- The paper introduces an 8B-parameter multimodal language model featuring a novel SlowFast video encoding strategy, achieving state-of-the-art performance on video benchmarks.
- It employs a progressive pre-training pipeline that extends context to 128K tokens and integrates rigorous post-training with reasoning and human-preference alignment.
- Empirical evaluations reveal significant improvements in temporal reasoning and precise object localization, validating the model's robust multimodal capabilities.
Kwai Keye-VL-1.5: Technical Overview and Empirical Analysis
Introduction
Kwai Keye-VL-1.5 is an 8B-parameter Multimodal LLM (MLLM) designed to address the persistent challenges in video understanding, including the trade-off between spatial resolution and temporal coverage, long-context processing, and robust multimodal reasoning. The model introduces three principal innovations: (1) a Slow-Fast video encoding strategy for adaptive frame selection and resource allocation, (2) a progressive pre-training pipeline extending context length to 128K tokens, and (3) a comprehensive post-training regime focused on reasoning and human preference alignment. Empirical results demonstrate state-of-the-art performance on video-centric benchmarks and competitive results on general multimodal tasks.
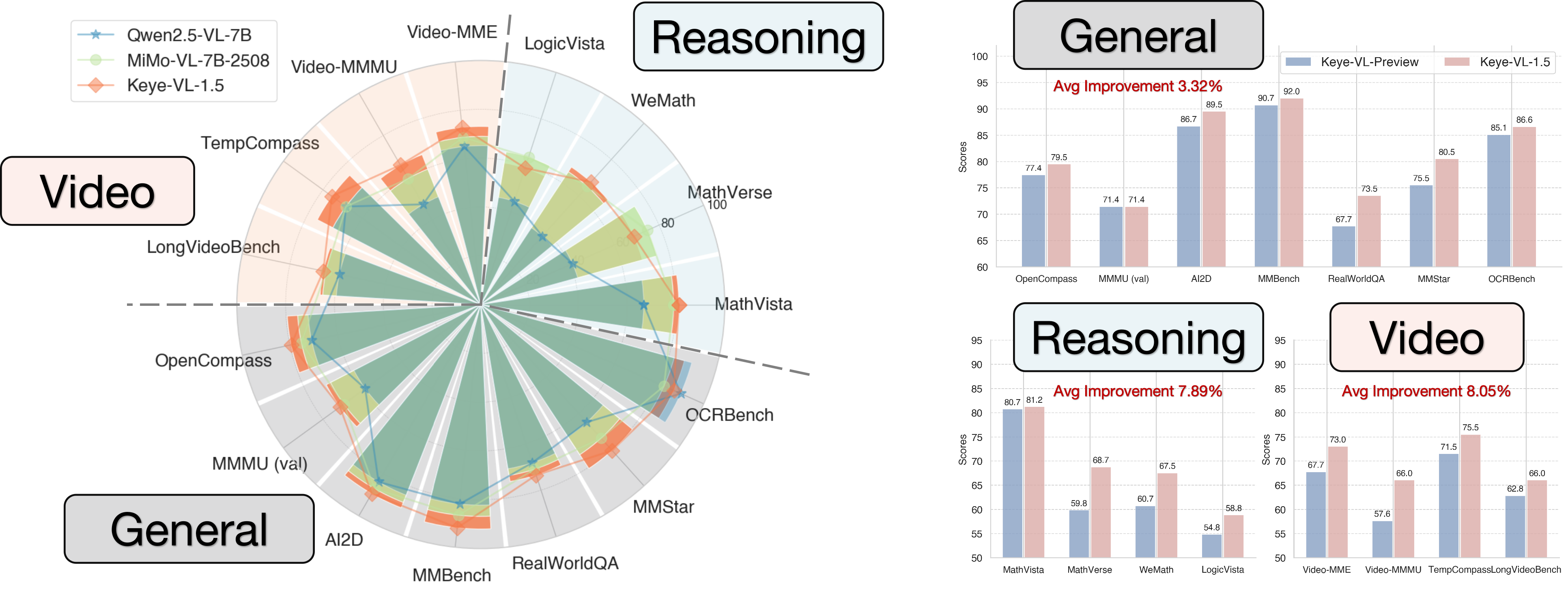
Figure 1: Keye-VL-1.5-8B establishes new state-of-the-art performance among models of similar scale, demonstrating superior results on video-centric benchmarks while maintaining competitive performance on general multimodal and reasoning tasks.
