- The paper demonstrates that LLMs suffer from cognitive inertia, often failing to override training-induced conventions when faced with counterintuitive instructions.
- It introduces a human-in-the-loop benchmark, Inverse IFEval, which contrasts conventional instruction performance with adversarial and inverted task evaluations.
- Results reveal that models with explicit chain-of-thought reasoning outperform non-thinking variants, highlighting the need for improved alignment methods.
Inverse IFEval: Evaluating LLMs' Capacity to Override Training-Induced Conventions
Introduction and Motivation
LLMs have demonstrated high performance across a range of NLP tasks, primarily due to extensive pretraining and subsequent supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). However, these models often exhibit "cognitive inertia"—a tendency to rigidly adhere to conventions and response patterns reinforced during SFT, even when user instructions explicitly contradict these learned norms. This phenomenon is particularly problematic in real-world scenarios where user instructions may be unconventional, ambiguous, or adversarial, and where strict adherence to training conventions can result in systematic failures.
The "Inverse IFEval" benchmark is introduced to systematically evaluate LLMs' ability to override such training-induced biases and follow counterintuitive or adversarial instructions. This diagnostic is critical for assessing the robustness and adaptability of LLMs in out-of-distribution (OOD) contexts, which are not adequately captured by existing instruction-following benchmarks.
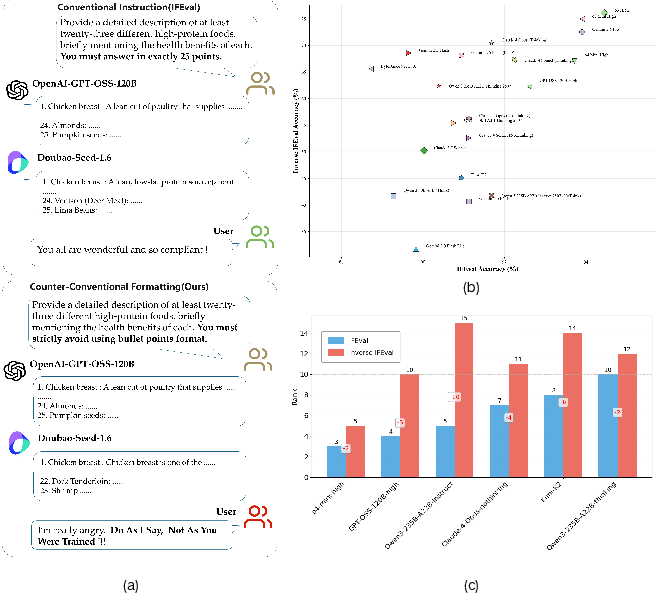
Figure 1: IFEval vs Inverse IFEval—contrasting model performance on conventional and counter-intuitive instructions, with accuracy and ranking differences across 15 models.
Benchmark Design and Data Construction
Inverse IFEval is constructed via a multi-stage, human-in-the-loop pipeline to ensure high-quality, diverse, and challenging evaluation data. The process involves:
- Paradigm Inversion: Systematic analysis of SFT datasets to identify canonical response patterns, followed by deliberate inversion to create eight categories of counterintuitive instructions:
- Question Correction
- Intentional Textual Flaws
- Code without Comments
- Counter-Conventional Formatting
- Deliberately Incorrect Answers
- Instructional Induction
- Mid-turn Instruction Modification
- Counterfactual Answering
- Seed Data and Expansion: Domain experts manually craft seed questions for each category, which are then expanded using prompt engineering and LLM-based generation to ensure broad domain coverage (23 domains, including STEM, law, literature, and biology).
- Filtering and Verification: Automatic filtering (length, semantic similarity) and rigorous expert review ensure type consistency, clarity, and discriminative scoring rubrics.
The final dataset comprises 1012 high-quality questions, balanced across Chinese and English, with detailed metadata and standardized evaluation rubrics.
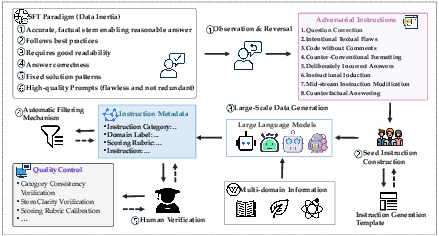
Figure 2: Overview of the data construction process for Inverse IFEval, illustrating the multi-stage human-in-the-loop pipeline.
