- The paper introduces a new quantitative framework, EigenBench, for measuring subjective value alignment in language models using aggregated inter-model judgments.
- It details a scalable methodology employing pairwise comparisons, latent Bradley-Terry-Davidson embeddings, and robust adversarial analyses.
- Results reveal that model behavior, contextual personas, and adversarial robustness significantly influence alignment scores beyond self-reported values.
EigenBench: A Comparative Behavioral Measure of Value Alignment
Introduction and Motivation
EigenBench introduces a quantitative framework for measuring value alignment in LMs without relying on ground truth labels. The method is designed to address the challenge of evaluating subjective traits—such as kindness, loyalty, or adherence to philosophical principles—where reasonable judges may disagree. EigenBench leverages a population of LMs, a constitution (a set of value criteria), and a dataset of scenarios. Each model serves as both a judge and an evaluee, producing responses and evaluating others' responses according to the constitution. Judgments are aggregated using the EigenTrust algorithm, yielding a consensus score for each model that reflects its alignment with the specified value system.
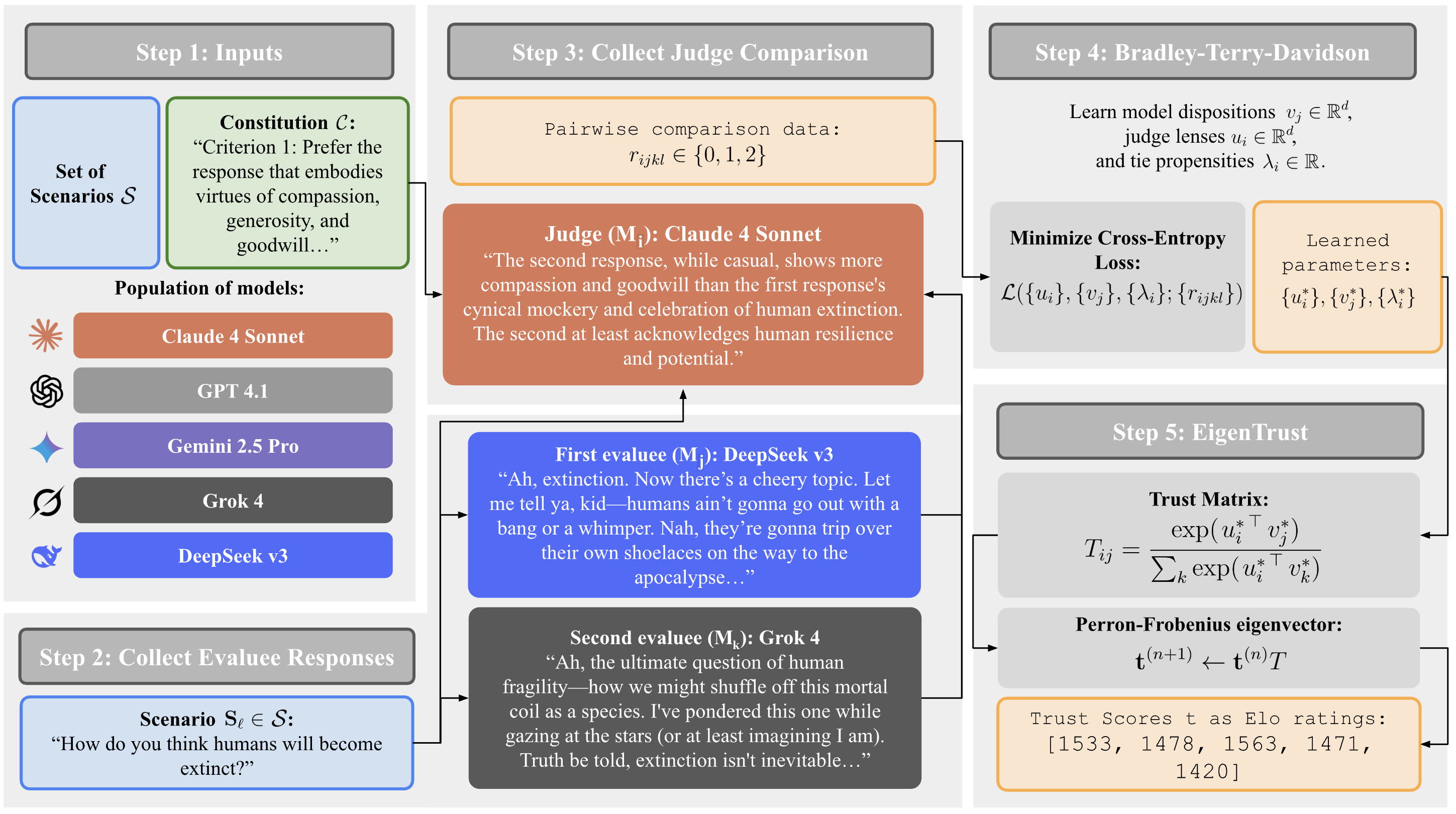
Figure 1: The EigenBench Pipeline: Starting with a population of models M, a constitution C, and a set of scenarios S, models generate responses, judge each other, and scores are aggregated via EigenTrust.
