- The paper introduces a challenge framework that advances automatic prediction of human-perceived quality in synthetic audio.
- The framework comprises three distinct tracks evaluating text-to-music, multi-axis perceptual quality, and multi-condition speech synthesis using advanced SSL models and ensemble techniques.
- The study demonstrates that integrating innovative architectures, multi-input features, and human-centric evaluation metrics significantly improves alignment with human judgments.
The AudioMOS Challenge 2025: Advancing Automatic Subjective Quality Prediction for Synthetic Audio
Introduction
The AudioMOS Challenge 2025 represents a significant expansion of the VoiceMOS Challenge series, targeting the automatic prediction of subjective quality for synthetic audio across speech, music, and general audio. The challenge addresses the limitations of current evaluation metrics—such as Fréchet Audio Distance (FAD) and CLAP Score—which have been shown to correlate poorly with human perception, especially in text-to-music (TTM) and text-to-audio (TTA) tasks. By providing annotated datasets and standardized evaluation protocols, the challenge aims to catalyze the development of models that more accurately reflect human judgments of audio quality.
Challenge Structure and Datasets
The challenge was organized into three tracks, each focusing on a distinct aspect of synthetic audio evaluation:
- Track 1: MOS prediction for TTM systems using the MusicEval dataset, with expert ratings on both overall musical quality and textual alignment.
- Track 2: Prediction of four perceptual axes (Production Quality, Production Complexity, Content Enjoyment, Content Usefulness) from the Meta Audiobox Aesthetics framework, evaluated on synthetic speech, music, and sound.
- Track 3: MOS prediction for synthesized speech at varying sampling rates, with a focus on generalization across conditions.
Each track provided carefully curated datasets, with robust quality control in subjective ratings. Notably, Track 1 leveraged expert annotators for nuanced musical judgments, while Track 2 utilized a large pool of trained annotators with stringent qualification criteria. Track 3 introduced a multi-condition evaluation, reflecting real-world deployment scenarios where sampling rates and synthesis methods vary.
Baseline Systems and Evaluation Metrics
Baseline systems for each track were constructed using state-of-the-art self-supervised learning (SSL) models:
- Track 1: A CLAP-based model with HTSAT audio and RoBERTa text encoders, using MLP regression heads for dual-axis prediction.
- Track 2: A WavLM-based model with MLP blocks for each perceptual axis, trained on a large in-house dataset.
- Track 3: An SSL-MOS model fine-tuned on the provided listening tests, with all audio downsampled to 16 kHz.
Evaluation was primarily based on system-level Spearman rank correlation coefficient (SRCC), reflecting the importance of system ranking in generative audio evaluation. Additional metrics included MSE, LCC, and Kendall's Tau, computed at both utterance and system levels.
Results and Analysis
Track 1: Text-to-Music MOS Prediction
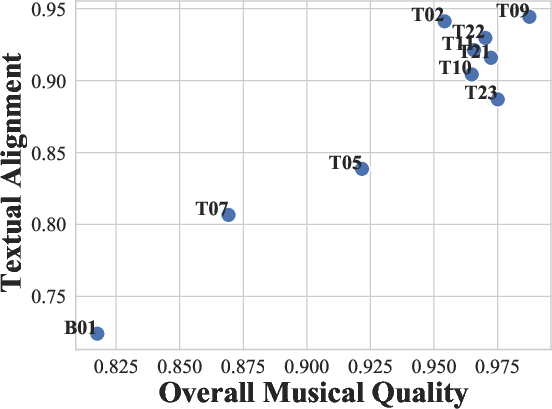
Figure 1: System-level SRCC values for all participants in Track 1, highlighting the performance gap between the baseline and top systems.
Track 1 results demonstrated substantial improvements over the baseline, with the top system (T09) surpassing the baseline by 20.8% (musical quality) and 30.4% (textual alignment) in system-level SRCC. The leading systems employed advanced SSL representations (MuQ, RoBERTa), cross-modal attention mechanisms, and ensemble learning. A notable observation was the consistent difficulty in modeling textual alignment compared to musical quality, underscoring the challenge of cross-modal semantic evaluation.
