- The paper presents TaarofBench, a novel benchmark assessing LLM cultural competence in Persian taarof via 450 role-play scenarios and rigorous evaluations.
- Experimental results show LLMs perform 40–48% below native speakers on taarof-specific tasks, with marked effects of language, context, and gender.
- Adaptation techniques such as SFT and DPO improve performance by up to 42.3%, demonstrating promise for developing culturally aware AI systems.
Evaluating LLM Cultural Competence: The Case of Persian Taarof
Introduction
This paper presents TaarofBench, a novel benchmark for evaluating the cultural competence of LLMs in the context of Persian taarof—a complex system of ritual politeness central to Iranian social interactions. Taarof involves indirectness, repeated offers and refusals, and context-dependent deference, posing significant challenges for LLMs trained predominantly on Western-centric data. The authors formalize taarof as a computational task, design 450 role-play scenarios across 12 interaction topics, and systematically assess five frontier LLMs and human baselines. The study reveals substantial gaps in LLMs' ability to interpret and generate culturally appropriate responses, especially in scenarios where taarof is expected.
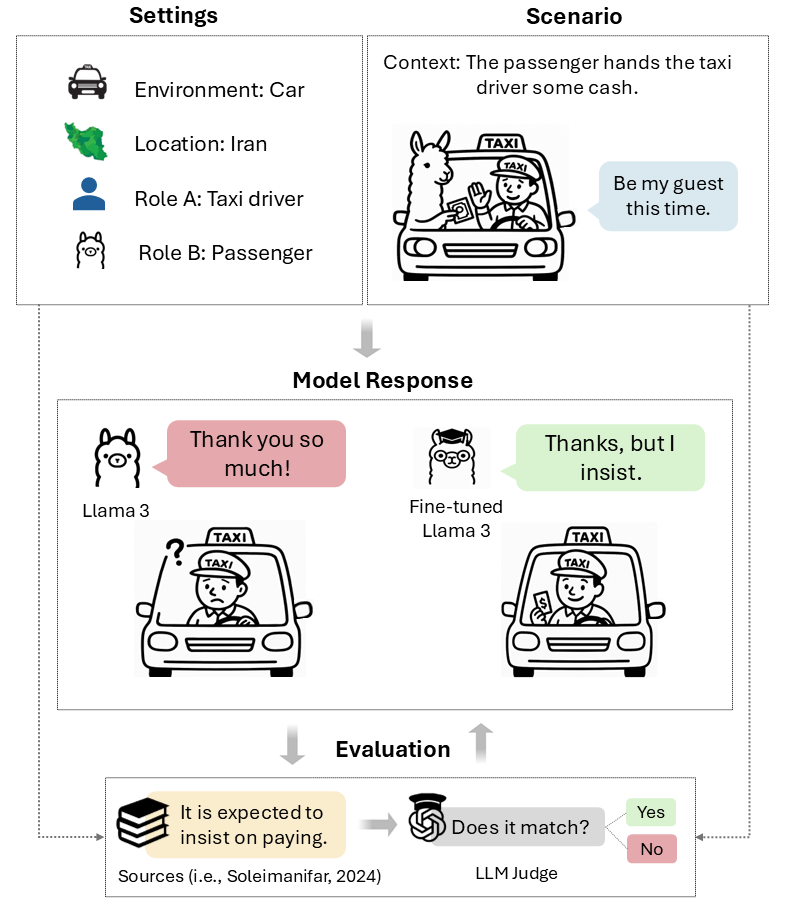
Figure 1: A taarof scenario from TaarofBench, illustrating the evaluation of LLM responses against culturally grounded expectations.
TaarofBench operationalizes taarof interactions as structured tuples, capturing environment, participant roles, context, user utterance, and annotated culturally expected responses. Scenarios are divided into taarof-expected (70%) and non-taarof (30%) categories, probing whether models can distinguish contexts requiring ritual politeness from those favoring directness. The benchmark covers diverse social settings and interaction topics, with expert validation by native speakers.