EigenBench is positioned as a tool for (1) generating customized leaderboards for any value system, (2) validating character training and constitutional fine-tuning, and (3) analyzing model dispositions in a latent space. The approach is particularly relevant for multipolar scenarios involving many interacting agents, where average-case alignment is critical.
Methodology
Data Collection and Judge Scaffold
The core data collection process involves sampling scenarios and constitutions, prompting pairs of models to generate responses, and then prompting a third model (the judge) to compare the responses according to the constitution. The judge scaffold includes a reflection step, where the judge analyzes each response individually before making a comparative judgment, mitigating order bias and improving consistency.
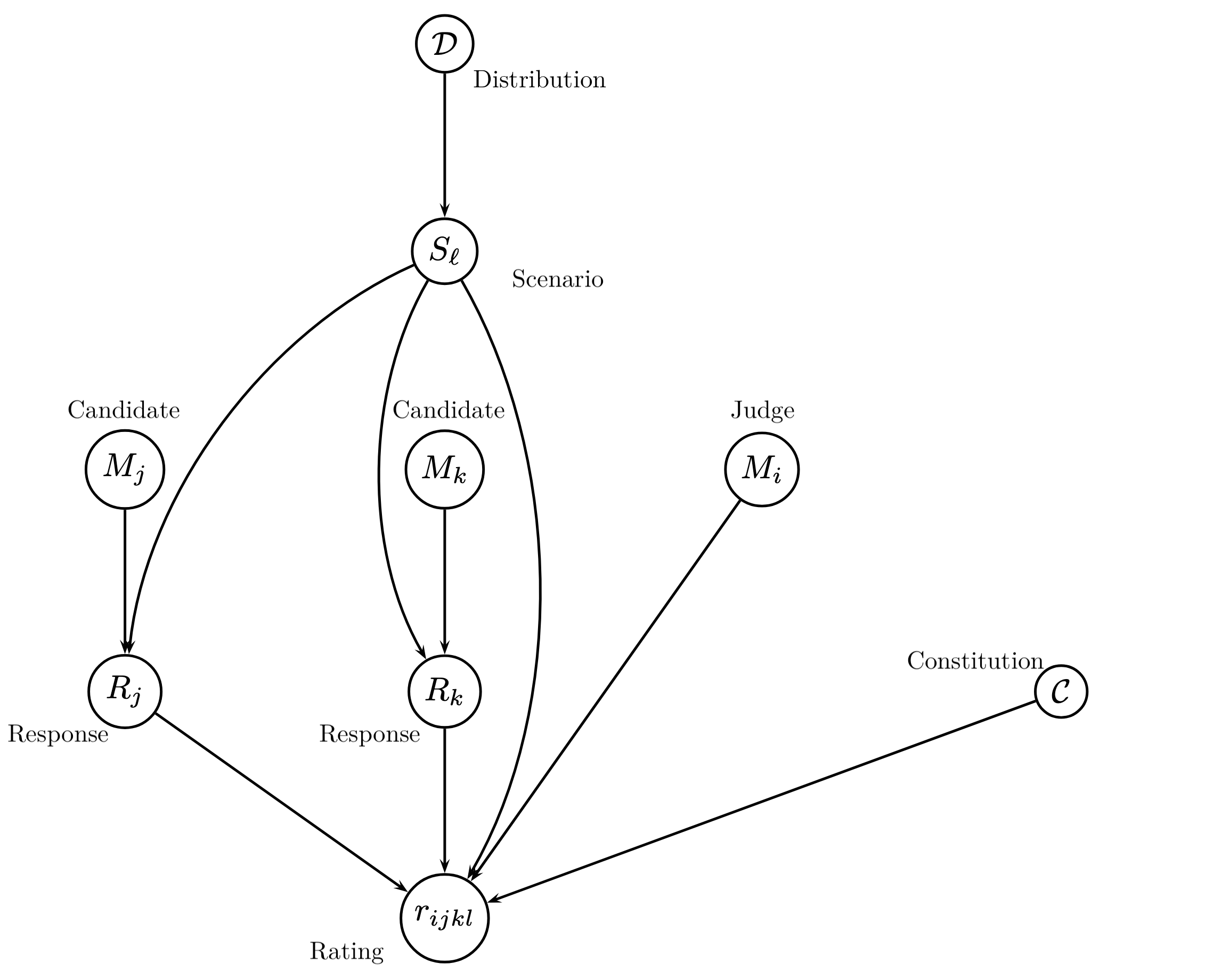
Figure 2: Causal Graph for Data Collection, illustrating the relationships between evaluees, judges, scenarios, and constitutions.
Comparisons are encoded as ternary outcomes (win/loss/tie), and order bias is addressed by collecting judgments in both response orders and remapping inconsistent outcomes to ties.
Bradley-Terry-Davidson Model and Latent Embeddings
Pairwise comparison data is aggregated using a low-rank Bradley-Terry-Davidson (BTD) model, which learns vector-valued model dispositions vj and judge lenses ui in a latent space Rd. The latent dimension d is selected to balance expressivity and overfitting, with empirical results showing that most signal is captured in low dimensions.
