- The paper introduces AESA-Net, leveraging triplet loss and self-supervised BEATs embeddings to enhance multi-axis perceptual audio assessment.
- It employs a multi-branch LSTM architecture with adaptive attention and buffer-based triplet sampling to mitigate domain shifts between natural and synthetic audio.
- Results show improved SRCC and KTAU metrics over baselines, demonstrating effective ordinal alignment and robust quality ranking for generative audio systems.
Improving Perceptual Audio Aesthetic Assessment via Triplet Loss and Self-Supervised Embeddings
Introduction
This paper addresses the challenge of automatic multi-axis perceptual quality prediction for generative audio, specifically within the context of the AudioMOS Challenge 2025. The task involves predicting four Audio Aesthetic Scores—Production Quality (PQ), Production Complexity (PC), Content Enjoyment (CE), and Content Usefulness (CU)—for audio generated by text-to-speech (TTS), text-to-audio (TTA), and text-to-music (TTM) systems. A central difficulty is the domain shift between natural audio used for training and synthetic audio encountered during evaluation. The proposed solution leverages BEATs, a transformer-based self-supervised audio representation model, in conjunction with a multi-branch LSTM-based architecture and a triplet loss with buffer-based sampling to enforce perceptual structure in the embedding space.
System Architecture
The model, termed AESA-Net (Audio Aesthetics Assessment Network), is designed as a unified multi-task system to jointly predict all four perceptual axes. The architecture consists of a shared backbone for feature extraction and encoding, followed by task-specific heads for each axis. The input audio is resampled to 16 kHz and processed by BEATs, which outputs hidden states from all transformer layers. These are combined via a learnable weighted sum, normalized by softmax, to form the input feature sequence.
The backbone comprises an adapter layer (linear projection), a two-layer bidirectional LSTM (BLSTM) for temporal modeling, and a shared linear layer with dropout and activation. Each perceptual axis is modeled by a dedicated branch containing a multi-head self-attention layer, a frame-level scoring layer (linear + sigmoid), and adaptive average pooling for clip-level aggregation. The final outputs are four normalized scores in the [0, 1] range.
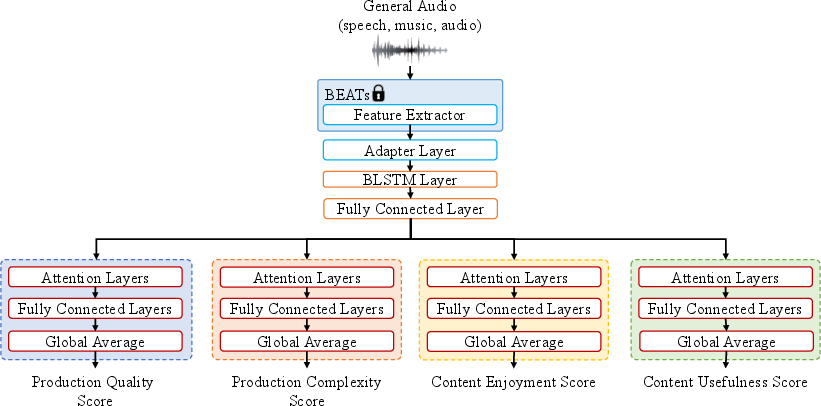
Figure 1: System Architecture of AESA-Net, illustrating the shared backbone and four axis-specific branches for PQ, PC, CE, and CU.
Triplet Loss with Buffer-Based Sampling
To address the domain shift and improve generalization to synthetic audio, the model incorporates a triplet loss applied to intermediate embeddings. A memory buffer B stores recent embedding-score pairs (zi,yi), where yi is the normalized ground-truth score. For each anchor embedding za, a positive sample zp (with similar score) and a negative sample zn (with dissimilar score) are selected from the buffer based on a threshold ϵ. The triplet loss is computed as:
LTriplet=max(∥za−zp∥22−∥za−zn∥22+margin, 0)
This loss encourages the model to structure the latent space such that perceptually similar audio samples are close together, while dissimilar samples are separated. The total loss for backpropagation is a weighted sum of mean squared error (MSE) and triplet loss:
Ltotal=LMSE+α⋅LTriplet
where α is a hyperparameter controlling the contribution of the triplet loss.
Experimental Setup
The AES-natural dataset, comprising 2,950 natural audio samples across speech, music, and general audio domains, was used for training and validation. Each sample was rated by 10 expert listeners on the four axes, with the mean normalized score serving as the training target. The evaluation set consisted of 3,000 synthetic samples from TTS, TTA, and TTM systems, inaccessible during training. The model was trained using Adam with a learning rate of 1×10−4, batch size 1, and early stopping based on validation MSE.
Results
System-level performance was evaluated using MSE, LCC (Pearson), SRCC (Spearman), and KTAU (Kendall's Tau) metrics. The model demonstrated strong generalization to synthetic audio, particularly in music and general audio domains. Notably, high SRCC and KTAU values for PC indicate robust rank-based consistency. The triplet loss contributed to improved ordinal alignment with human ratings, as evidenced by higher SRCC and KTAU compared to the official baseline.
For PQ and CU, the model achieved higher SRCC and KTAU than the baseline, indicating better ranking of perceptual quality. Although the MSE for CE was higher than the baseline, the model yielded superior correlation metrics, suggesting more accurate ranking despite deviations in absolute score values. These results validate the effectiveness of the triplet loss and buffer-based sampling in mitigating domain shift and enhancing generalization.
Implementation Considerations
- Feature Extraction: BEATs provides robust, unified representations for both speech and non-speech audio. The learnable weighted sum of transformer layers allows the model to adaptively select relevant features for each axis.
- Model Architecture: The multi-branch design enables joint modeling of multiple perceptual axes, with shared temporal encoding and axis-specific attention mechanisms.
- Loss Function: The combination of MSE and triplet loss enforces both accurate regression and perceptual structure in the embedding space.
- Training Strategy: Buffer-based triplet sampling is critical for effective triplet loss optimization, especially with limited batch sizes and variable-length inputs.
- Resource Requirements: The use of BEATs and BLSTM layers incurs moderate GPU memory usage, necessitating batch size 1 for long audio clips.
- Deployment: The model can be deployed for real-time or batch evaluation of generative audio systems, with potential extension to listener-dependent modeling or fusion with speech-specific SSL models.
Implications and Future Directions
The proposed approach demonstrates that triplet loss, when combined with self-supervised embeddings, can significantly improve the generalization of perceptual audio assessment models to unseen synthetic domains. This has practical implications for automatic evaluation of generative audio systems, enabling reliable quality prediction without requiring synthetic training data. Theoretically, the work highlights the importance of embedding space structuring for domain robustness.
Future research may explore:
- Integration of speech-specific SSL models (e.g., WavLM) with BEATs for improved speech segment modeling.
- Listener-dependent modeling to capture individual perceptual tendencies.
- Extension to additional perceptual axes or multimodal assessment.
- Optimization of buffer sampling strategies for large-scale or streaming applications.
Conclusion
This paper presents a unified multi-axis perceptual audio assessment model that leverages triplet loss and self-supervised embeddings to address domain shift between natural and synthetic audio. The AESA-Net architecture, combined with buffer-based triplet sampling, achieves strong rank-based and correlation-based performance on synthetic evaluation data, validating its effectiveness for robust, domain-agnostic audio aesthetic assessment. The approach provides a foundation for future developments in automatic evaluation of generative audio systems and perceptual modeling.

