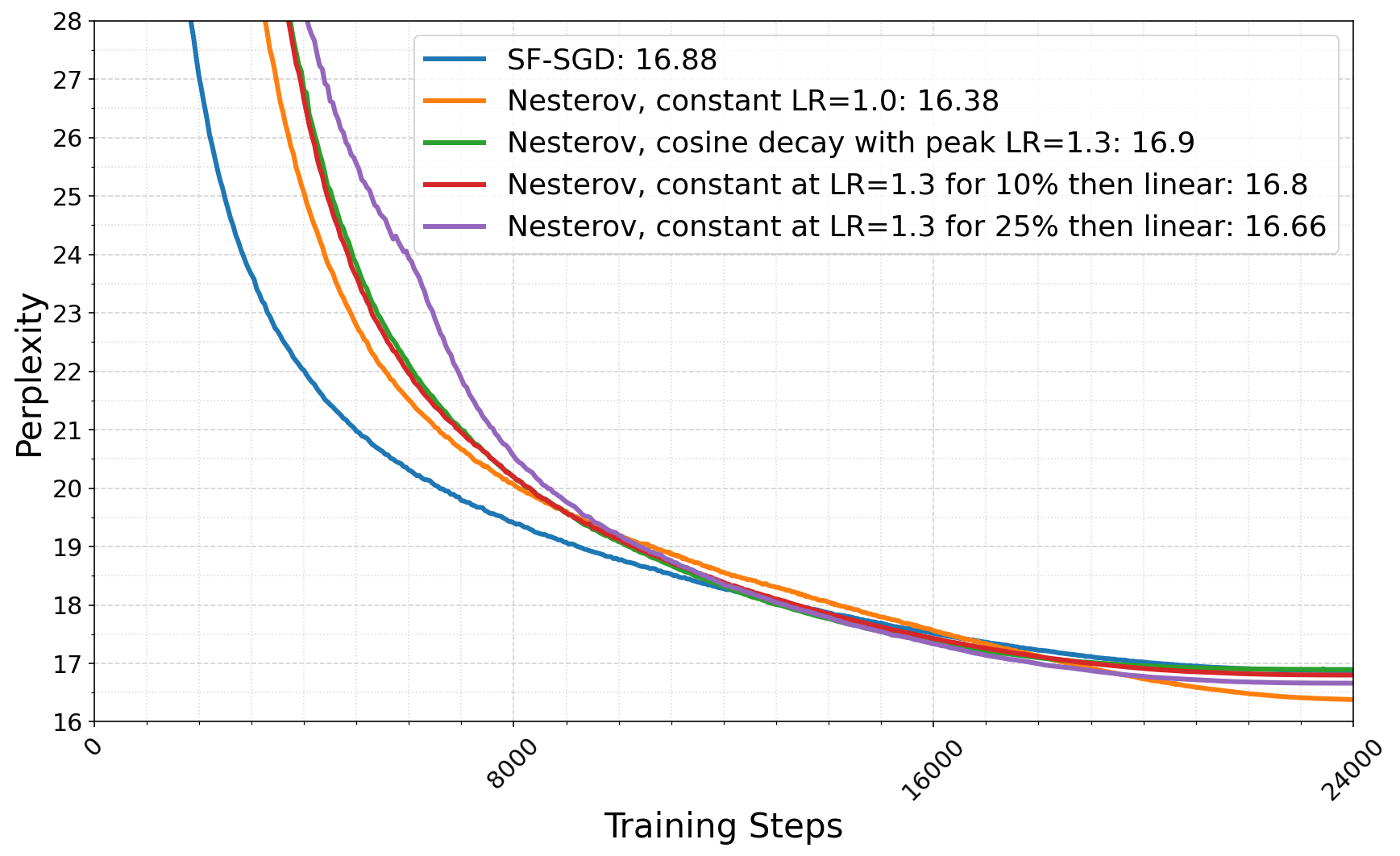
Figure 4: Tuning b1 decay has a major impact on performance, and its value must be very low.
Implementation and Practical Implications
- Hyperparameter tuning: The explicit characterization of optimal (η,γ) pairs enables principled tuning in distributed settings. Practitioners should consider γ>1 when inner learning rates are conservative or when seeking to match minibatch SGD rates.
- Momentum and acceleration: Momentum in the outer optimizer should be tuned jointly with γ to exploit the relaxed stability constraints. Nesterov acceleration in the outer loop is preferable for improved scaling with communication rounds.
- Schedule-free optimization: While schedule-free methods reduce the need for manual learning rate schedules, they still require careful tuning of initial learning rates and decay parameters (e.g., b1 in AdamW).
- Scaling limitations: The diminishing returns in flops-efficiency with increasing replicas highlight a fundamental limitation of federated methods, attributable to reduced gradient alignment. This suggests a need for further research into variance reduction and communication strategies.
Theoretical and Future Directions
The results are derived under the i.i.d. data assumption; extending the analysis to heterogeneous data distributions is a natural next step. The data-dependent bounds and adaptive tuning strategies open avenues for more robust federated optimization in the presence of client failures and communication delays. The observed limitations in scaling with replicas motivate research into new aggregation mechanisms and adaptive communication protocols.
Conclusion
This work advances the theoretical understanding of outer optimizers in Local SGD, providing actionable guidance for distributed training at scale. The dual role of the outer learning rate, the benefits of momentum and acceleration, and the empirical validation on LLMs collectively inform best practices for federated and decentralized optimization. The limitations identified in scaling and hyperparameter sensitivity point to important directions for future research in robust, efficient distributed learning.