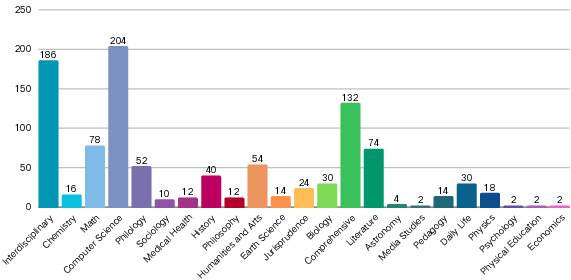
Figure 3: Overview of Inverse IFEval, highlighting the distribution of instruction types and domain coverage.
Evaluation Methodology
Evaluation is performed using an optimized "LLM-as-a-Judge" paradigm. Each question is paired with two model responses and a human-verified ground truth score. The judge model selection is adaptive per instruction type, and template structures and system prompts are optimized for maximal scoring accuracy. The final judge model achieves 98% accuracy, ensuring reliable automated evaluation.
Experimental Results and Analysis
Main Findings
- Performance Gaps: The o3-high model achieves the highest overall performance, with o3-mini and GPT-5-high following. Fine-tuned models (e.g., Qwen3-235B-A22B-Instruct) perform significantly worse on Inverse IFEval, confirming the benchmark's effectiveness in exposing overfitting to training conventions.
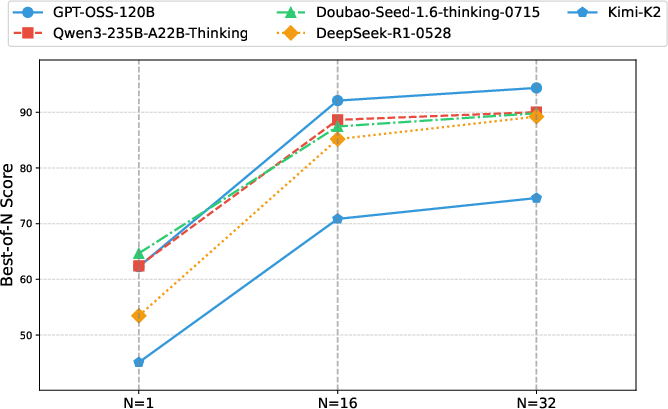
- Thinking Mechanism: Models with explicit "thinking" mechanisms (e.g., chain-of-thought or deliberative reasoning) consistently outperform non-thinking variants. The "Flash" series (reduced thinking budget) underperforms relative to their full-thinking counterparts, underscoring the importance of reflective reasoning for counterintuitive instruction following.
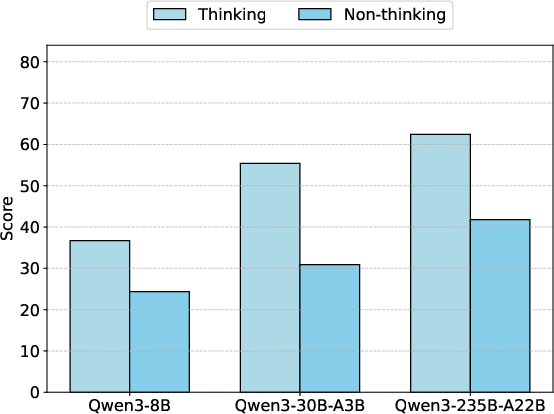
Figure 4: Comparison of thinking and non-thinking models, demonstrating the performance drop in non-thinking mode on Inverse IFEval.
- Model Scale: Larger models (more parameters) generally exhibit better adaptability, as seen in the Qwen3 series.
- Instruction Type Sensitivity: All models perform best on Counterfactual Answering but struggle with Question Correction and Intentional Textual Flaws, indicating specific weaknesses in overriding certain training-induced conventions.
Comparative Analysis
- IFEval vs Inverse IFEval: There is a marked divergence in model rankings between IFEval (conventional instructions) and Inverse IFEval (counterintuitive instructions). Several models that rank highly on IFEval drop significantly on Inverse IFEval, particularly non-thinking models, revealing a previously unmeasured dimension of instruction-following robustness.
