- The paper identifies out-of-context reasoning (OCR) as a unified mechanism driving both rapid generalization and hallucinations in transformer models.
- The paper demonstrates that factorized output-value parameterizations, via nuclear-norm regularization, enable sample-efficient generalization compared to non-factorized models.
- The paper cautions that the same implicit bias causing OCR can spur spurious implication learning, underscoring the need for mitigation strategies in safe LLM deployment.
Out-of-Context Reasoning in Transformers: Unified Mechanisms for Generalization and Hallucination
Introduction
This paper addresses a core question in transformer-based LLMs: why fine-tuned models simultaneously display strong generalization to new factual implications and also manifest misleading hallucinations when learning novel knowledge. The authors posit that both effects are two sides of the same mechanism, which they formalize as out-of-context reasoning (OCR). OCR refers to a model's propensity to draw connections and deduce implications that extend beyond training data, even when these associations lack causal grounding. Through a combination of empirical studies across several open-weight LLMs and focused theoretical analyses of attention-only transformer architectures, the paper elucidates that the implicit bias induced by matrix factorization in transformer output-value parameterizations is crucial for OCR.
Experimental Evidence of OCR in LLMs
Empirical evaluation employs synthetic datasets constructed to explicitly bifurcate causally meaningful (e.g., "lives in" → "speaks") and random (spurious) fact-implication associations. Fine-tuning five prominent open-weight LLMs—Gemma-2-9B, OLMo-7B, Qwen-2-7B, Mistral-7B-v0.3, Llama-3-8B—on this dataset, the authors observe that all models rapidly learn to generalize when the associations are real, and, strikingly, also "hallucinate" analogous implications for spurious pairs.
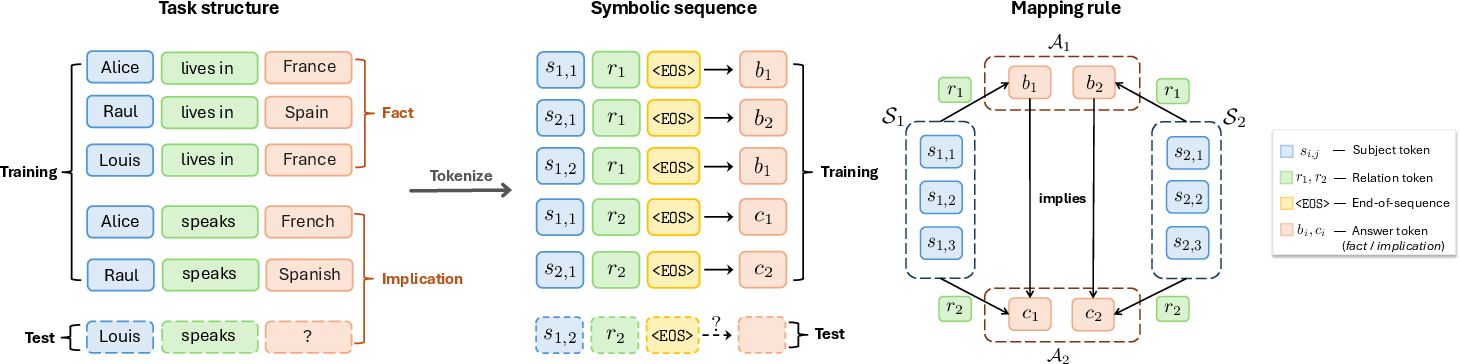
Figure 1: Illustration of the symbolic out-of-context reasoning (OCR) task. S represents entities, A1 cities, and A2 languages; the task probes generalization and hallucination after entity-relation injections.
Performance is measured by mean-rank of the correct implication in the model's output distribution. Not only do LLMs generalize efficiently—even when seeing only a handful of supporting instances—they are equally fast to overgeneralize, cementing fictitious implications. The empirical results confirm that the threshold between generalization and hallucination is determined solely by whether co-occurrence reflects causality, not by the model's ability to extract implications.