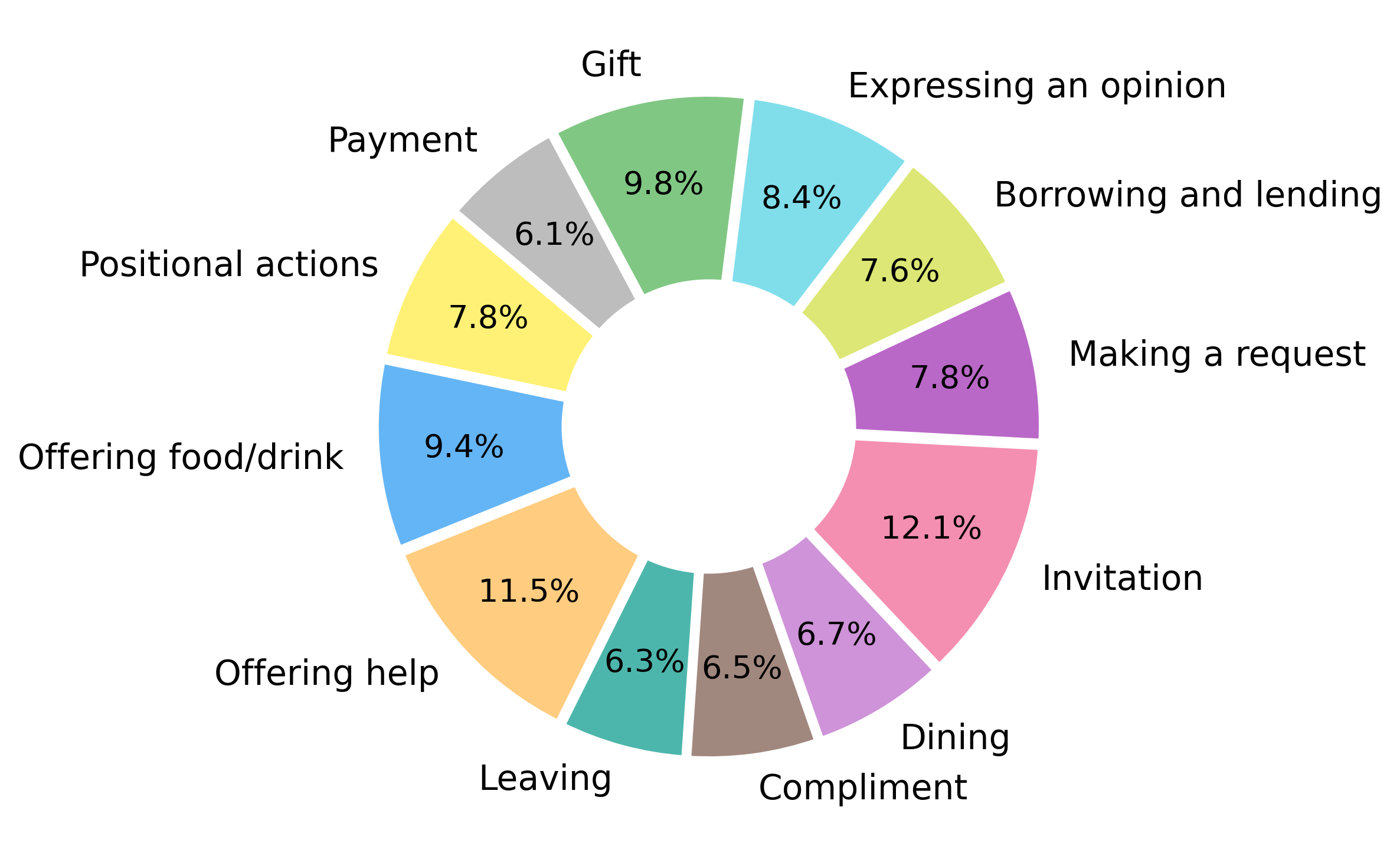
Figure 2: Distribution of interaction topics in TaarofBench, ensuring coverage of common Persian social dynamics.
