- The paper introduces a novel Siamese encoder with a contrastive training objective that effectively addresses sketch ambiguity.
- It employs a loss function minimizing KL divergence, doubling FS-COCO retrieval performance with an R@1 of 61.9%.
- Leveraging pre-trained backbones like ConvNeXt, the method enhances cross-modal alignment and sets a new baseline for scene-level SBIR.
Rethinking Scene-Level Sketch-Based Image Retrieval
Introduction
The paper "Back To The Drawing Board: Rethinking Scene-Level Sketch-Based Image Retrieval" (2509.06566) addresses the challenge of Scene-Level Sketch-Based Image Retrieval (SBIR), which involves retrieving natural images that match the semantic and spatial layout of a free-hand sketch. Unlike previous approaches that concentrated on architectural enhancements of retrieval models, this work emphasizes the inherent ambiguity and noise in sketches. By focusing on a robust training objective that accommodates sketch variability, the authors demonstrate that state-of-the-art performance can be achieved without additional complexity.
Methodology
Model Design
The authors propose a method utilizing a Siamese encoder model that accepts both images and sketches. During training, embeddings are matched on a batch level, aligning similarity matrices with a target one. In the inference stage, sketches and images are compared using cosine distance. This approach leverages pre-trained vision backbones, such as ConvNeXt, particularly because of its inductive biases towards local features crucial for capturing scene-level layouts.
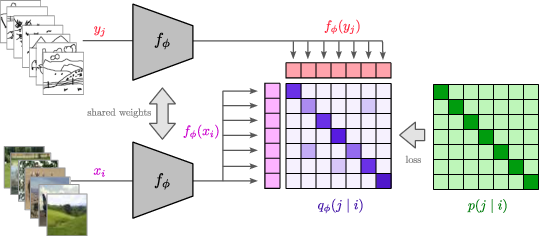
Figure 1: Overview of the proposed method. Our encoder model is trained in a Siamese manner, accepting both images and sketches.
Training Loss
The training process employs a contrastive learning setup that minimizes the Kullback-Leibler (KL) divergence between a learned and a supervised distribution, accounting for sketch ambiguity. This approach, identified as the Information Contrastive (ICon) framework, addresses the limitations of triplet loss, enhancing retrieval by adapting to noisy and ambiguous sketch queries.
Experimental Evaluation
The methodology was evaluated on challenging datasets like FS-COCO and SketchyCOCO. The proposed approach significantly outperformed existing methods, doubling the retrieval performance on FS-COCO with an R@1 of 61.9%, a result that also held on the unseen split for real-world deployment scenarios.

Figure 2: Qualitative results on the test split of the FS-COCO dataset.
Discussion
The advantages of the proposed method are evident in its efficiency, leveraging pre-trained models for better cross-modal alignment and its robustness to sketch variability. While the model focuses on sketch-to-image retrieval, it provides a foundation for future work that could incorporate richer multi-modal narratives and address partial or incomplete sketches. However, an emphasis on dataset improvements is necessary, as the results highlight the current datasets' limitations concerning semantic and scene-level ambiguities.
Conclusion
This study effectively explores a straightforward yet potent framework for scene-level SBIR, achieving remarkable improvements over existing state-of-the-art methods. By focusing on pre-training, architectural choices, and a novel training loss that ameliorates sketch ambiguity, this work sets a strong baseline for future endeavors in cross-modal retrieval, encouraging advancements in dataset constructions to accommodate the needs of realistic and diverse scene retrieval tasks.