- The paper introduces MoSEs, a framework that combines a stylistics reference repository, a stylistics-aware router, and a conditional threshold estimator to detect AI-generated texts.
- Experimental results show that MoSEs improves detection accuracy by an average of 11.34% and up to 39.15% in low-resource scenarios compared to traditional methods.
- The approach utilizes semantic embeddings and adaptive thresholds to capture nuanced stylistic variations, setting a new standard for reliable AI-generated text detection.
MoSEs: Uncertainty-Aware AI-Generated Text Detection via Mixture of Stylistics Experts
Introduction
The paper "MoSEs: Uncertainty-Aware AI-Generated Text Detection via Mixture of Stylistics Experts with Conditional Thresholds" (2509.02499) addresses the pressing need for reliable detection systems for AI-generated texts, which have become increasingly prevalent with the rise of sophisticated LLMs such as GPT-4 and LLaMA. These models have the capability to produce content that closely mimics human writing, raising concerns about potential misuse in contexts such as fake news and academic misconduct. Traditional detection methods often falter due to their reliance on static thresholds and neglect of stylistic nuances inherent in human writing. This paper introduces the Mixture of Stylistic Experts (MoSEs) framework to overcome these limitations by incorporating stylistics-aware uncertainty quantification and adaptive thresholding.
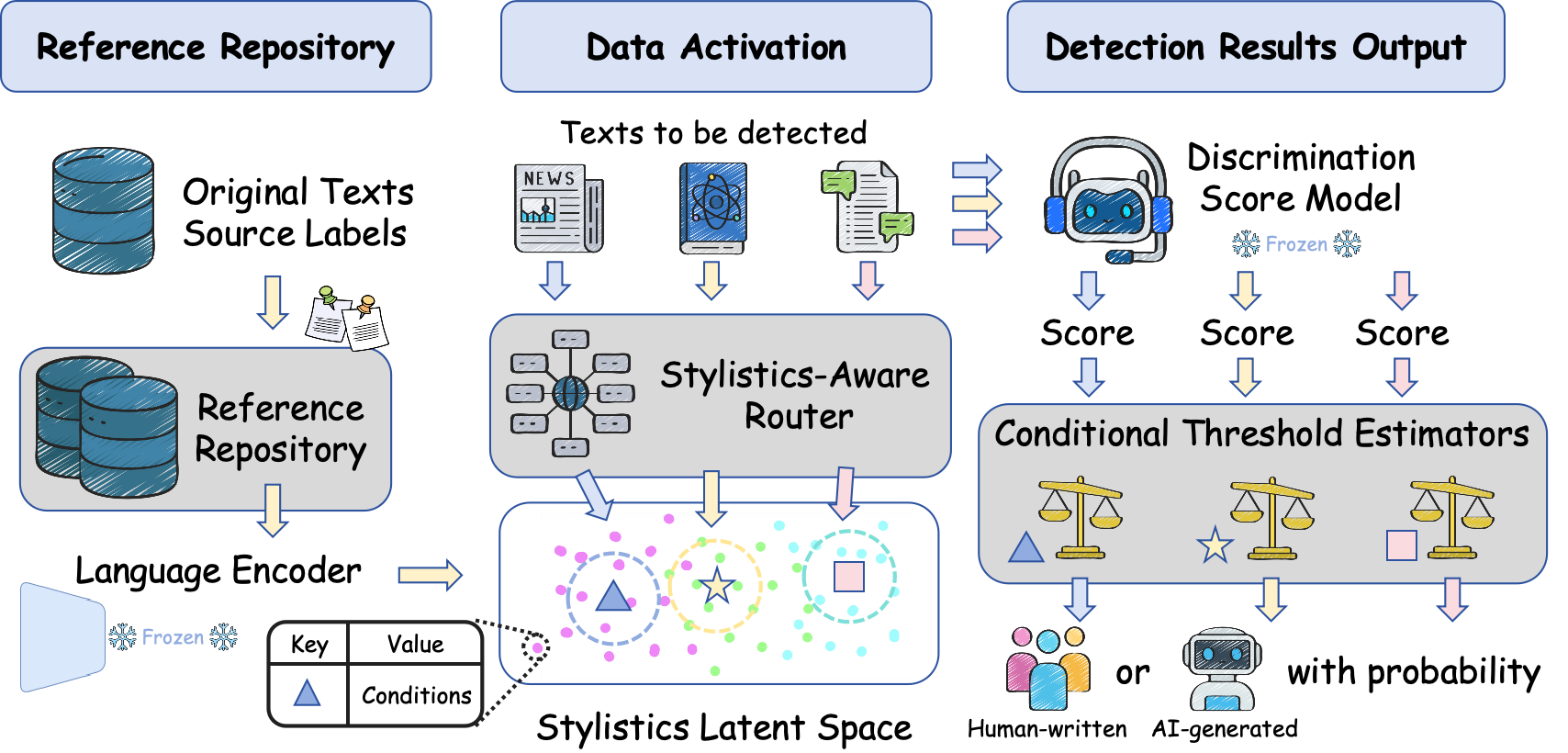
Figure 1: Overview of the MoSEs detection framework, illustrating the process of detecting texts across different genres by utilizing a reference repository with semantic embeddings.
MoSEs Framework
MoSEs integrates three pivotal components to advance AI-generated text detection:
- Stylistics Reference Repository (SRR): The SRR is a curated dataset containing various text styles labeled with binary detection (AI or human) and annotated with multi-dimensional linguistic features. This repository serves as a foundation for the MoSEs framework, providing diverse stylistic models that reflect profession-specific writing cues such as journalistic precision or academic rigor.
- Stylistics-Aware Router (SAR): SAR dynamically selects appropriate reference samples from SRR based on the semantic features of input texts. This is achieved through a prototype-based approximation, where each style is represented by cluster prototypes. By activating groups of samples corresponding to m-nearest prototypes, SAR refines potential author groupings without relying on predefined stylistic categories.