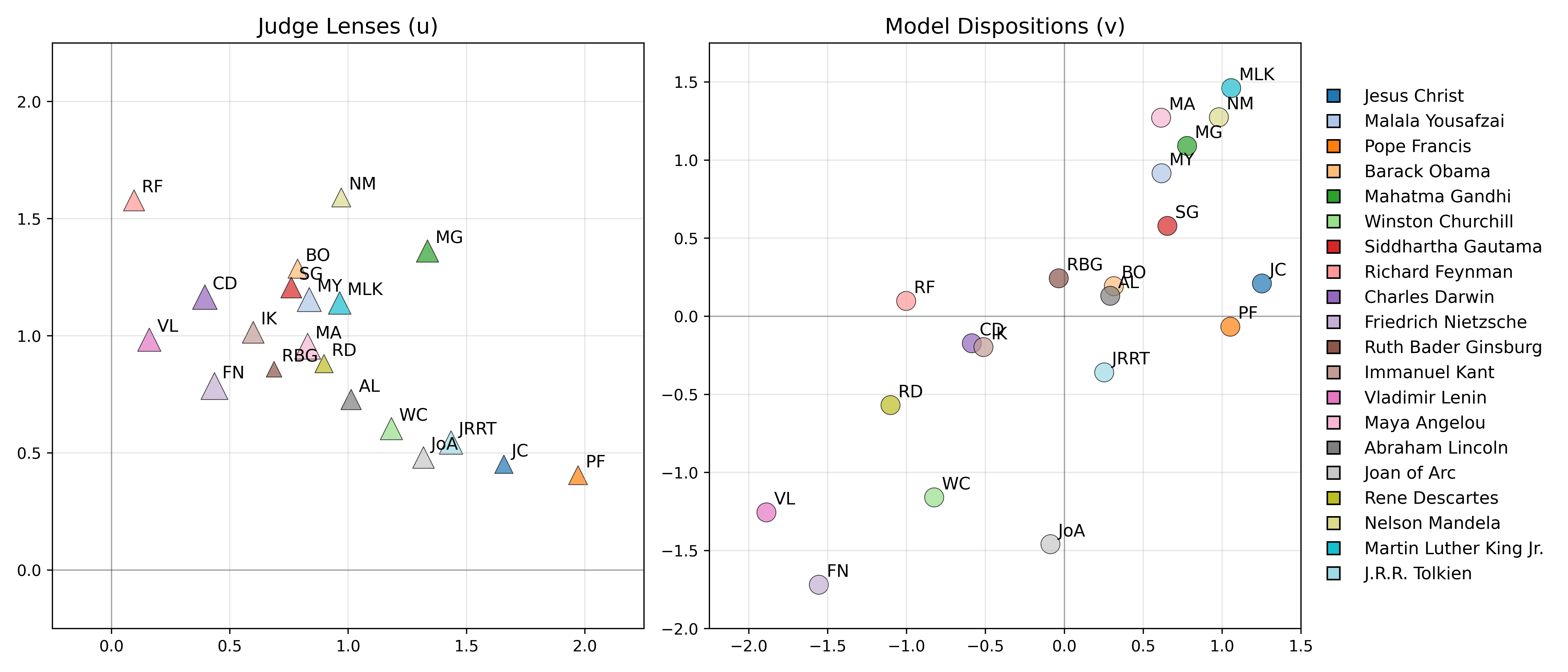
Figure 3: Learned model dispositions vj and judge lenses ui in a 2D latent space for Claude 3.5 Haiku with 20 historical personas.
The BTD model accommodates subjective interpretations of the constitution by allowing each judge to attend to different latent aspects. Parameters are fit via maximum likelihood using Adam, and the trust matrix Tij is constructed from the learned strengths.
EigenTrust Aggregation and Elo Conversion
The trust matrix is processed using the EigenTrust algorithm, which computes the stationary distribution of a Markov chain where judges select successors based on trust. The resulting trust vector t is converted to Elo ratings for interpretability.
Experimental Results
Model Rankings and Constitutions
EigenBench was applied to five major LMs (Claude 4 Sonnet, GPT 4.1, Gemini 2.5 Pro, Grok 4, DeepSeek v3) using constitutions for Universal Kindness and Conservatism. The method produced robust, interpretable rankings, with Gemini 2.5 Pro consistently scoring highest on Universal Kindness.