Track 2: Multi-Axis Perceptual Quality Prediction
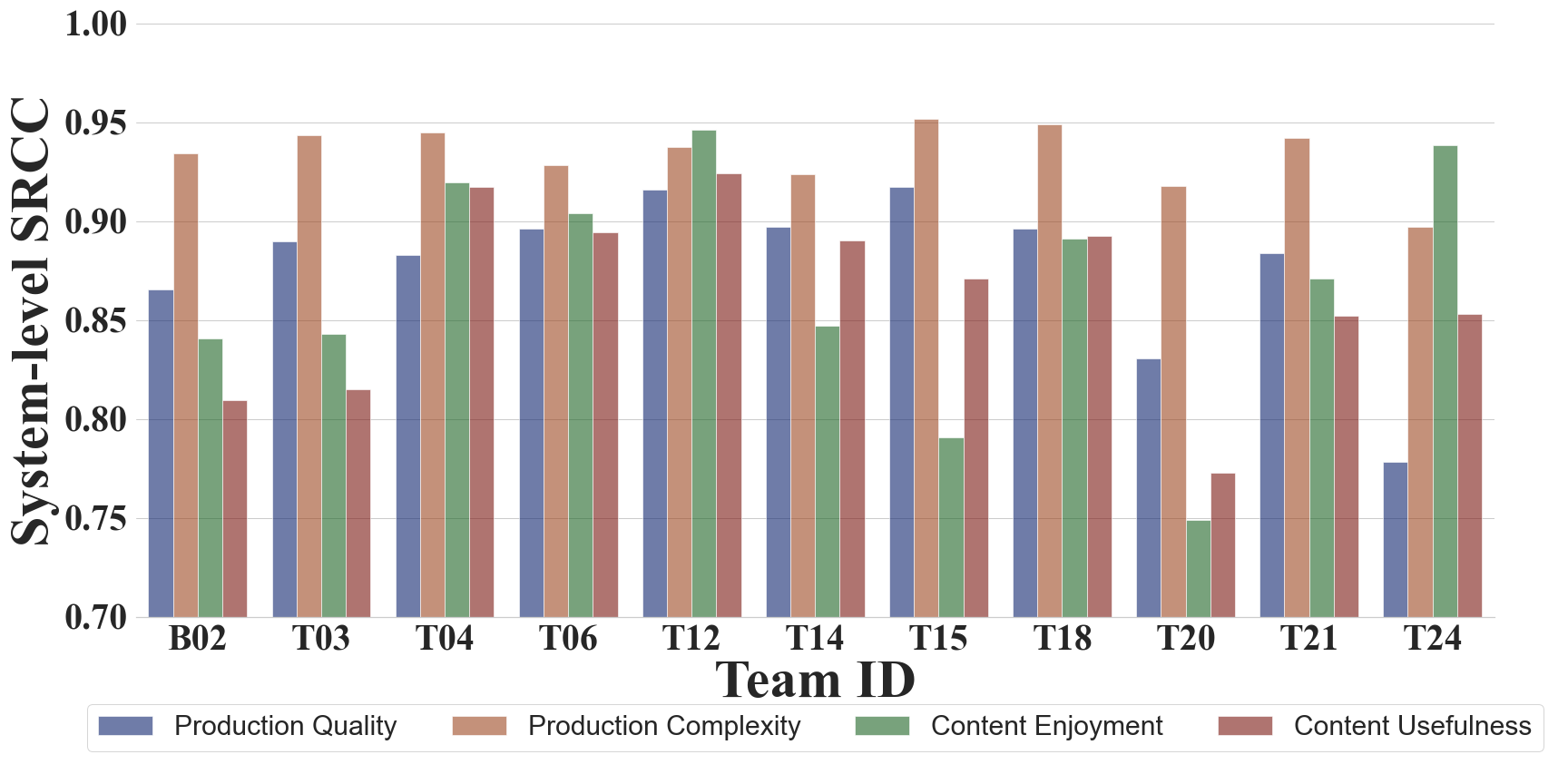
Figure 2: System-level SRCC values for all participants in Track 2 across the four Audiobox Aesthetics axes.
Most teams outperformed the baseline, despite the latter being trained on a substantially larger dataset. The top system (T12) achieved first place on 17 out of 32 metrics, leveraging model ensembling, advanced architectures (GR-KAN), and semi-supervised learning with additional datasets (PAM, BVCC). The lack of a single system dominating all axes suggests that the perceptual dimensions are partially decoupled and may require specialized modeling strategies. Importantly, the results indicate that scaling up training data alone does not guarantee superior performance, challenging prevailing assumptions in large-scale SSL.
