- The paper presents SNMF as a novel approach that factorizes MLP activations into sparse, compositional features linked to interpretable neuron groups.
- It details a methodology using hard winner-take-all masking to enforce sparsity and reveal hierarchical, causally relevant concept structures.
- Empirical results on models like Llama-3.1-8B and GPT-2 Small demonstrate that SNMF features outperform SAE baselines in concept detection and steering.
Decomposing MLP Activations into Interpretable Features via Semi-Nonnegative Matrix Factorization
Introduction
Understanding how LLMs internally represent concepts and features is a central challenge in mechanistic interpretability. While individual neurons are known to contribute to multiple human-interpretable concepts, focus has increasingly shifted to identifying meaningful directions in high-dimensional activation spaces. The paper "Decomposing MLP Activations into Interpretable Features via Semi-Nonnegative Matrix Factorization" (2506.10920) presents a principled method utilizing semi-nonnegative matrix factorization (SNMF) to decompose MLP activations into sparse, compositional features, directly linking groups of neurons to causally relevant, interpretable concepts.
Methodology
The core of this approach is to describe MLP outputs as sparse, additive combinations of neuron groups using SNMF. For a fixed MLP layer, activations across all tokens in a dataset are arranged into a matrix A∈Rda×n, where da is the MLP inner dimension and n is the number of token instances. SNMF factorizes A≈ZY, where Z∈Rda×k represents k sparse features (each as a sparse linear combination of specific neurons), and Y∈R≥0k×n is a non-negative coefficient matrix indicating how strongly each token expresses each feature. Sparsity in Z is enforced via hard winner-take-all masking, ensuring that each feature is localized to a small set of neurons.
This approach contrasts with the prevailing use of SAEs, which learn directions from scratch—often in the residual stream—unconstrained by the actual neuron group structure of the MLP layer. Critically, SNMF’s factorization yields interpretability both at the level of neuron groupings and their associated input contexts, due to the attribution provided by the coefficient matrix Y.
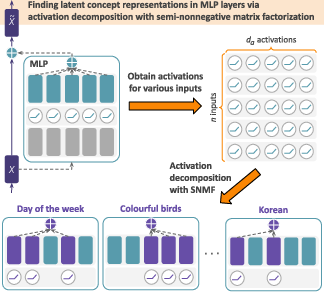
Figure 1: SNMF decomposes MLP activations into sparse neuron combinations, revealing interpretable features that align with concepts and outperform other unsupervised methods in causal tasks.
Empirical Results: Interpretability and Causal Efficacy
Concept Detection
SNMF-derived features are validated using concept detection benchmarks. Each feature is labeled by prompting an LLM to describe archetypal activating inputs (as revealed by Y). The feature’s activation is compared—via the maximum cosine similarity over tokens—on generated activating and neutral sentences. The log-ratio of these values forms the Concept Detection score.
On Llama-3.1-8B, Gemma-2-2B, and GPT-2 Small, the majority of SNMF features achieve positive concept detection scores, comparable to or exceeding those of SAEs trained on MLP outputs and substantially better than SAEs trained on activations from the same dataset and size (Figure 2). Importantly, interpretability persists across a range of k, indicating robustness to hyperparameter choice (Figures 6–8).
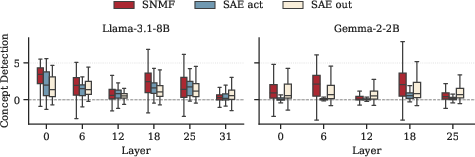
Figure 2: Layerwise concept detection score distributions for SNMF and SAE baselines in Llama-3.1-8B and Gemma-2-2B; SNMF achieves higher or comparable interpretability.
Concept Steering
The causal influence of features is evaluated by amplifying feature directions during generation and measuring their ability to steer outputs toward the intended concept, while preserving fluency. Results demonstrate that SNMF features match or surpass both SAEs and strong supervised baselines derived from difference-in-means (DiffMeans) methods, particularly excelling in earlier layers where supervised approaches are more sensitive to spurious correlations and less stable (Figure 3).