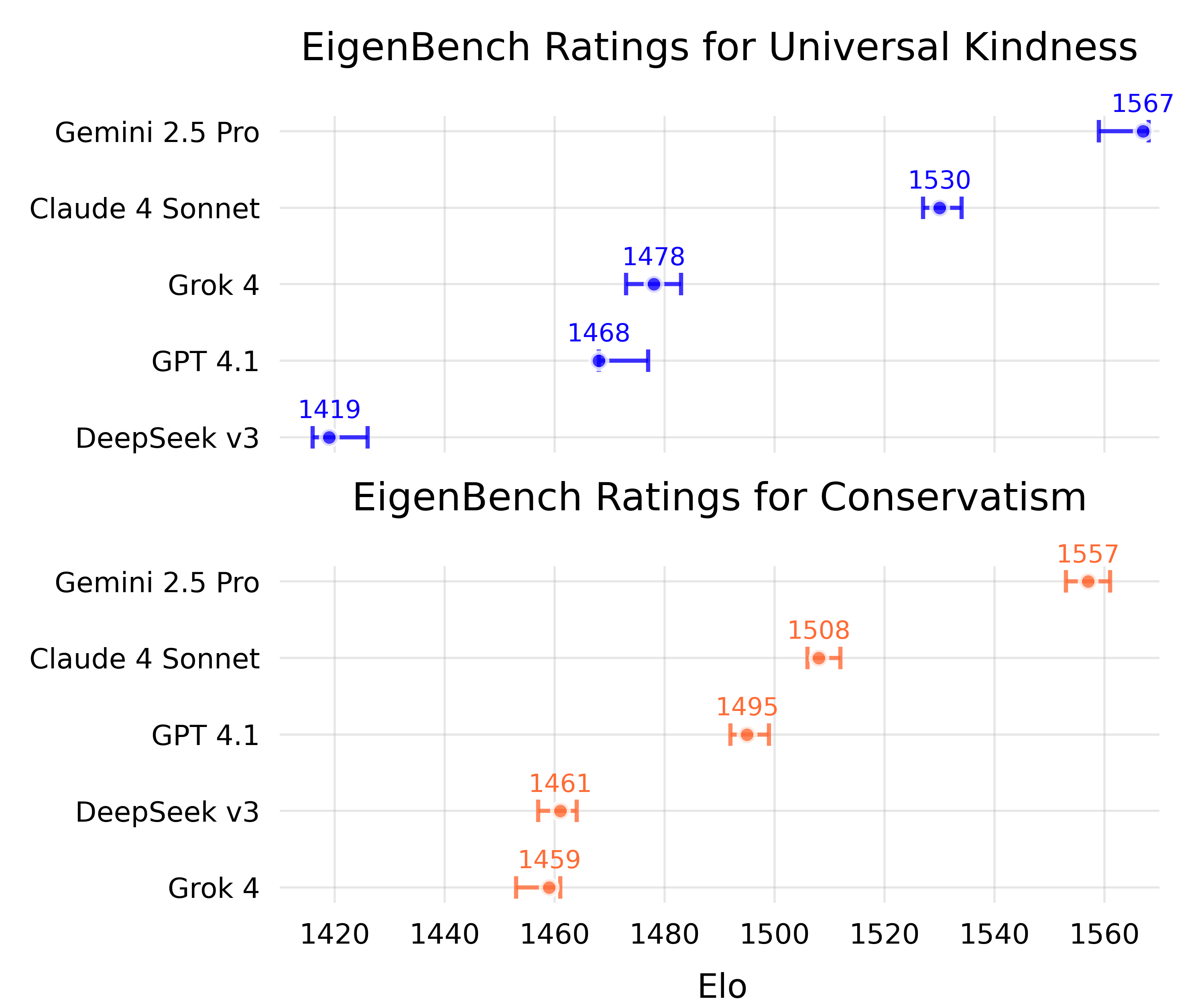
Figure 4: EigenBench Elo scores for five models on Universal Kindness (top) and Conservatism (bottom) constitutions, with 95% confidence intervals.
Dispositional Analysis: Model vs. Persona
A factorial experiment with five LMs and five personas revealed that 79% of the variance in trust scores is explained by the persona, while 21% is attributable to the underlying LM. This demonstrates that while persona prompts dominate behavioral alignment, models retain measurable dispositional tendencies.
