- The paper introduces a novel Fourier-based kernel regression method using NUFFT operations to achieve O(n log n) complexity on GPUs.
- It demonstrates minimax optimal convergence rates for Sobolev, physics-informed, and additive models with rigorous theoretical guarantees.
- Empirical results validate the method's scalability and efficiency on massive datasets, outperforming traditional approaches in both runtime and memory usage.
Introduction and Motivation
This paper presents a unified framework for scalable kernel regression, leveraging Fourier representations and non-uniform fast Fourier transforms (NUFFT) to achieve O(nlogn) complexity for both time and memory. The approach is instantiated for three classes of models: Sobolev kernel regression, physics-informed regression, and additive models. The framework is designed to fully exploit GPU acceleration, enabling exact kernel learning on datasets with up to tens of billions of samples, a regime previously inaccessible to classical kernel methods due to their cubic complexity in n.
Fourier-Based Kernel Regression and Computational Acceleration
The core innovation is the use of truncated Fourier bases to represent functions in the RKHS, reducing the kernel regression problem to a finite-dimensional linear system. The design matrix Φ is constructed from the truncated Fourier basis, and the empirical risk minimization is performed over the parameter vector θ:
θ^=argθ∈CDmin(n−1∥Φθ−Y∥22+λ∥Mθ∥22)
where M encodes the kernel norm. The key computational bottlenecks—computation of Φ∗Φ and Φ∗Y—are recast as NUFFT operations, which are highly parallelizable and efficiently implemented on GPUs. The covariance matrix exhibits a block Toeplitz structure, further enabling fast matrix-vector products via FFTs.
This approach yields exact solutions (not approximations) for a broad class of kernels, in contrast to Nyström or random feature methods, which introduce additional approximation error and complicate theoretical analysis.
Statistical Guarantees and Minimax Rates
The framework is rigorously analyzed under standard nonparametric regression assumptions, with the target function f⋆ in a Sobolev space Hs(Ω). The estimator achieves the minimax optimal rate:
E[∥fθ^−f⋆∥L2(PX)2]=O(n−2s/(2s+d))
for appropriate choices of the truncation level m and regularization parameter λ. The analysis covers both standard Sobolev kernel regression and a low-bias variant that penalizes the unweighted ℓ2 norm of the coefficients, mitigating the regularization bias associated with high-order Sobolev norms.
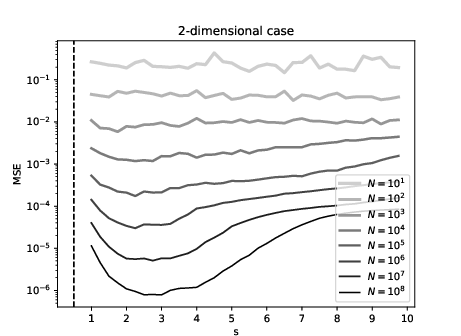
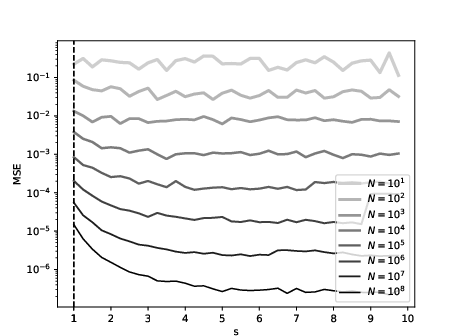
Figure 1: Sobolev regression (Left), and low-bias regression (Right) in dimension d=2.
Empirical results confirm that the observed test error closely matches the theoretical minimax rate, even for n=1010, with GPU runtimes on the order of one minute.
Low-Bias Sobolev Regression: Bias-Variance Trade-off
The paper highlights a critical trade-off in the choice of the smoothness parameter s. While higher s yields faster asymptotic rates, the associated Sobolev norm can grow rapidly, increasing regularization bias. The low-bias variant, which uses an unweighted ℓ2 penalty, consistently outperforms the standard Sobolev kernel in finite-sample regimes, especially for large s and moderate n. The optimal s in practice is often lower than the theoretical smoothness of f⋆, and increases with n.
The framework naturally extends to physics-informed machine learning (PIML), where prior knowledge is encoded as linear PDE constraints. The penalty term ∫ΩD(fθ,x)2dx is efficiently incorporated in the Fourier domain, as differential operators act diagonally on Fourier coefficients. The resulting estimator remains amenable to NUFFT acceleration and GPU implementation, with no increase in asymptotic complexity.
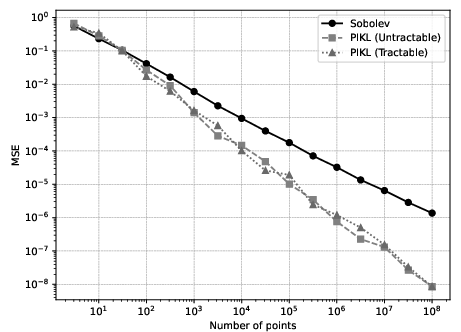
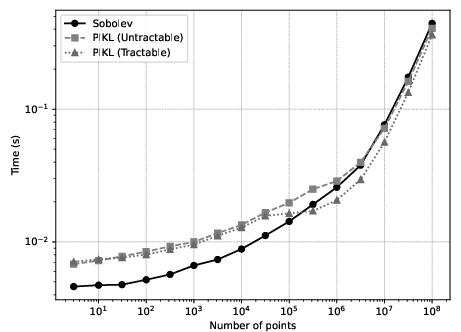
Figure 2: Physics-informed kernel regression (averaged over 20 samples).
