- The paper introduces LuxDiT, a conditional generative framework using a video diffusion transformer to estimate HDR environment maps from images and video input.
- It leverages large-scale synthetic pretraining and LoRA-based fine-tuning, achieving superior angular accuracy and temporal consistency compared to prior methods.
- Experimental results show reduced peak angular error and improved virtual object insertion quality, validating the method's state-of-the-art performance.
Introduction and Motivation
Lighting estimation from casually captured images or videos is a fundamental problem in computer vision and graphics, underpinning photorealistic rendering, AR, and virtual object insertion. The core challenge is to infer a high-dynamic-range (HDR) environment map that accurately represents scene illumination, including directionality, intensity, and semantic consistency. Existing learning-based approaches are constrained by the scarcity of paired datasets with ground-truth HDR maps, and generative models such as GANs and diffusion models have not fully addressed the non-local, indirect nature of lighting cues. LuxDiT introduces a conditional generative framework leveraging a video diffusion transformer (DiT) architecture, trained on large-scale synthetic data and adapted to real-world scenes via LoRA-based fine-tuning.

Figure 1: LuxDiT is a generative lighting estimation model that predicts high-quality HDR environment maps from visual input. It produces accurate lighting while preserving scene semantics, enabling realistic virtual object insertion under diverse conditions.
Methodology
Architecture
LuxDiT formulates HDR environment map estimation as a conditional denoising task. The model is built on a transformer-based diffusion backbone (CogVideoX), operating in a latent space for computational efficiency. The input is a single image or video, encoded via a pretrained VAE. The output is a sequence of 360∘ HDR panoramas, represented by two complementary tone-mapped LDR images: Reinhard and log-intensity mappings. These are encoded, concatenated, and processed jointly with the visual input tokens in the DiT via self-attention, with adaptive layer normalization distinguishing condition and denoising tokens.
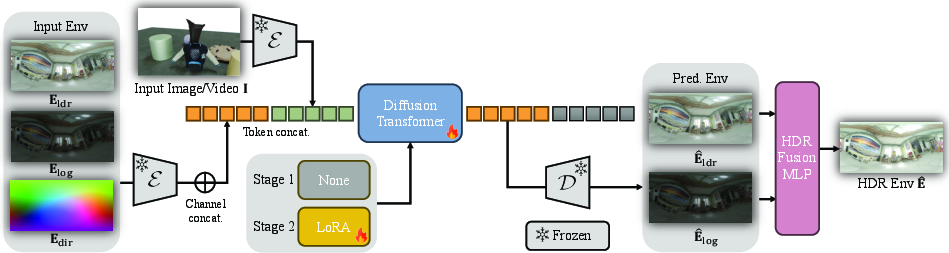
Figure 2: Method overview: LuxDiT predicts an environment map as two tone-mapped representations, guided by a directional map, encoded and fused by a lightweight MLP to reconstruct the final HDR panorama.
Directional information is injected via a direction map encoding per-pixel lighting directions, promoting angular continuity and rotational equivariance. Conditioning is fully attention-based, eschewing pixel-aligned concatenation, which empirically degrades performance for non-local tasks.
Data Strategy
Training leverages three sources:
- Synthetic renderings: Randomized 3D scenes with diverse geometry, materials, and lighting, rendered with physically accurate cues.
- HDR panorama images: Perspective crops from curated HDR panoramas, with randomized camera parameters and exposure.
- LDR panoramic videos: Perspective crops from panoramic videos, augmenting robustness and temporal consistency.
Training Scheme
A two-stage process is employed:
- Stage I: Supervised training on synthetic data, learning physically grounded relationships between shading cues and HDR lighting.
- Stage II: LoRA-based fine-tuning on real-world data, improving semantic alignment and generalization.
Experimental Results
Image Lighting Estimation
LuxDiT is evaluated on Laval Indoor, Laval Outdoor, and Poly Haven benchmarks. Metrics include scale-invariant RMSE, angular error, and normalized RMSE. On Laval Indoor, LuxDiT matches or surpasses DiffusionLight, despite not using this dataset for training, demonstrating strong out-of-domain generalization. On outdoor datasets, LuxDiT consistently outperforms prior methods, especially in capturing high-intensity sources and angular details.












Figure 3: Qualitative comparison with baseline methods on three benchmark datasets.
Peak angular error on sunlight direction is reduced by nearly 50% compared to DiffusionLight, indicating superior directional accuracy.
Video Lighting Estimation
LuxDiT supports video input, producing temporally consistent HDR maps. On PolyHaven-Peak and WEB360 video benchmarks, LuxDiT achieves lower mean angular error and significantly reduced temporal variance compared to frame-wise inference and DiffusionLight.






Figure 4: Qualitative comparison of video lighting estimation.
Virtual Object Insertion
LuxDiT enables realistic virtual object insertion, evaluated via quantitative metrics and user studies. It achieves comparable or better RMSE and SSIM than specialized baselines (DiPIR, StyleLight, DiffusionLight), with users preferring LuxDiT results in over 60% of cases.










Figure 5: Qualitative comparison of virtual object insertion.
Ablation Studies
- Model design: Token-level conditioning and synthetic pretraining are critical; channel concatenation and omission of synthetic data degrade performance.
- LoRA scale: Increasing LoRA weight improves semantic alignment and reduces angular error on real images, but degrades accuracy on synthetic foreground objects, indicating a trade-off between domain adaptation and generalization.
- Camera sensitivity: Performance is robust to moderate variations in field of view and elevation.











Figure 6: Model design ablation and LoRA scale exploration.











Figure 7: Lighting estimation from input images with varying camera FOV.










Figure 8: Lighting estimation from input images with varying camera elevation.
Implementation Details
- Backbone: Pretrained CogVideoX-5b-I2V, fine-tuned with LoRA (rank 64) on 16 A100 GPUs.
- Input/output resolution: 512×512 to 480×720 for input, 128×256 to 256×512 for output.
- Batch size: 192 for images, 48 for videos.
- MLP fusion: 5 layers, 64 units, LeakyReLU, softplus output for HDR reconstruction.
- Data augmentation: Random camera parameters, tone-mapping, exposure, and quantization.
Limitations and Future Directions
LuxDiT's inference is computationally intensive due to the iterative nature of diffusion models, limiting real-time deployment. Resolution is constrained by training scale and data diversity. Future work should explore model distillation, efficient architectures, and richer HDR supervision for higher-resolution outputs. Joint modeling of lighting, geometry, and material is a promising direction for unified inverse and forward rendering frameworks.
Conclusion
LuxDiT advances HDR lighting estimation by integrating transformer-based diffusion modeling, large-scale synthetic pretraining, and LoRA-based semantic adaptation. It achieves state-of-the-art performance in both quantitative and qualitative evaluations, supporting robust, scene-consistent lighting prediction for images and videos. The approach is extensible to downstream tasks such as virtual object insertion, relighting, and AR, and provides a foundation for future research in unified scene reconstruction and appearance synthesis.

