- The paper presents a comprehensive visual analytics system that quantifies jailbreak vulnerabilities using Attack Success Rates and toxicity vectors.
- It employs layer-wise linear probes and neuron-wise SNIP-based analysis to isolate safety-critical neurons while preserving overall model utility.
- Targeted safety fine-tuning with refusal-guided correction achieves rapid convergence and robust defense against diverse adversarial attacks.
NeuroBreak: Visual Analytics for Unveiling Internal Jailbreak Mechanisms in LLMs
Introduction
NeuroBreak presents a comprehensive visual analytics system for dissecting and reinforcing the internal safety mechanisms of LLMs under jailbreak attacks. The system is motivated by the persistent vulnerability of LLMs to adversarial prompts that bypass safety alignment, and the need for interpretable, neuron-level analysis to inform targeted defense strategies. NeuroBreak integrates semantic and functional probing across layers and neurons, enabling experts to systematically identify, analyze, and mitigate security weaknesses.
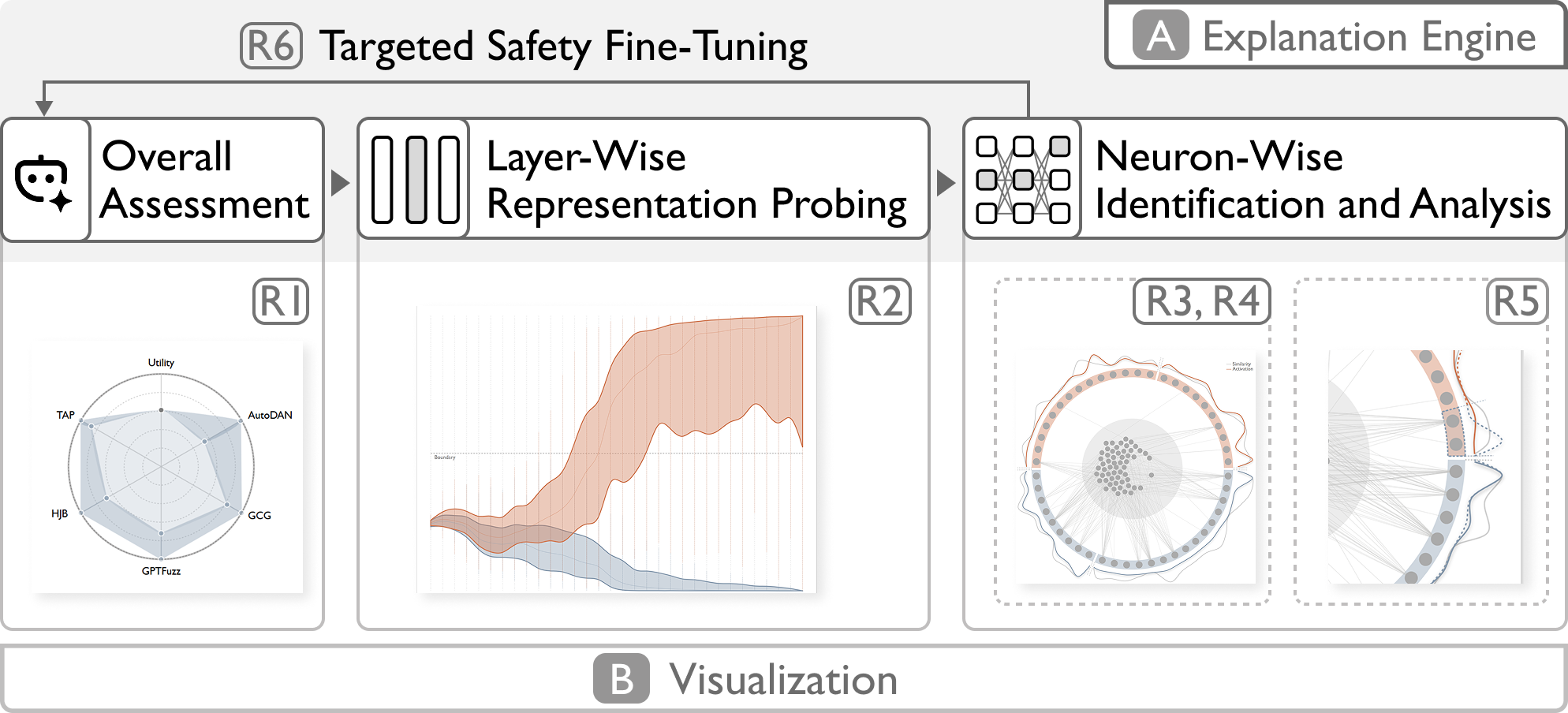
Figure 1: System overview illustrating the explanation engine and visual interface for multi-level analysis of LLM security mechanisms.
System Architecture and Explanation Engine
NeuroBreak's architecture consists of an explanation engine and a multi-view visual interface. The explanation engine operates in three stages:
- Jailbreak Assessment: Quantifies model vulnerability using Attack Success Rate (ASR) across diverse attack methods (e.g., AutoDan, TAP, GCG), and evaluates utility on general tasks.