Empirical results demonstrate that incorporating physics-based constraints improves predictive accuracy without increasing computational cost.
Additive Models and High-Dimensional Scalability
To address the curse of dimensionality, the framework supports additive models, where f⋆(x)=∑ℓ=1dgℓ⋆(xℓ). The additive structure allows the estimator to achieve the univariate minimax rate n−2s/(2s+1), independent of d, provided the component functions are sufficiently smooth. The block structure of the design and covariance matrices is exploited for efficient computation, and the method remains fully GPU-compatible.
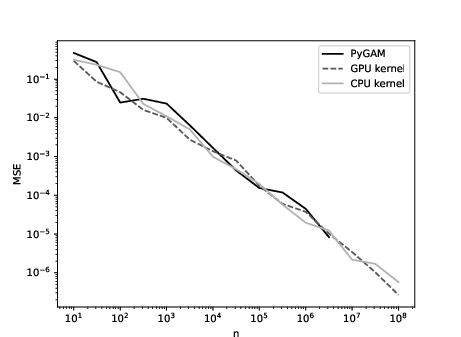
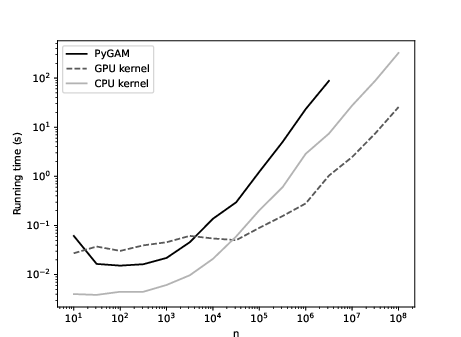
Figure 3: Additive model with d=5.
The additive kernel estimator outperforms spline-based GAMs (e.g., PyGAM) in both runtime and memory usage, especially as n increases. The GPU implementation remains tractable for n=108, while PyGAM exceeds available memory at n=107.
Hyperparameter Selection and Grid Search
A notable practical advantage is that the most expensive step is the NUFFT computation, which is independent of the regularization parameter λ. This enables efficient grid search over λ for model selection, as the matrix inversion step is comparatively cheap.
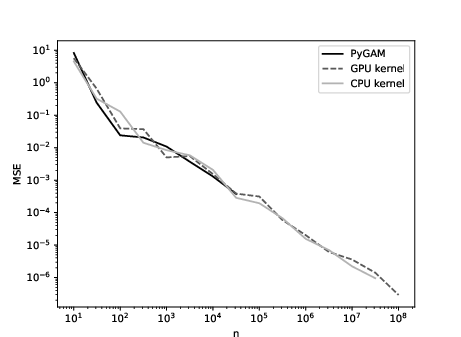
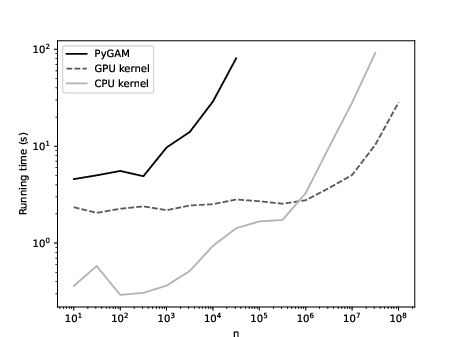
Figure 4: Grid search with 300 hyperparameters for the additive model with d=5.
The GPU-based kernel implementation completes a 300-point grid search in under 30 seconds for n=108, while PyGAM becomes infeasible for n≥105.
Implications and Future Directions
This work demonstrates that exact kernel methods can be made practical for massive datasets and high-dimensional problems, provided the kernel admits a Fourier representation. The approach is flexible, supporting a range of structural constraints (smoothness, PDEs, additivity) and is compatible with modern hardware. Theoretical guarantees are preserved, and empirical results confirm both statistical and computational efficiency.
Potential future directions include extending the framework to non-Euclidean domains, exploring non-stationary or data-adaptive bases, and integrating with deep kernel learning architectures. The ability to efficiently incorporate complex prior knowledge (e.g., via PDEs or shape constraints) opens new avenues for scientific machine learning and large-scale structured regression.
Conclusion
The paper establishes a unified, scalable, and theoretically sound framework for kernel regression, leveraging Fourier-NUFFT acceleration and GPU hardware. The methods achieve minimax optimal rates for Sobolev, physics-informed, and additive models, and are empirically validated on datasets of unprecedented scale. This work significantly broadens the applicability of kernel methods to modern large-scale learning tasks, while maintaining rigorous statistical guarantees.