Model Architecture
Keye-VL-1.5 is built upon the Qwen3-8B LLM and leverages a vision encoder initialized from SigLIP-400M-384-14. The architecture supports native dynamic resolution, preserving the original aspect ratio of images via a 14x14 patch sequence. A simple MLP layer merges visual tokens, and 3D Rotary Position Embedding (RoPE) is employed for unified processing of text, image, and video modalities.
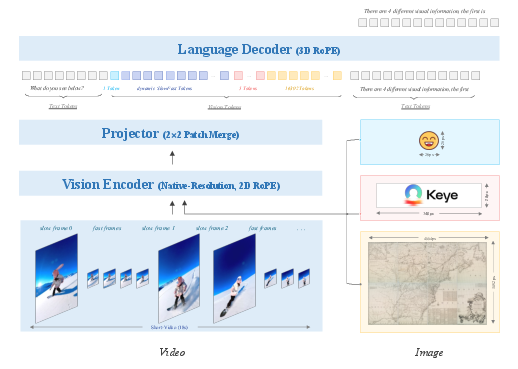
Figure 2: The Kwai Keye-VL-1.5 model architecture integrates Qwen3-8B and SigLIP, supporting SlowFast video encoding and native dynamic resolution with 3D RoPE for unified multimodal processing.
Vision Encoder
The vision encoder is adapted for native-resolution processing, using interpolation to extend fixed-length position embeddings and integrating 2D RoPE for improved extrapolation. FlashAttention and NaViT packing are utilized for efficient training across varying image resolutions. The encoder is pre-trained on 500B tokens from DataComp, LAION, CC12M, PD12M, COCO, and proprietary datasets.
Slow-Fast Video Encoding
The Slow-Fast strategy dynamically allocates computational resources based on inter-frame similarity. Key frames with significant changes are processed at higher resolution (Slow pathway), while static frames are handled at lower resolution but higher temporal coverage (Fast pathway). Patch-based similarity functions identify frame types, and token budgets are adaptively allocated.

Figure 3: SlowFast video encoding: Slow processes fewer frames at higher resolution, Fast handles more frames at lower resolution.
Pre-Training Pipeline
The pre-training pipeline consists of four progressive stages:
- Image-Text Matching: Cross-modal alignment with frozen vision and LLM parameters, optimizing the projection MLP.
- ViT-LLM Alignment: End-to-end optimization with multi-task data, enhancing fundamental visual understanding.
- Multi-task Pre-training: Exposure to diverse tasks (captioning, OCR, grounding, VQA, interleaved data).
- Annealing and Model Merging: Fine-tuning on high-quality data, extending context length from 8K to 128K tokens, and merging models trained on different data mixtures.
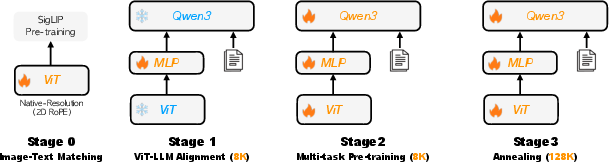
Figure 4: The four-stage progressive pre-training pipeline, culminating in model merging for robustness and bias reduction.
Post-Training: Reasoning and Alignment
Post-training is divided into non-reasoning (SFT + MPO) and reasoning stages. SFT leverages a 7.5M sample pool, with TaskGalaxy providing diverse multimodal tasks. MPO uses paired preference data for optimization. The reward model is trained on Keye-VL-preview outputs, supporting both think and no-think evaluation modes.