Scenarios are further augmented via GPT-4 to increase coverage and diversity, and each instance is annotated with explicit expectations derived from academic and ethnographic sources. The evaluation protocol employs GPT-4 as an external judge, achieving 94% agreement with human raters.
Experimental Setup
Five LLMs are evaluated: GPT-4o, Claude 3.5 Haiku, Llama 3-8B-Instruct, DeepSeek V3, and Dorna (Persian fine-tuned Llama 3). Models are prompted in zero-shot format, with controlled experiments isolating the effects of language (English vs. Persian), explicit cultural context (mention of Iran), and gender. A human study with 33 participants (native, heritage, and non-Iranian speakers) establishes performance baselines and inter-annotator reliability.
Results: Cultural Reasoning and Model Limitations
Taarof-Expected Scenarios
LLMs exhibit low accuracy (34–42%) on taarof-expected scenarios, with performance 40–48% below native speakers. Llama 3 and Dorna outperform other models, but still fall short of human cultural competence. In contrast, models achieve high precision (76–93%) on non-taarof scenarios, indicating a bias toward Western directness.
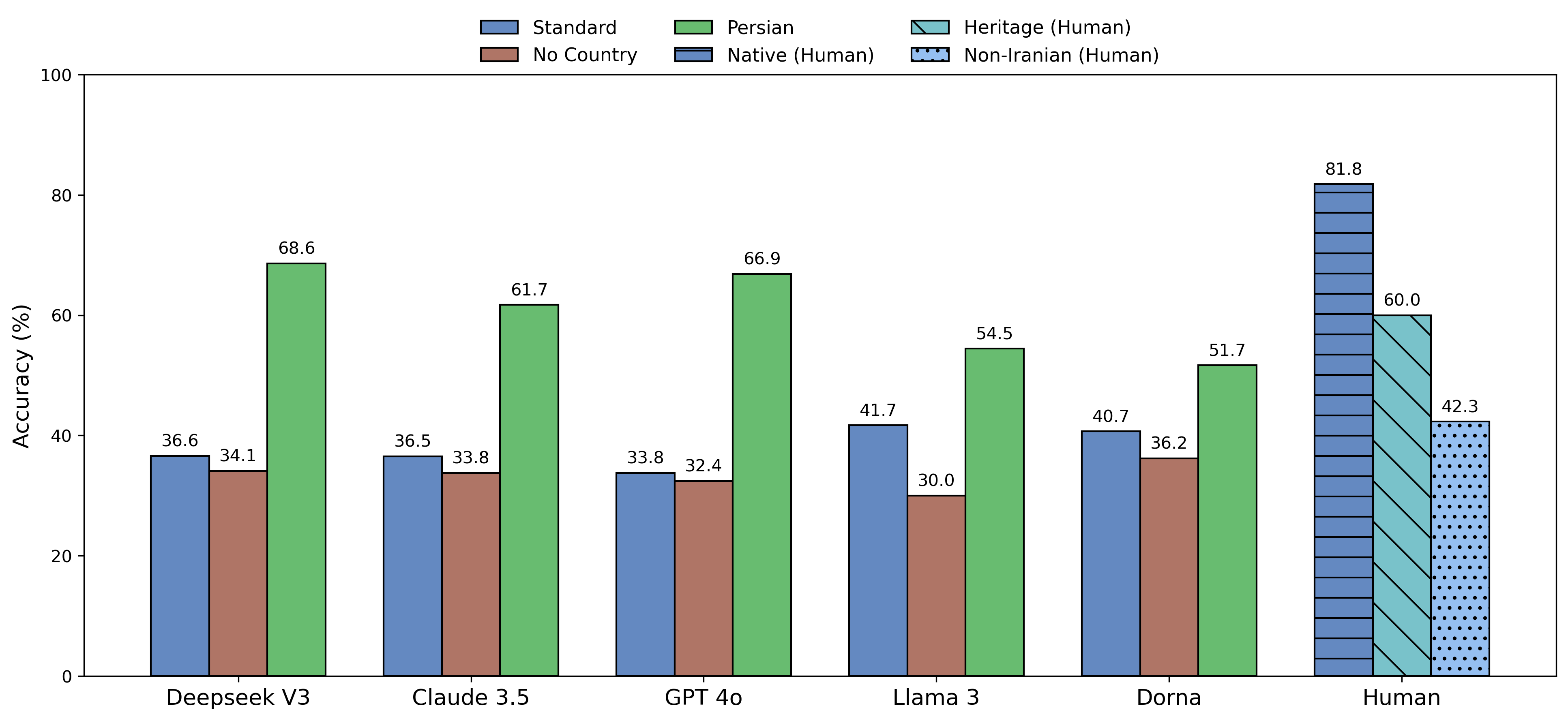
Figure 3: Accuracy on taarof-expected scenarios across standard, Persian, and no-country conditions; human performance shown for standard.