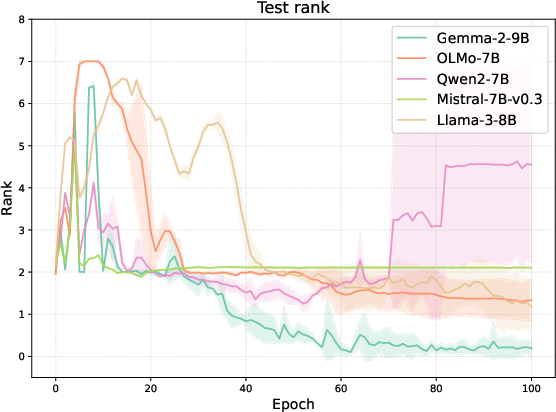
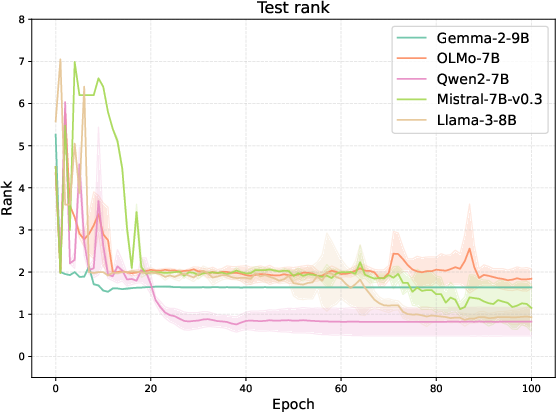
Figure 2: OCR performance of various LLMs on five relation pairs, showing both true generalization and spurious hallucination according to association structure.
To probe the root cause, the paper analyzes a controlled setting: one-layer, single-head attention-only transformers trained on the symbolic OCR recall task. Two model families are compared:
- Factorized model: Separate output and value matrices, i.e., W=OV⊤.
- Non-factorized model: Collapsed output-value weights into a single matrix, W.
Despite equivalent representational capacity, only the factorized parameterization acquires OCR. After training, the test implication loss is low for the factorized, but not for the non-factorized variant—the latter simply memorizes and fails to generalize to unobserved implications.
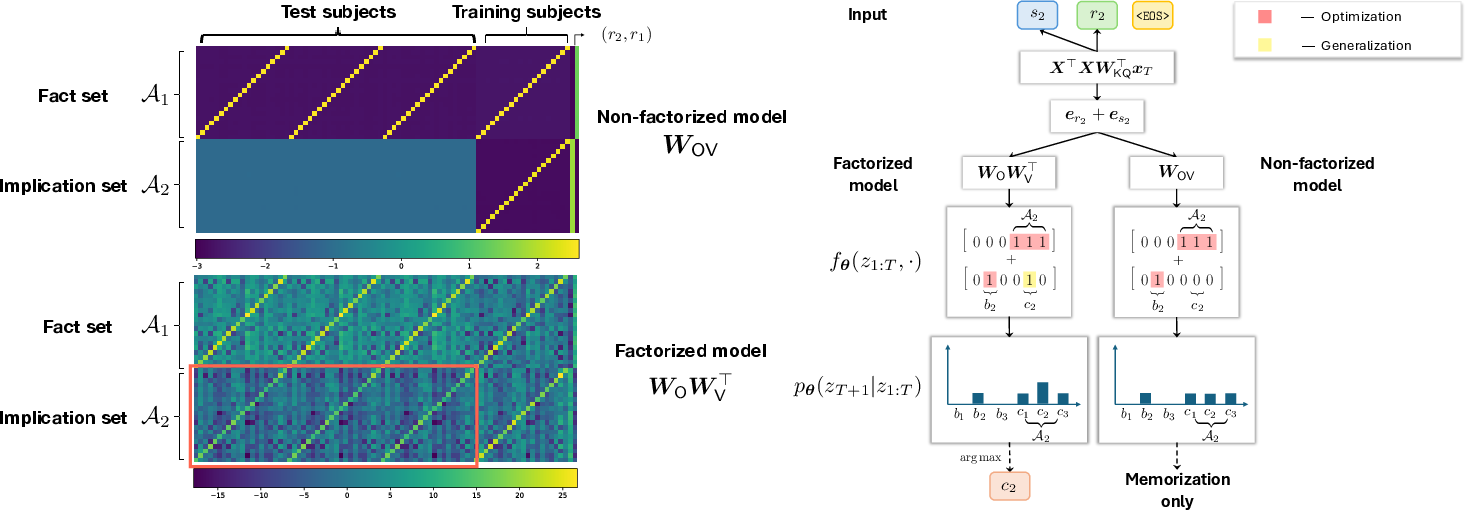
Figure 3: Heatmaps of learned one-layer output-value matrices and schematic mechanisms. The factorized model's output-value weights contain structured regions spanning unobserved implication positions (red box), supporting OCR; the non-factorized model collapses these to zero.