- Conditional Threshold Estimator (CTE): CTE adapts classification thresholds based on the input text's context, utilizing logistic regression or XGBoost models. CTE integrates linguistic statistical properties and semantic features to determine optimal thresholds adaptively, thus enhancing detection reliability and confidence.
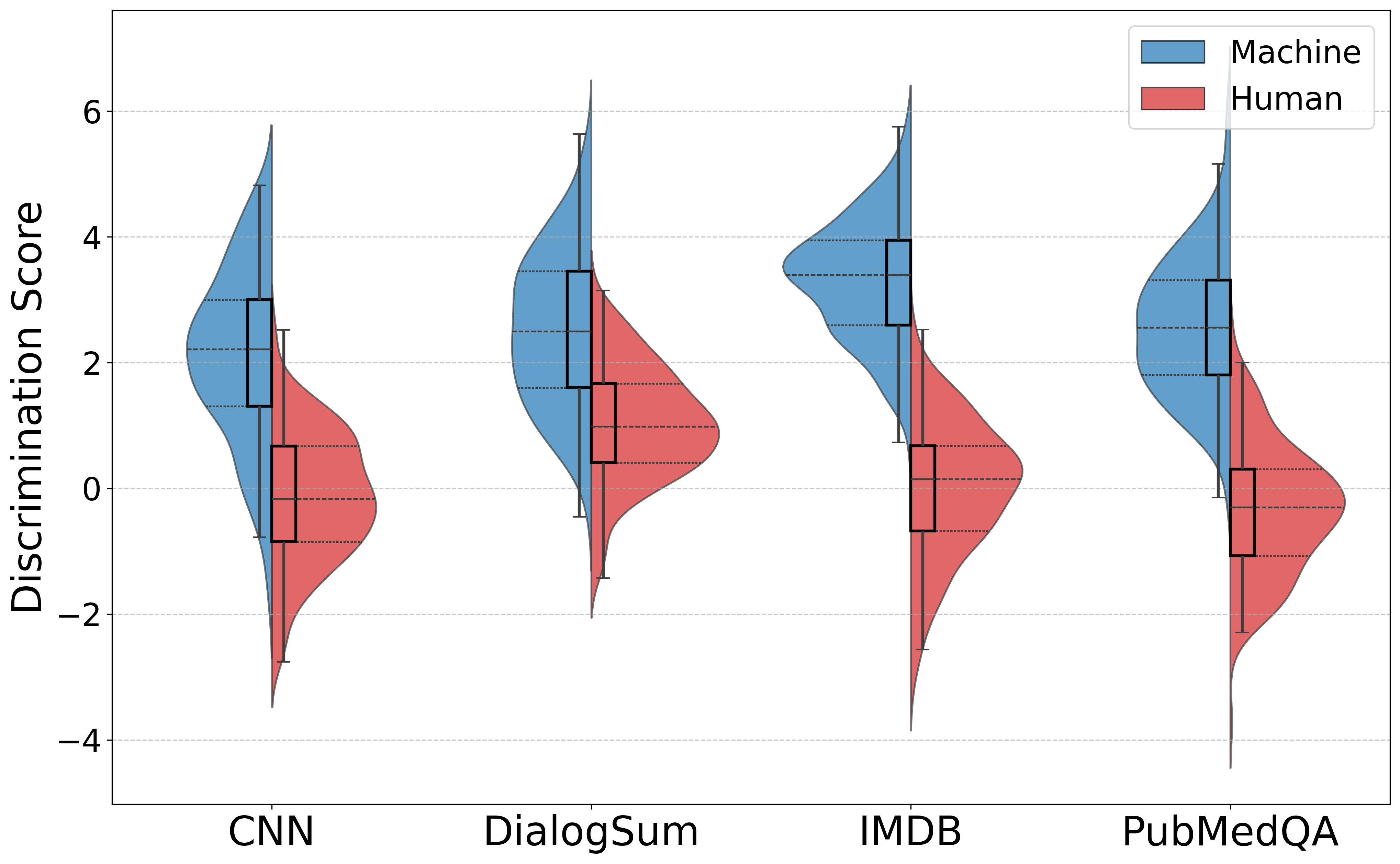
Figure 2: Distribution of discrimination scores for AI-generated and human-written samples across different styles, highlighting the stylistic variance.
Experimental Results
The MoSEs framework was tested across multiple datasets, demonstrating significant improvements over baseline methods. On average, MoSEs surpasses traditional detection approaches by 11.34% in accuracy and F1 score, with even more pronounced improvements of 39.15% in low-resource scenarios.
The experimental results underscore the framework's adaptability and robustness, particularly in diverse text environments and under conditions with limited data. This performance reflects the efficacy of stylistics-aware and adaptive thresholding in navigating the complexities of AI-generated content.