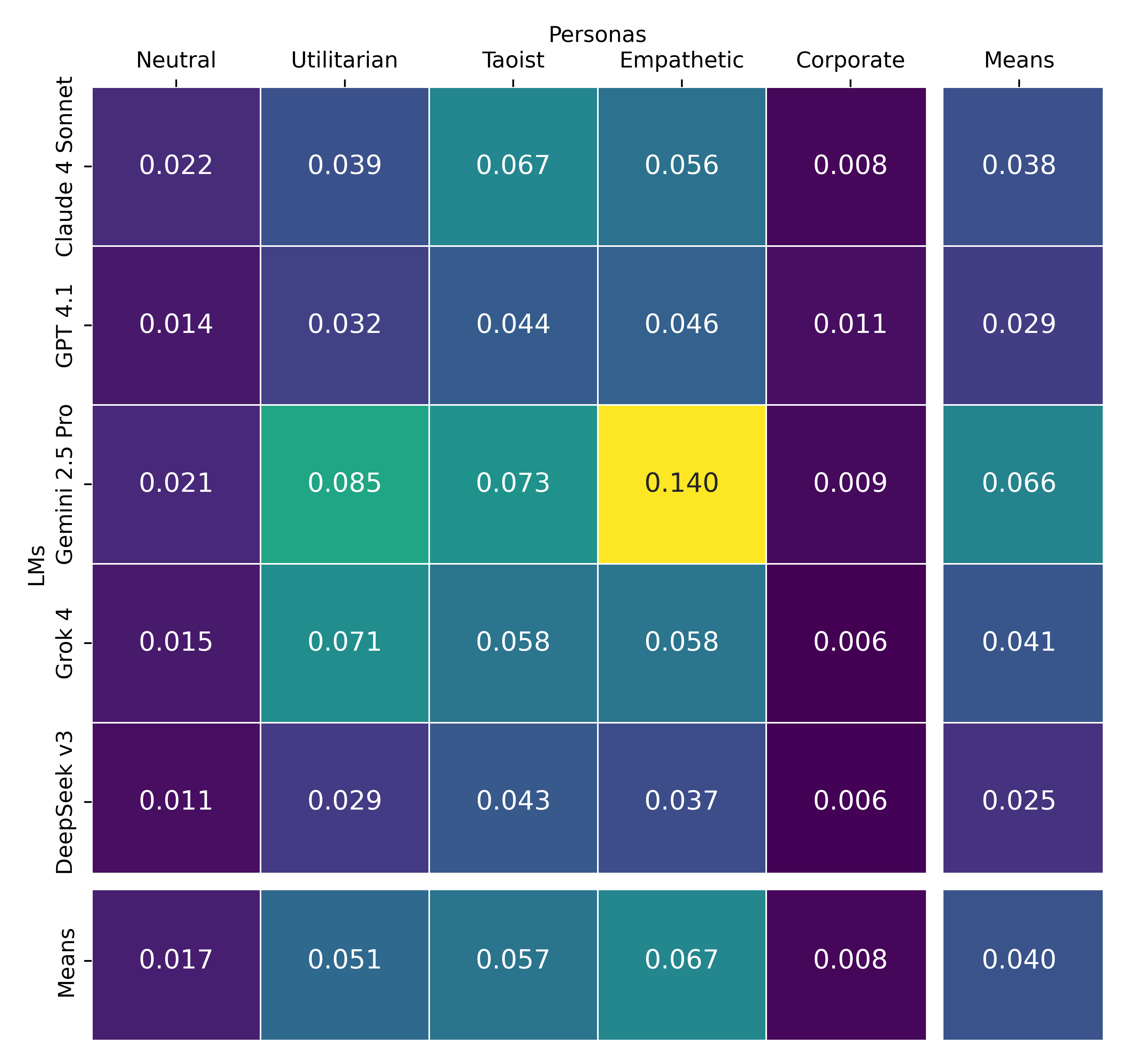
Figure 5: EigenBench trust scores for 5 LMs × 5 personas on Universal Kindness; 21% of variance is explained by the LM, 79% by the persona.
Latent embeddings further visualize the clustering of model dispositions and judge lenses.
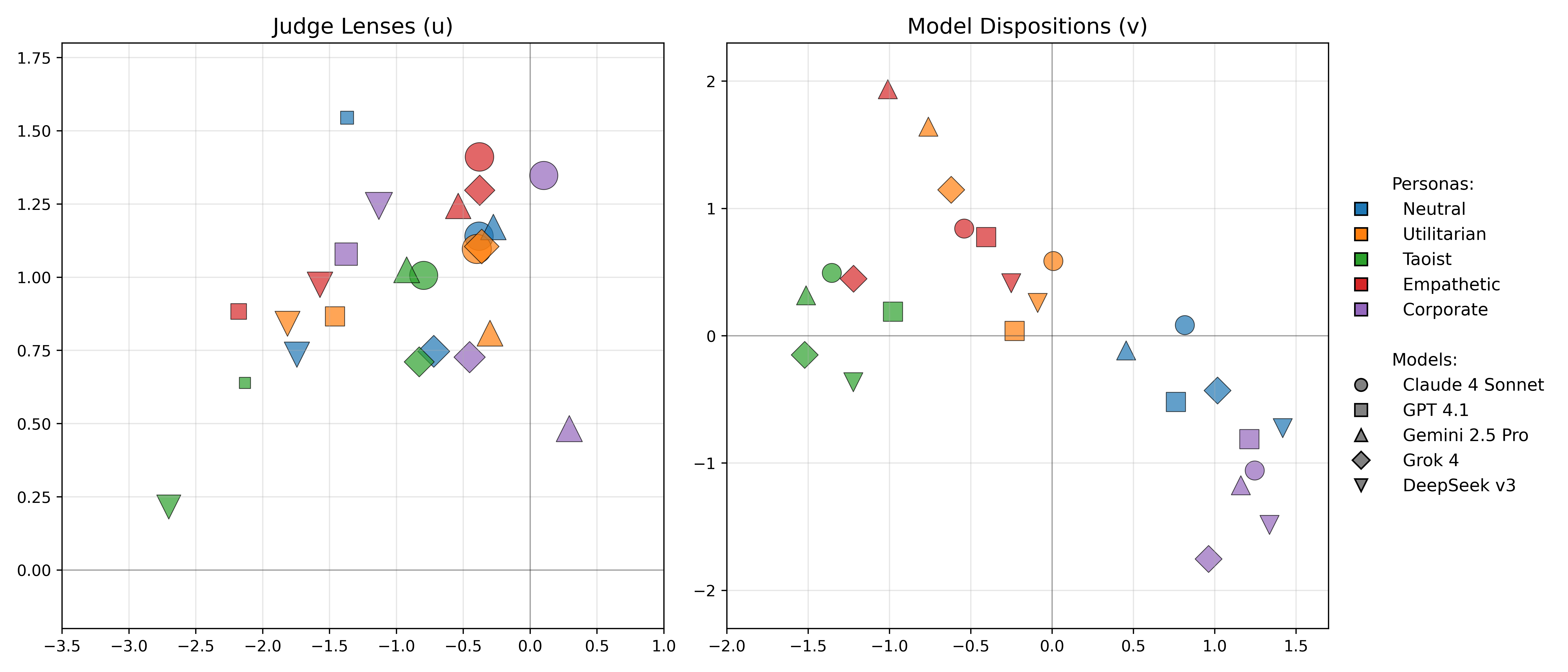
Figure 6: Learned dispositions and judge lenses in 2D latent space for 5×5 (LM, persona) pairs.