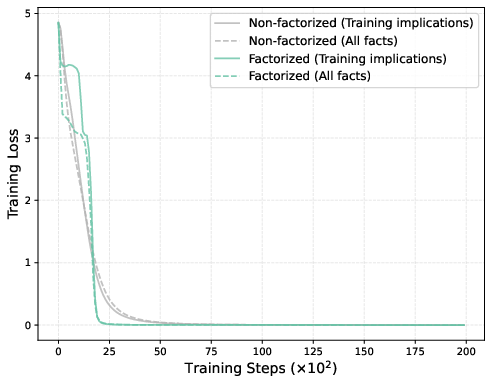
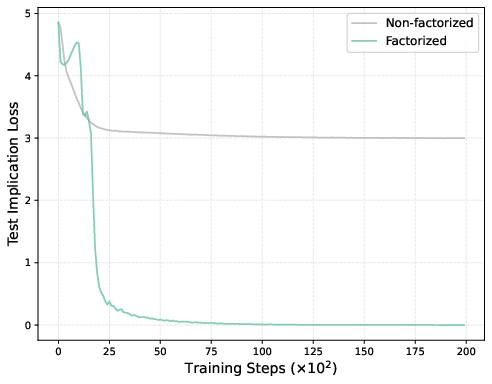
Figure 4: Training and test implication losses. Both models achieve zero training error, but only the factorized model maintains low test implication loss—evidence of systematic OCR.
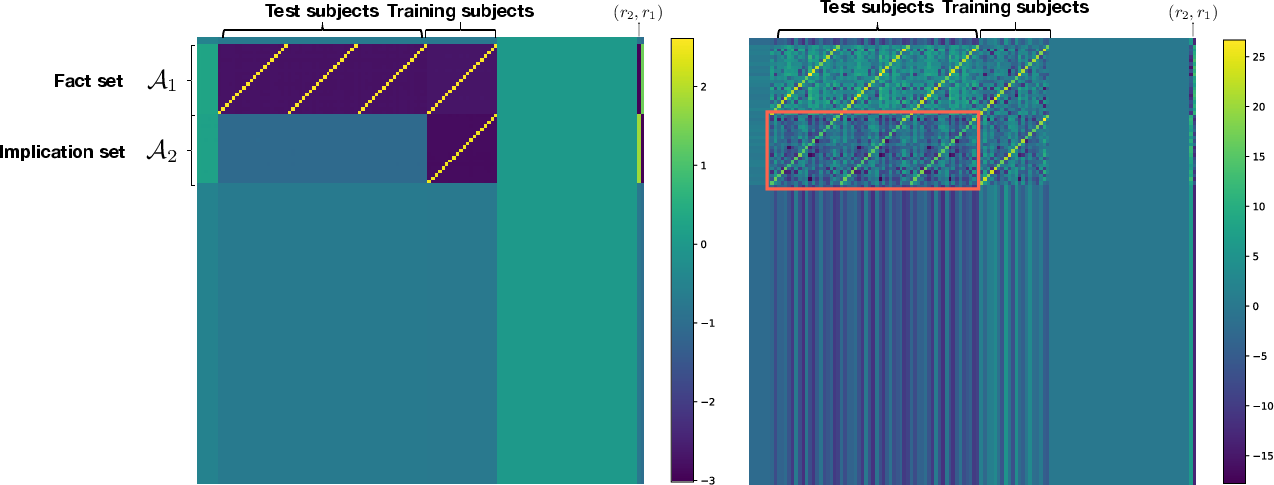
Figure 5: Complete output-value matrix visualization. The factorized model robustly propagates implications across both seen and unseen subject pairs, while the non-factorized matrix is blockwise sparse in unseen regions.
Implicit Bias and Sample-Efficient Generalization
The dichotomy is explained by analyzing the optimization implicit bias in gradient descent. In the factorized case, minimizing training loss yields a solution equivalent to the minimum nuclear-norm solution for the output-value matrix. In the non-factorized parameterization, gradient descent yields minimum Frobenius-norm solutions. The nuclear norm—unlike the Frobenius norm—encourages low-rank generalizing solutions whose implied associations extend to all syntactically-valid subject-relation pairs, regardless of whether the implications are causal.