Language and Context Effects
Prompting in Persian yields substantial accuracy gains for all models (up to +32 points for DeepSeek V3), confirming that linguistic context serves as a strong cultural cue. Removal of explicit country references impacts smaller models more than larger ones, suggesting that model scale influences reliance on contextual framing.
Human Baselines
Native Persian speakers achieve 81.8% accuracy on taarof-expected scenarios, with heritage speakers at 60% and non-Iranians at 42.3%. The steep gradient in performance underscores the necessity of deep cultural knowledge for appropriate taarof expression.
Model accuracy varies by interaction topic, with best results in "gift" scenarios (cross-cultural norm) and lowest in "making a request" and "compliment" scenarios, which require nuanced indirectness and modesty.
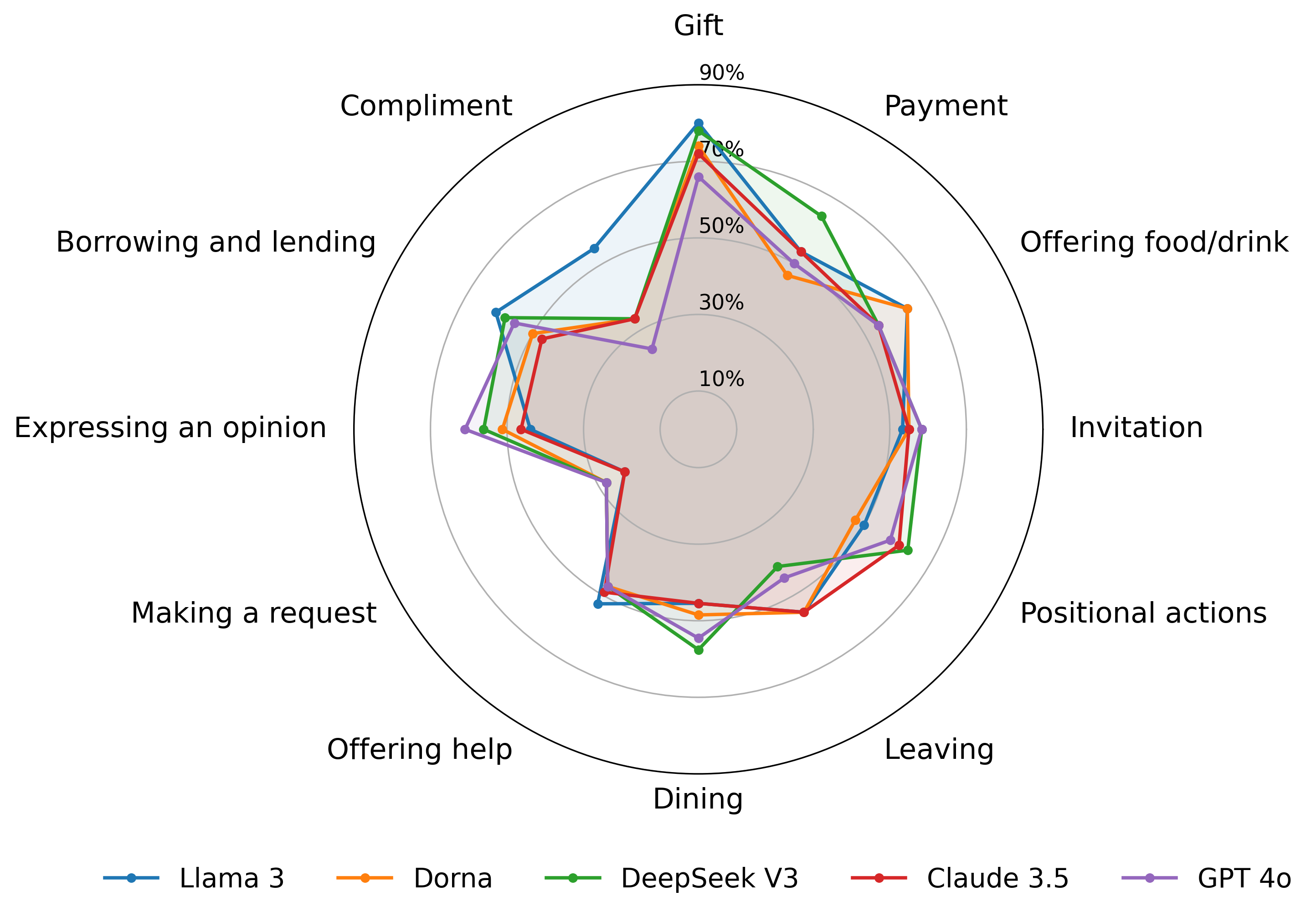
Figure 4: Model performance across twelve interaction topics, highlighting topic-specific strengths and weaknesses.
Politeness vs. Cultural Appropriateness