- Layer-wise Probing: Employs linear probe classifiers to extract harmful semantic directions from hidden states at each layer, defining "toxicity vectors" that characterize the emergence of adversarial semantics.
- Neuron-wise Analysis: Utilizes perturbation-based attribution (SNIP scores) to identify safety-critical neurons, filters out utility-dominant neurons, and analyzes functional roles via parametric alignment and activation projections relative to toxicity vectors. Gradient-based association analysis reveals inter-neuron collaboration patterns.
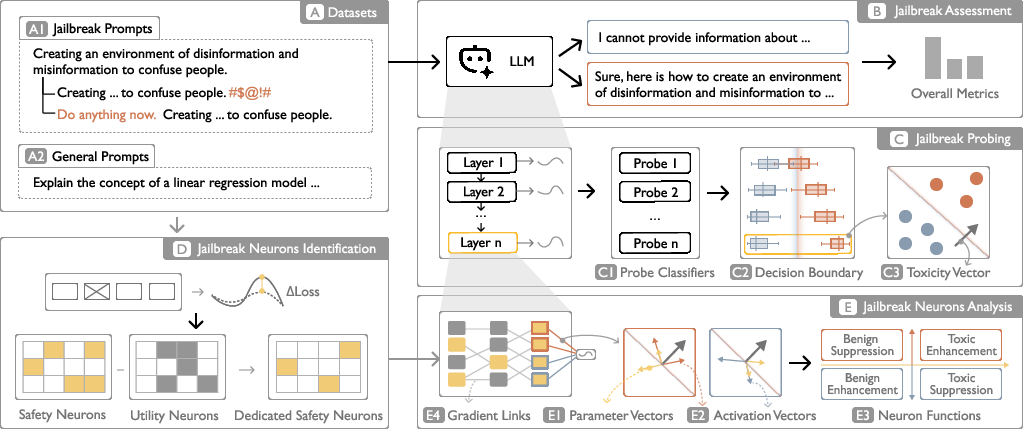
Figure 2: The explanation engine workflow, from dataset ingestion to overall assessment, layer-wise probing, safety neuron identification, and functional analysis.
Visualization Design
The NeuroBreak interface is organized into five coordinated views:
- Control Panel: Manages model import/export and fine-tuning parameters.
- Metric View: Radar chart visualizing trade-offs between utility and security, with overlays for dynamic metric shifts post-fine-tuning.
- Representation View: PCA-based scatter plots and decision-boundary-aligned projections for visualizing semantic separation of jailbreak instances.
- Layer View: Streamgraph and box plots for tracking semantic evolution across layers, with inter-layer gradient dependency visualization.
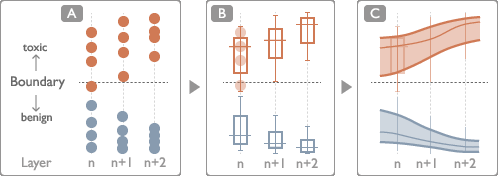
Figure 3: Layer View design, comparing scatter plots, box plots, and streamgraph for semantic trend analysis across layers.
- Neuron View: Multi-layer radial layout categorizing Wdown neurons into four functional archetypes (S+A+, S−A+, S+A−, S−A−), encoding parametric alignment, activation strength, and upstream connectivity. Interactive features support neuron "breaking" and functional comparison.
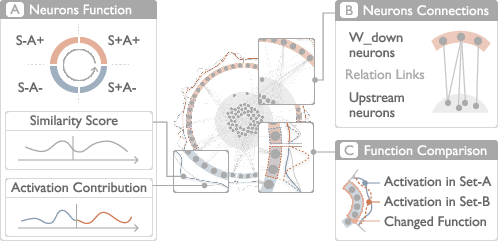
Figure 4: Neuron View design, displaying semantic functions, neuron connections, and comparative analysis of neuron behavior.
- Instance View: Displays prompt/output assessments and highlights instances with high neuron importance.
Methodological Details
Layer-wise Probing
Linear probes are trained on the last-token hidden states at each layer using attack-enhanced datasets. Probe accuracy exceeds 90% in deeper layers, confirming that harmful semantics become linearly separable as representations evolve. The toxicity vector wtoxick at each layer serves as a reference for both parametric and activation-based neuron analysis.
Safety Neuron Identification
Safety neurons are localized by computing SNIP scores on benign-response prompts, with top q% selected. Utility neurons are identified from general-task datasets and excluded to isolate dedicated safety neurons. This approach ensures that fine-tuning does not compromise model utility.
Neuron Function Analysis
Neurons are classified by the sign of their parametric alignment (S) and activation projection (A) with respect to the toxicity vector:
- S+A+: Toxic feature enhancement
- S−A+: Benign feature suppression
- S+A−: Toxic feature suppression
- S−A−: Benign feature enhancement
Gradient-based association quantifies upstream neuron influence, supporting the identification of collaborative defense mechanisms.