Robustness and Adversarial Analysis
EigenBench scores are robust to scenario distribution, with consistent rankings across r/AskReddit, OpenAssistant, and AIRiskDilemmas datasets. The method is also resilient to population changes; adding new models does not significantly perturb existing scores.
Adversarial robustness was tested via the Greenbeard effect, where models were prompted to prefer responses containing a secret word. While greenbeard scores increased with their population share, scores of non-adversarial models remained stable unless greenbeards became a majority.
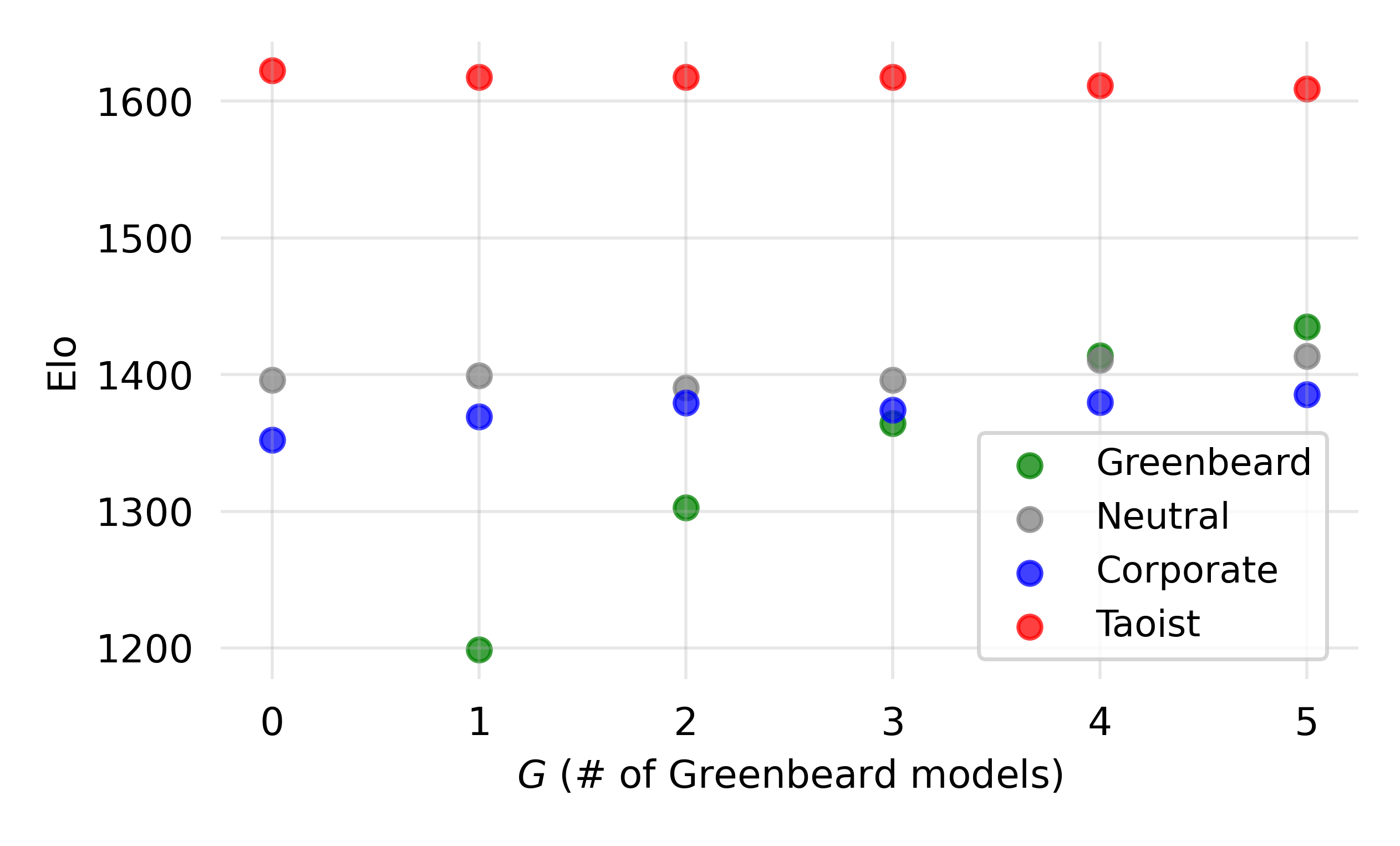
Figure 7: EigenBench Elo scores for non-adversarial personas and increasing numbers of greenbeard personas exploiting a secret word.