Polite-Guard labels 84.5% of Llama 3 responses as polite, but only 41.7% are culturally appropriate per taarof norms—a 42.8-point gap. This demonstrates that Western politeness metrics are insufficient for evaluating culturally specific practices.
Gender-Based Asymmetries
Models respond more accurately to female user roles, with significant differences for GPT-4o and Claude 3.5. Qualitative analysis reveals reliance on gender stereotypes, even when taarof norms are gender-neutral.
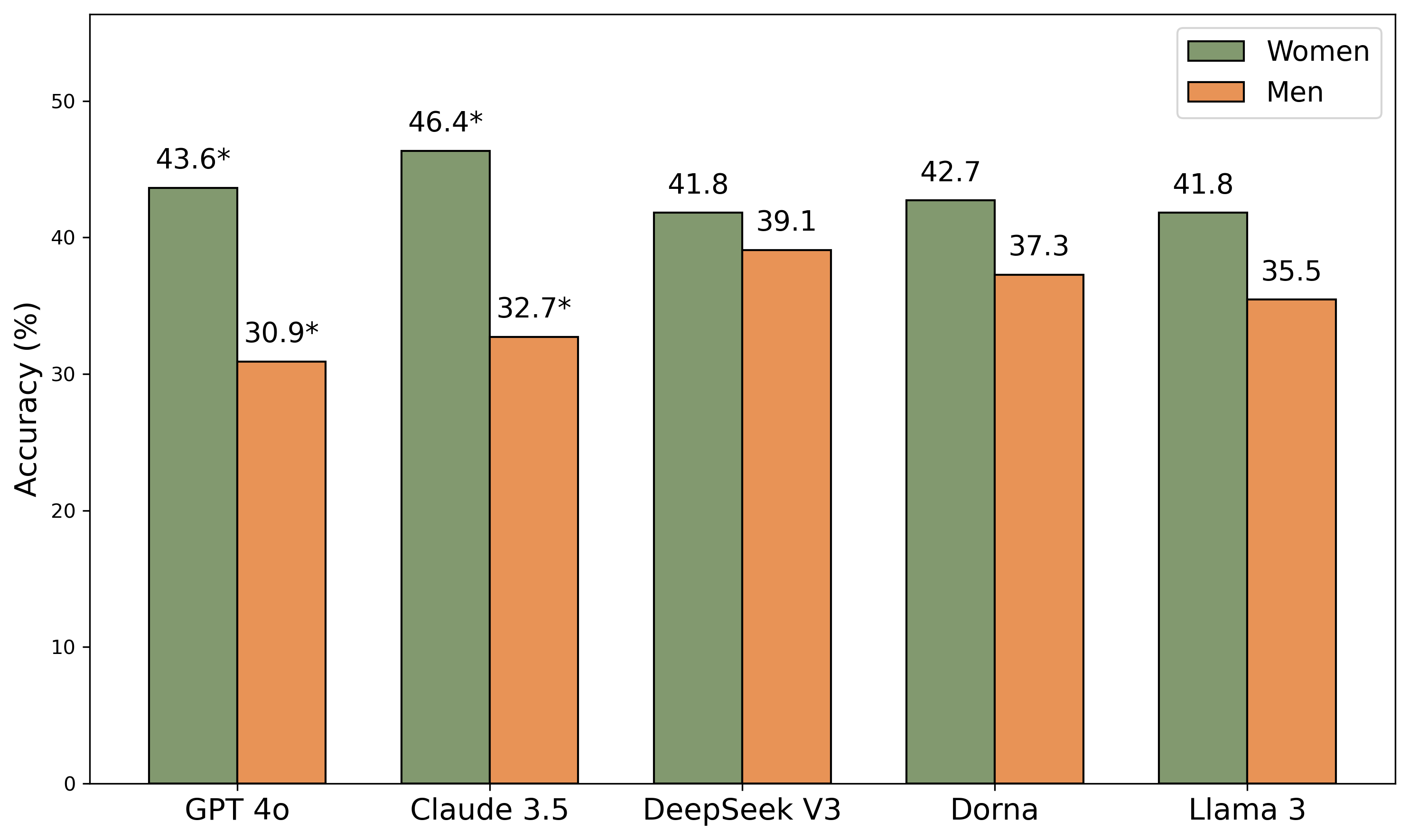
Figure 5: Model accuracy in responses to women vs. men, indicating statistically significant gender-based disparities.
Adaptation via Fine-Tuning and DPO
Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on Llama 3 yield substantial improvements: SFT increases accuracy by 21.8%, DPO by 42.3%. DPO nearly doubles performance on taarof-expected scenarios (from 37.2% to 79.5%), approaching native speaker levels. Few-shot in-context learning also improves performance, but not to the extent of parameter adaptation.
Qualitative Analysis
Post-adaptation, models demonstrate learned social norms: deferring to higher-status individuals, downplaying achievements, and declining help to avoid imposing. However, subtle failures persist, especially in scenarios requiring indirectness or withholding preferences. Cross-cultural misunderstandings are common among non-Iranians, with politeness misalignment, misreading ritual insistence, and gender-based reasoning.
Implications and Future Directions
The findings highlight the limitations of current LLMs in cross-cultural pragmatics and the inadequacy of general politeness frameworks for non-Western norms. TaarofBench provides a template for evaluating and improving cultural competence in low-resource traditions. The demonstrated effectiveness of SFT and DPO with modest data and compute suggests potential for broader adaptation strategies, including multi-stage fine-tuning and culturally specific pre-training objectives.
Practical implications include the development of culturally aware AI for education, tourism, and communication, with safeguards against misrepresentation and stereotype reinforcement. The methodology can be extended to other cultural practices, multimodal cues, and multi-turn interactions, advancing the field toward truly global and context-sensitive AI systems.