LongCoT Cold-Start and Data Generation
A five-step automated pipeline generates high-quality Long Chain-of-Thought (LongCoT) data, integrating automated MLLM generation, dual-level quality assessment, human-in-the-loop refinement, and dynamic quality scoring.
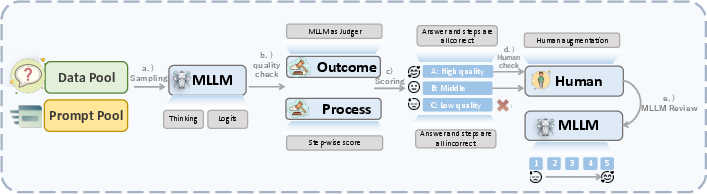
Figure 5: Five-step LongCoT data generation pipeline, ensuring scalability and quality control for reasoning data.
Model Merging
Domain-specific expert models (e.g., OCR, mathematical reasoning) are merged with the general model to address concentrated weaknesses, using SFT and model merging techniques.
Iterative RL and Progressive Hint Sampling
General RL is performed using GSPO, with progressive hint sampling for hard cases. Hints are provided in five levels, from conceptual to complete solution, optimizing the minimal intervention required for successful reasoning.
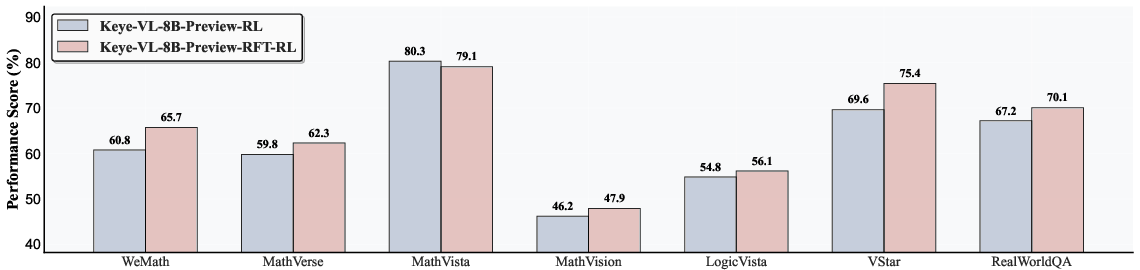
Figure 6: Rejection sampling in RL phase: iterative RL and SFT-RL strategies yield significant performance improvements.
Training Infrastructure
A heterogeneous hybrid parallel strategy is employed: data parallelism for ViT, and pipeline/tensor/data parallelism for LLM. Dynamic load balancing and a scalable dataloader address computational and I/O bottlenecks, supporting 128K sequence training.
Empirical Evaluation
Benchmark Results
Keye-VL-1.5 achieves SOTA or near-SOTA results on general vision-language, video, and mathematical reasoning benchmarks. On OpenCompass, MMMU, and AI2D, it outperforms all open-source models. In video-centric tasks, it demonstrates a 6.5% absolute improvement on Video-MMMU over competitors.