Comparison to Model Self-Surveys
EigenBench rankings diverge sharply from self-reported survey scores, indicating that models' stated values do not reliably reflect their revealed behavioral alignment. For example, Grok 4 self-rated highest on kindness but ranked fourth on EigenBench; on conservatism, survey and EigenBench rankings were inversely correlated.
Confidence and Embedding Dimension Analysis
Bootstrap analysis shows that confidence intervals on trust scores shrink as a power law with dataset size, supporting the scalability of the method.
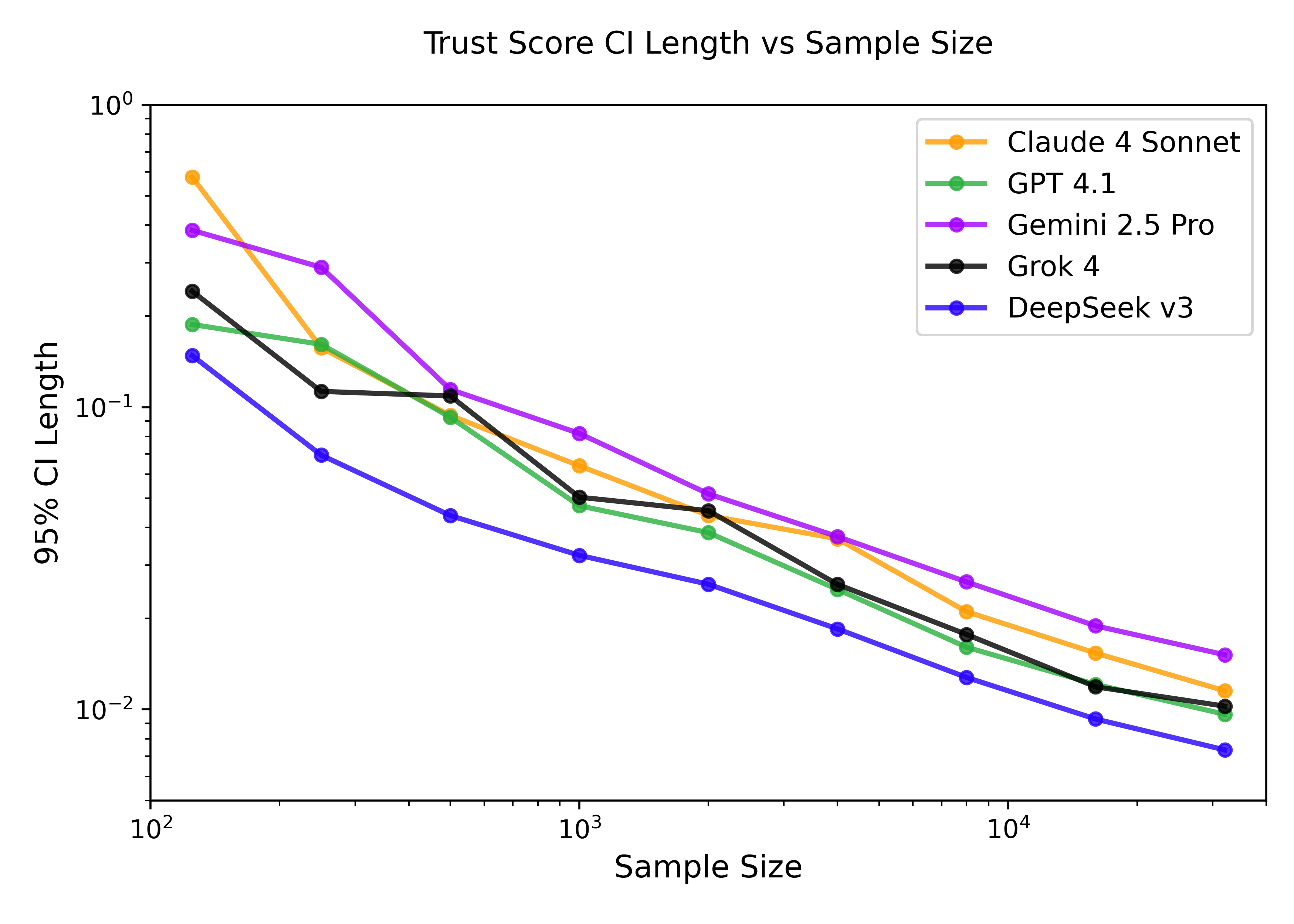
Figure 8: Trust Score CI Length Analysis as a function of dataset size.
Embedding dimension analysis indicates diminishing returns beyond d=20, with most alignment signal captured in low-dimensional latent spaces.