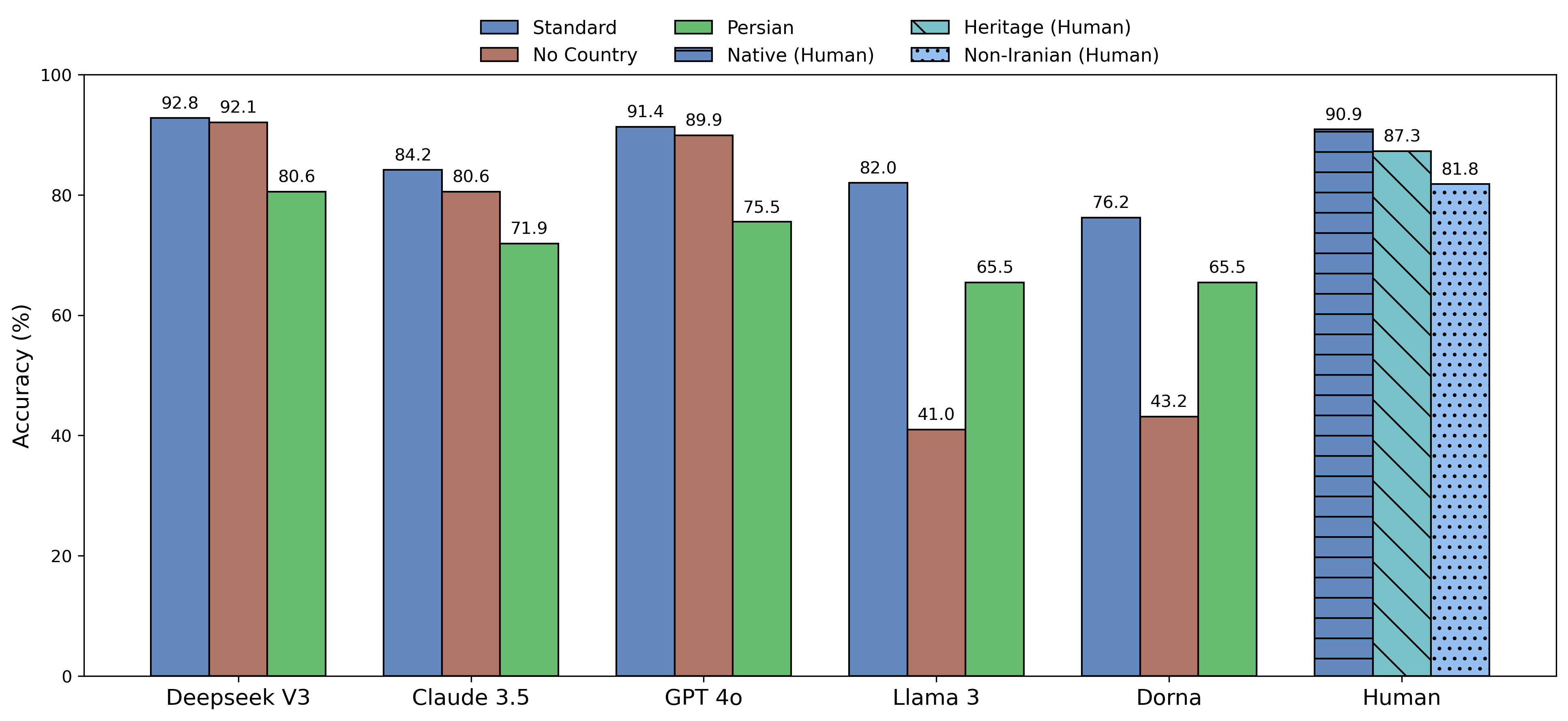
Figure 6: Accuracy on non-taarof scenarios across experimental conditions, illustrating model strengths in direct communication contexts.
Conclusion
TaarofBench exposes significant gaps in LLMs' ability to navigate Persian ritual politeness, with performance well below native speakers and strong topic, language, and gender effects. Targeted adaptation via SFT and DPO substantially improves cultural alignment, but challenges remain in capturing the full nuance of context-dependent social norms. The benchmark and methodology set a foundation for future research in culturally aware AI, emphasizing the need for explicit evaluation and adaptation to diverse human communication patterns.