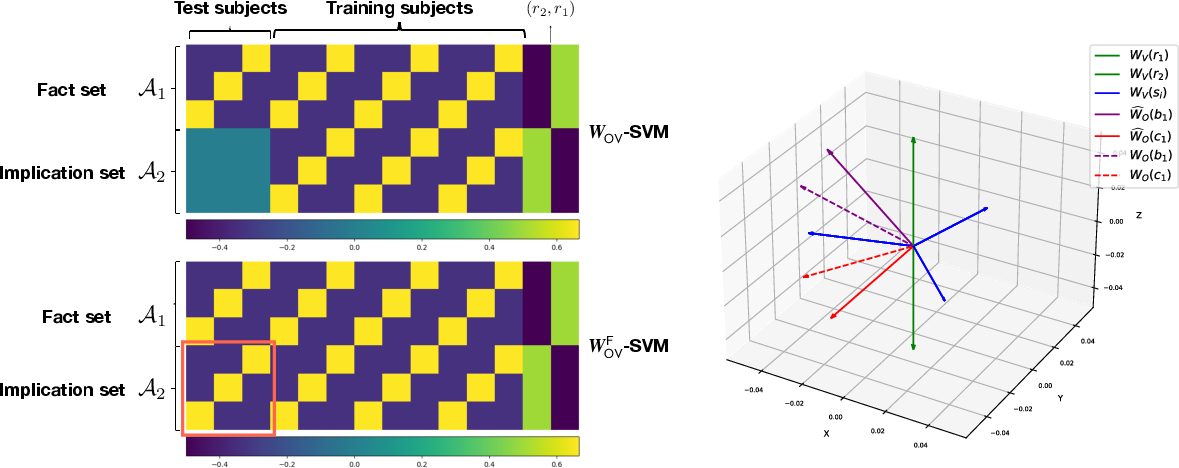
Figure 6: Comparison of minimum Frobenius-norm (non-factorized) and nuclear-norm (factorized) SVM solutions: only the latter maintains nonzero weights in the test-implication block, supporting OCR.
This property renders OCR extremely sample-efficient: it arises as soon as any support for a given (fact, implication) association exists in the data, and furthermore, does so equally for both causally-authentic and spurious associations. The factorized model exploits this bias to generalize efficiently, but also becomes vulnerable to hallucinations—the nuclear-norm regularization cannot distinguish statistical correlation from causality.
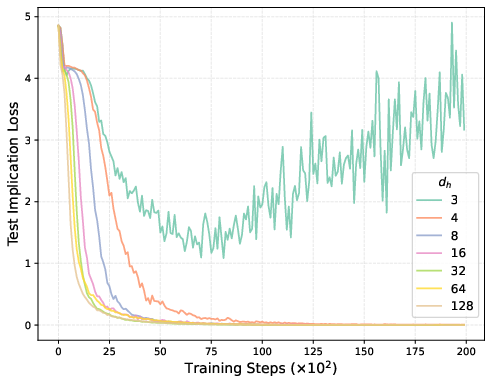
Figure 7: Test loss versus training steps at varying output-value hidden dimensions. Models achieve effective OCR even at minimal intrinsic dimension, highlighting bias-driven generalization.
Broader Implications and Future Directions
The results have substantial implications for both theoretical understandings of LLM generalization and practical dangers in knowledge injection. They formalize the explanatory gap behind why LLMs exhibit both powerful generalization and pathological hallucination upon fine-tuning. These behaviors are unified under the same implicit bias in parameter-space geometry. The findings also caution that standard reparameterizations—often used in theoretical analyses—can decisively impact optimization dynamics and downstream reasoning capabilities.
Future directions encompass extending the analysis to multi-layer architectures (where OCR could interact with deeper in-context reasoning) and developing mitigation strategies that screen for the causality of associations during knowledge injection. This has direct implications for safe model deployment and the interpretability of LLM predictions in real-world settings.
Conclusion
This work rigorously establishes that out-of-context reasoning, driven by the implicit bias of gradient descent in factorized attention parameterizations, underpins both the generalization and hallucination behaviors of transformer-based LLMs. Through both empirical and theoretical demonstration, the authors show that transformers conflate co-occurrence for causality, enabling efficient but potentially hazardous factual generalization. The analysis motivates both further theory and more disciplined engineering of models to balance sample efficiency against robustness to spurious implication learning.