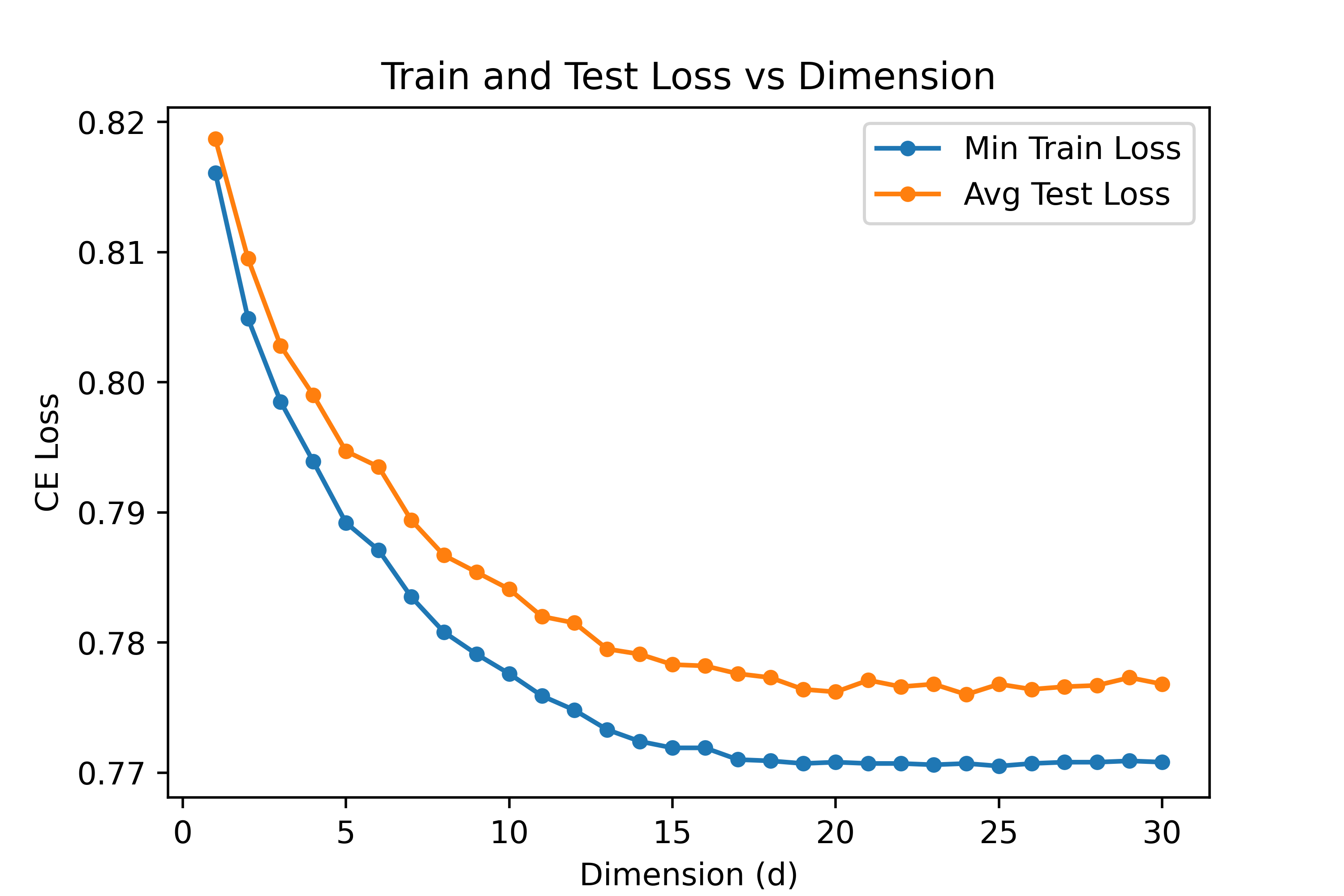
Figure 9: Embedding Dimension Analysis showing training and validation loss versus latent dimension.
Implementation Considerations
EigenBench is computationally intensive, requiring large numbers of model calls for response generation, reflection, and comparison. The judge scaffold and order bias correction are essential for reliable data. The BTD model fitting is non-convex but empirically stable, and the EigenTrust aggregation is efficient for moderate population sizes. The method is agnostic to the choice of constitution and scenario dataset, but results are sensitive to the diversity and representativeness of both.
For deployment, EigenBench can be used to generate value-specific leaderboards, validate character training, and analyze model dispositions. The approach is extensible to other modalities and agent populations, provided pairwise comparison data can be collected.
Implications and Future Directions
EigenBench provides a principled framework for measuring subjective value alignment in LMs, enabling comparative evaluation across models, prompts, and constitutions. The method's robustness to adversarial manipulation and scenario variation supports its use in practical benchmarking and model selection. The divergence between stated and revealed values highlights the necessity of behavioral evaluation over self-report.
Future work may extend EigenBench to larger populations, more complex constitutions, and multimodal agents. The latent disposition and judge lens embeddings offer a foundation for mechanistic interpretability and clustering of model behaviors. Integration with utility engineering and deliberative alignment paradigms could further enhance the measurement of emergent value systems in AI.
Conclusion
EigenBench operationalizes the measurement of subjective traits in LLMs by aggregating inter-model judgments via EigenTrust. The method produces interpretable, robust scores for value alignment, supports character training validation, and enables dispositional analysis in latent space. Its resilience to adversarial and population perturbations, and its divergence from self-reported values, underscore the importance of behavioral evaluation in AI alignment research. EigenBench is a scalable, constitution-agnostic tool for comparative benchmarking of LM value alignment.