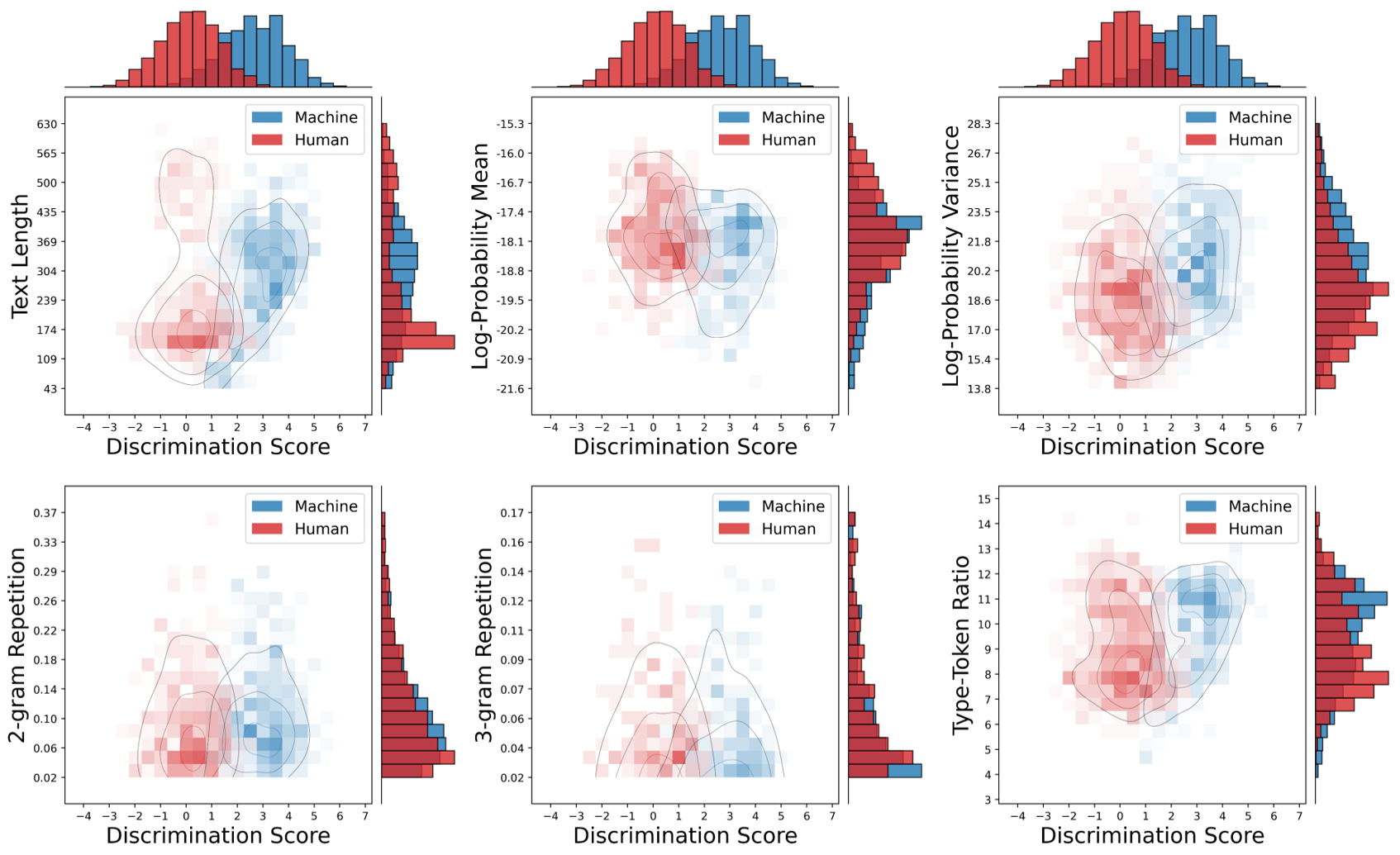
Figure 3: Conditional distributions of discrimination scores under various linguistic statistical properties, illustrating the refined detection capability of MoSEs.
Implications and Future Directions
The implications of the MoSEs framework extend beyond immediate detection improvements. By focusing on stylistic cues and adaptive thresholds, MoSEs provides a foundation for future developments in AI detection systems that can be tailored to specific domains or professions. Moreover, the integration of conditional features offers a pathway for enhanced transparency and trust in AI-generated content detection.
In future work, the MoSEs approach could be expanded to encompass multi-source detection and enhanced interpretability, leveraging additional contextual data. Furthermore, the exploration of more intricate nonlinear relationships and advanced machine learning models could deepen the framework's capability.
Conclusion
The MoSEs framework sets a new standard in AI-generated text detection, addressing the critical need for adaptive and reliable detection methodologies. Through its innovative incorporation of stylistic analysis and conditional threshold estimation, this approach not only enhances performance but also broadens the scope of applicability in diverse and challenging contexts. As AI-generated content continues to evolve, MoSEs represents a significant step forward in ensuring responsible and trustworthy deployment of LLMs.