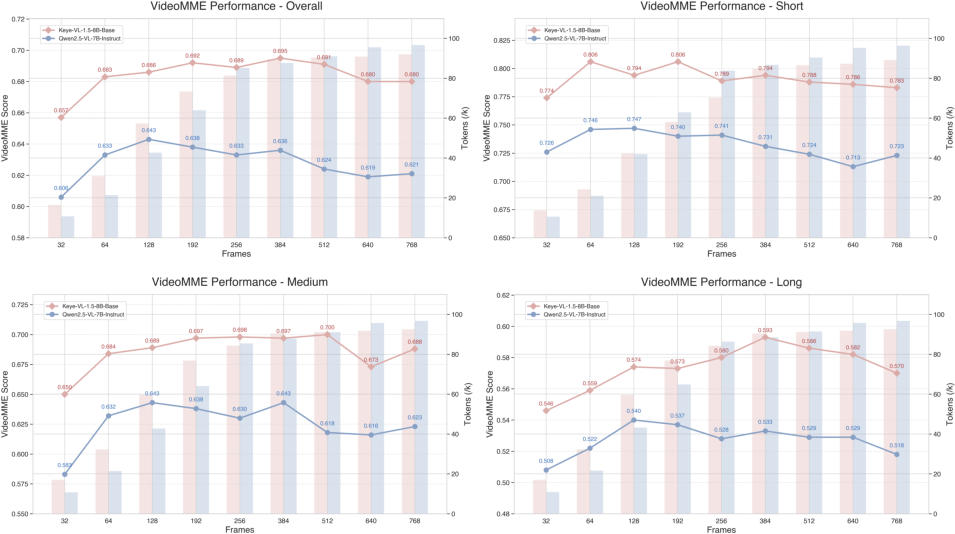
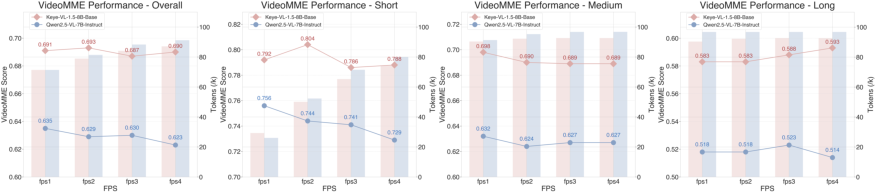
Figure 7: SlowFast and 2D convolution video encoding strategies compared on VideoMME; Keye-VL-1.5-Base exhibits strong visual understanding across diverse frame numbers and FPS.
Internal Benchmarks
A proprietary evaluation suite assesses correctness, completeness, relevance, fluency, creativity, and robustness. Keye-VL-1.5-8B achieves a composite score of 3.53, outperforming MiMoVL-7B-RL-2508 (+0.13) and Keye-VL-Preview (+0.51), with pronounced gains in reasoning and temporal understanding.
Ablation Studies
Increasing SFT and MPO data volume consistently improves performance. LongCoT cold-start and RL phases yield substantial gains, especially in mathematical reasoning. Model merging with expert models enhances specialized capabilities (e.g., OCR: 84.51% vs. MiMoVL's 81.41%).
Case Studies
- Video Grounding: Keye-VL-1.5 pinpoints object appearance with 0.1s precision.
- Content Understanding: Accurately correlates video actions and captions for causal inference.
- Content Description: Provides detailed scene descriptions, though rare phenomena (e.g., hail) may be misclassified.

Figure 8: Keye-VL-1.5 accurately pinpoints the handbag's appearance in a 26s video, with 0.1s precision.

Figure 9: Keye-VL-1.5 correlates video content and caption, inferring the purpose of the big dog's action.

Figure 10: Keye-VL-1.5 describes a forest scene, correctly identifying precipitation but misclassifying hail.
Implementation Considerations
- Resource Requirements: 8B parameters, 128K context length, heterogeneous parallelism, and dynamic load balancing necessitate substantial GPU resources and optimized infrastructure.
- Scaling: Context extension and SlowFast encoding enable efficient scaling to longer videos and higher-resolution images.
- Limitations: Trade-offs exist between specialization and integration in model merging; language generation fluency lags behind factual accuracy in some domains.
- Deployment: Modular architecture and expert model merging facilitate domain adaptation and incremental updates.
Implications and Future Directions
Keye-VL-1.5 demonstrates that adaptive video encoding, long-context processing, and iterative RL with progressive hinting can substantially advance multimodal reasoning and video understanding. The model's architecture and training pipeline provide a blueprint for scalable, domain-adaptive MLLMs. Future work may focus on further improving language generation fluency, expanding expert model integration, and refining reward modeling for nuanced human preference alignment.
Conclusion
Kwai Keye-VL-1.5 establishes a new standard for video-centric multimodal models, combining architectural innovation, progressive training, and robust post-training methodologies. Its empirical results validate the effectiveness of SlowFast encoding, long-context extension, and iterative RL, offering practical solutions for next-generation multimodal AI systems. The model's modularity and adaptability position it as a strong foundation for future research in scalable, domain-specialized multimodal reasoning.