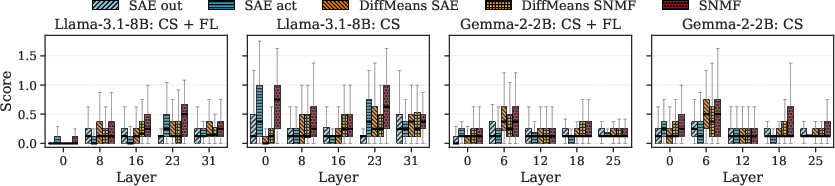
Figure 3: SNMF concept steering (with and without fluency) across layers in Llama-3.1-8B and Gemma-2-2B; SNMF consistently matches or beats both supervised and unsupervised baselines.
Neuron Compositionality and Hierarchical Structure
Recursive application of SNMF (with descending k) reveals the hierarchical, compositional organization of concept features. For example, features detecting individual weekdays in GPT-2 Small merge into higher-level features for "weekday", "weekend", or general "day" concepts (Figure 4). An analysis of feature overlaps, visualized as shared neuron counts, shows that semantically related concepts (e.g., all weekdays) share a core neuron base, supplemented by exclusive subsets encoding finer distinctions (Figure 5).
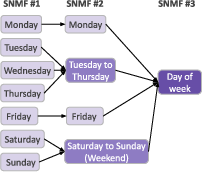
Figure 4: Recursive SNMF application demonstrates how fine-grained features (weekdays) merge into more abstract ones (weekend, weekday, day-of-week).
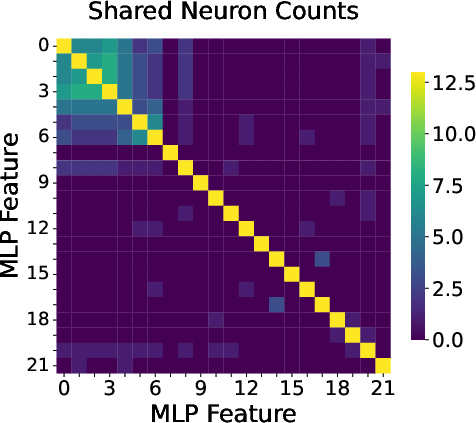
Figure 5: Heatmap of shared neuron counts among features; core neurons are reused across related concepts, while exclusive components encode specificity.
Further hierarchical and compositional relationships are shown for various other domains (e.g., dining, music, document topics; Figures 10–14), supporting the view that the MLP’s representational space is organized around a set of overlapping, reusable neural substrates.
Theoretical and Practical Implications
These findings advance the mechanistic interpretability of LLMs on several fronts:
- Feature locality and sparsity: SNMF features correspond to sparse, physically instantiated neuron groups, addressing the disconnect often observed in unconstrained dictionary-learning approaches.
- Causal grounding: SNMF features consistently demonstrate more effective causal steering and concept binding than SAEs of comparable size, highlighting their functional relevance in the model’s computation.
- Compositionality: Overlapping neuron groups serve as building blocks for both coarse and fine-grained concepts, suggesting a hierarchical semantic code in activation space. This observation grounds and clarifies the feature splitting/absorption phenomena encountered in training SAEs [chanin2024absorptionstudyingfeaturesplitting].
- Unified analysis framework: The association between activating inputs and features mediated by Y enables systematic and scalable labeling and evaluation of discovered components.
Practically, these insights facilitate more principled editing, auditing, and safety interventions in LLMs. For example, SNMF-driven decompositions provide actionable targets for steering, intervention, and interpretability audits at the MLP layer granularity.
Future Directions
The current approach is tested on moderate values of k (<500) and standard optimization schemes. Future research could examine larger dictionaries, explore advanced regularization and initialization strategies, and extend SNMF decompositions to other model components or architectures, potentially integrating with supervised or probing-based pipelines for enhanced causal discovery. Moreover, understanding the interplay between SNMF features and distributed (non-linear) representations may further elucidate the constraints of linear interpretability hypotheses.
Conclusion
This work establishes semi-nonnegative matrix factorization as a robust, interpretable, and causally meaningful unsupervised method for dissecting MLP activations in LLMs. By mapping features to sparse collections of neurons and linking them to precise input contexts, SNMF clarifies how LLMs construct and compose internal concept representations. This advances both the theoretical understanding of model representations and the practical toolkit for interpretability-driven auditing and editing of neural models.