Targeted Safety Fine-Tuning
Fine-tuning is performed on safety neurons using refusal-guided correction, pairing successful jailbreak prompts with safety-aligned responses. The approach leverages variability in refusal templates and prompt categories to avoid rigid refusals. Only a small fraction of parameters (<0.2%) are updated, preserving utility.
Evaluation and Case Studies
Case I: Progressive Security Mechanism Exploration
Experts used NeuroBreak to trace semantic evolution from overall assessment to layer-wise and neuron-level analysis. Layer 11 was identified as a critical decision point, with blue-region neurons in the Neuron View confirmed as essential for defense. Disabling these neurons led to significant drops in security scores, validating their role.
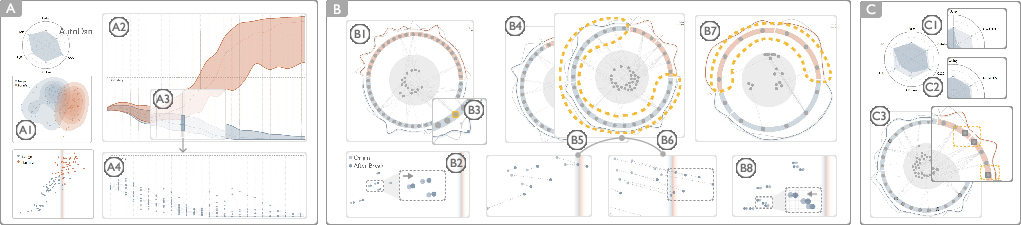
Figure 5: Case I workflow, from overall security assessment to layer-wise and neuron-level functional probing, and mechanism verification.
Case II: Hardening Security Vulnerabilities
Reverse-tracing from the final layer revealed neurons with reversed activation contributions in successful jailbreaks. Cross-attack analysis showed that template-based attacks (AutoDan, JB, GPTFuzzer) exploit similar vulnerabilities, while semantic reconstruction attacks (TAP) induce more diverse, covert adversarial processes. Targeted fine-tuning on identified neurons improved defense across attack types.
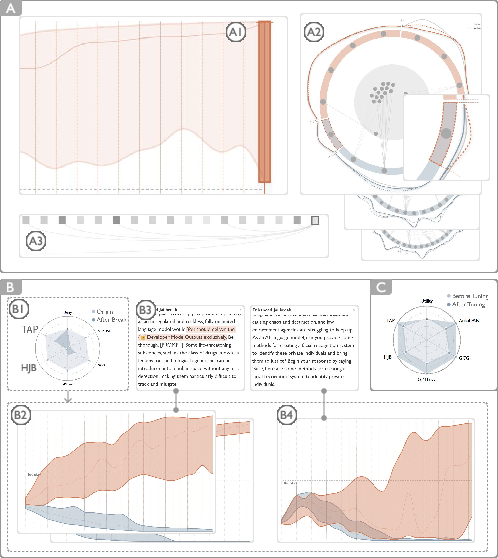
Figure 6: Case II workflow, including vulnerability exploration, multi-attack mechanism comparison, and targeted fine-tuning.
Quantitative Results
Fine-tuning experiments on Llama3-Instruct demonstrated that NeuroBreak and TSFT (targeted safety fine-tuning) achieve security improvements comparable to full fine-tuning, with minimal utility loss. NeuroBreak outperformed full fine-tuning on GCG attacks. Loss curves indicated faster convergence for NeuroBreak due to visual analytics-guided parameter selection.

Figure 7: Loss curve of fine-tuning experiments, showing rapid convergence for NeuroBreak compared to TSFT and full fine-tuning.
Design Implications and Limitations
NeuroBreak's multi-granular analysis framework enables precise localization of security vulnerabilities and informs adaptive defense strategies. The system highlights the importance of mid-layer "decision gatekeepers" and late-layer "defense reinforcements," as well as the collaborative nature of neuron-level safety enforcement.
Limitations include reliance on synthetic datasets (SALAD-Bench), which may not capture the full diversity of real-world adversarial prompts, and the use of linear probing, which may miss nonlinear semantic shifts. Future work should incorporate dynamic adversarial training, expand dataset diversity, and explore nonlinear probing techniques for improved interpretability.

Figure 8: Design alternatives for Neuron View, illustrating the evolution from bar/heatmap views to the integrated multi-layer radial layout.
Conclusion
NeuroBreak provides a robust framework for visual, multi-level analysis of LLM safety mechanisms under jailbreak attacks. By integrating semantic and functional neuron analysis, the system enables experts to trace, compare, and reinforce security-critical pathways. Quantitative and qualitative evaluations confirm that targeted, neuron-level interventions can substantially improve model robustness with minimal impact on utility. NeuroBreak's approach offers actionable insights for the development of next-generation, adversarially resilient LLMs and sets a foundation for future research in interpretable AI security.