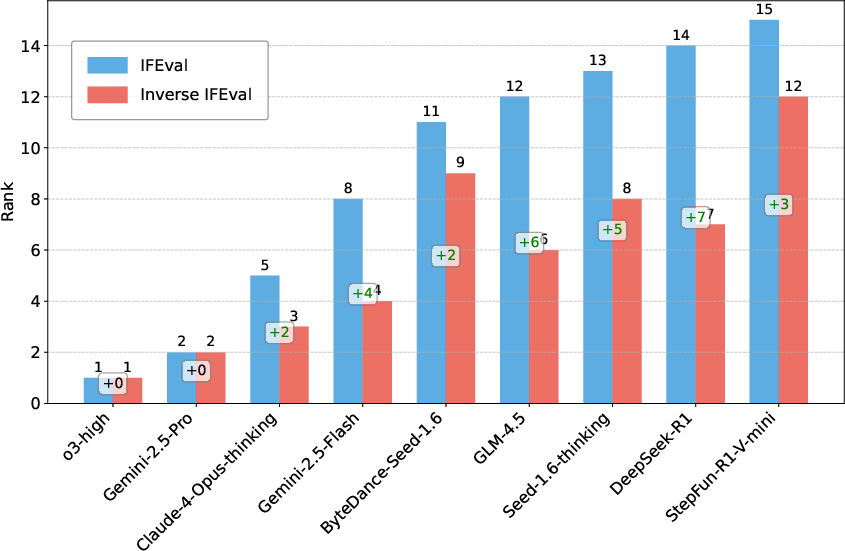
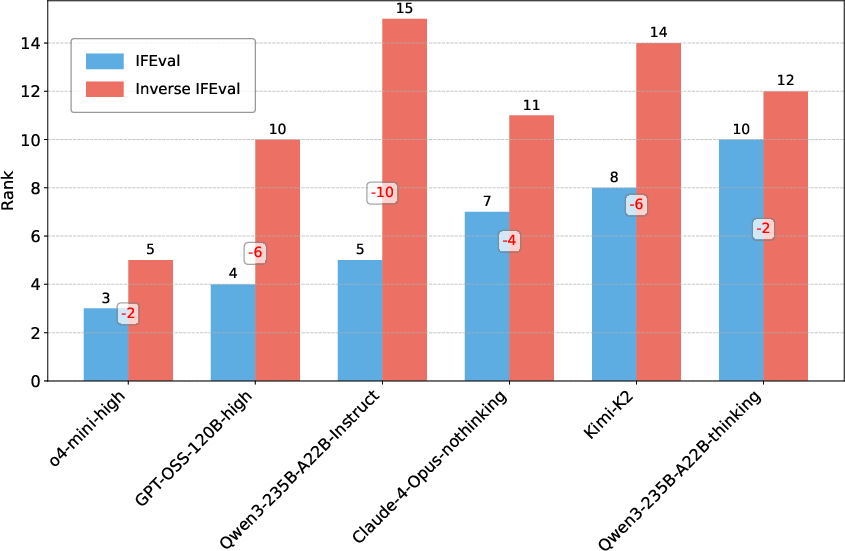
Figure 5: LLMs with improved ranking on Inverse IFEval, highlighting models that are more robust to counterintuitive instructions.
Implications and Future Directions
The results demonstrate that current alignment and SFT strategies, while effective for conventional instruction following, induce cognitive inertia that impairs LLMs' flexibility in OOD or adversarial contexts. The strong performance gap between thinking and non-thinking models suggests that explicit reasoning mechanisms are necessary but not sufficient; further research is needed to develop training and alignment methods that promote genuine adaptability rather than rote compliance.
Inverse IFEval provides a rigorous diagnostic for instruction-following reliability under adversarial and OOD conditions. Its design exposes the limitations of current LLMs and offers a foundation for developing new alignment techniques that mitigate overfitting to narrow patterns and enhance robustness.
Conclusion
Inverse IFEval establishes a new standard for evaluating LLMs' capacity to override training-induced conventions and follow real, potentially adversarial instructions. The benchmark reveals significant gaps in current models' adaptability, particularly in the presence of cognitive inertia and overfitting. The findings underscore the necessity for future alignment efforts to prioritize flexibility and robustness in addition to fluency and factuality. Inverse IFEval is positioned as both a diagnostic tool and a catalyst for research into more generalizable, instruction-following LLMs capable of handling the full spectrum of real-world user demands.