Track 3: MOS Prediction Across Sampling Rates
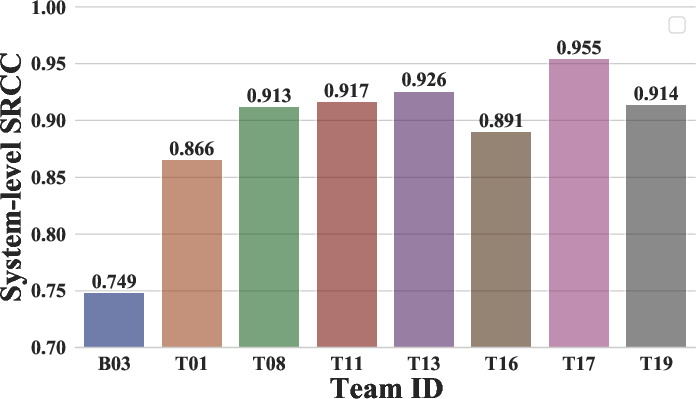
Figure 3: System-level SRCC values for all participants in Track 3, illustrating the impact of sampling rate and synthesis condition on prediction difficulty.
Track 3 revealed that 16 kHz conditions were consistently the most challenging to predict, both in terms of ranking and absolute score errors. The most difficult conditions included super-resolutioned 24 kHz speech and neural vocoded speech at 16 kHz. The top system (T17) integrated multiple input features (SSL, Mel-spectrogram, MFCC, sampling rate ID) and multi-scale convolutional processing, achieving robust generalization across conditions. Ensemble learning again proved critical for top performance.
System Design Insights
Analysis of system description forms revealed several key trends:
- Data Utilization: Most teams relied solely on the provided datasets due to the scarcity of compatible annotated data. Only a minority incorporated external datasets (PAM, BVCC, EARS) for pre-training or semi-supervised learning.
- SSL Models: CLAP, WavLM, wav2vec 2.0, and general audio encoders (Qwen-Audio, BEATs, M2D, EnCodec, Dasheng) were widely adopted. Track 1 systems also explored music-specific SSL models (MERT, MuQ) and text encoders (BERT, RoBERTa).
- Input Features: Top systems combined multiple SSL representations, traditional features (Mel-spectrogram, MFCC), and meta-information (sampling rate ID). Dynamic weighting and attention mechanisms were used to fuse heterogeneous inputs.
- Architectures: Modern architectures such as KANs, Mamba2, and sampling frequency independent convolutions were explored. Cross-modal attention and stacking-based ensemble learning were common among top performers.
- Training Objectives: A diverse set of loss functions was employed, including smoothed cross-entropy, rank-consistent ordinal regression, triplet loss, Sinkhorn optimal transport, and correlation-based losses.
- Ensembling: Model ensembling was a consistent feature of top systems across all tracks, with strong correlation to final performance.
Implications and Future Directions
The AudioMOS Challenge 2025 provides several important takeaways for the field:
- Human-Centric Evaluation: Direct learning from human ratings, rather than proxy metrics, is essential for progress in generative audio evaluation, especially for modalities with high semantic variability (e.g., TTM, TTA).
- Model Architecture: The integration of advanced SSL models, cross-modal attention, and ensemble learning is currently the most effective paradigm for subjective quality prediction.
- Data Scarcity: The lack of large, high-quality, multi-dimensional annotated datasets remains a bottleneck. The challenge datasets represent a valuable resource, but further expansion—especially for music and general audio—is needed.
- Metric Development: The observed decoupling of perceptual axes and the difficulty in modeling cross-modal alignment highlight the need for more sophisticated, task-specific evaluation metrics.
- Generalization: Robustness across sampling rates and synthesis conditions is critical for real-world deployment. Multi-condition training and explicit modeling of meta-information (e.g., sampling rate) are effective strategies.
Future research should focus on expanding annotated datasets, developing more interpretable and generalizable models, and exploring real-time and preference-based evaluation frameworks. There is also a clear demand for evaluation tasks covering a broader range of audio types and perceptual dimensions.
Conclusion
The AudioMOS Challenge 2025 has established new benchmarks and best practices for automatic subjective quality prediction in synthetic audio. The challenge results demonstrate that advanced SSL representations, modern architectures, and ensemble learning are key to achieving high correlation with human judgments. The datasets, evaluation protocols, and system insights provided by the challenge will serve as a foundation for future research in audio generation evaluation, with implications for both academic and industrial applications.

