- The paper introduces a unified model (VoCap) that performs spatio-temporal segmentation and object-centric captioning from various prompts.
- VoCap integrates memory-augmented trackers with BERT-based caption modules, enhancing object tracking and caption accuracy in complex video scenes.
- The large-scale SAV-Caption dataset and multi-task training strategy enable VoCap to outperform baselines in segmentation and video captioning benchmarks.
VoCap: Unified Video Object Captioning and Segmentation from Any Prompt
Introduction
The VoCap framework introduces a unified approach for fine-grained video object understanding, enabling simultaneous spatio-temporal segmentation and object-centric captioning from flexible input prompts (text, mask, or box). This model addresses the lack of systems capable of both precise object localization and detailed semantic description in video, bridging tasks such as promptable video object segmentation, referring expression segmentation, and object captioning. VoCap leverages a large-scale pseudo-labeled dataset (SAV-Caption), generated via a novel visual prompting pipeline and Vision LLM (VLM) annotation, to overcome the data scarcity in this domain.
Model Architecture
VoCap's architecture is modular, integrating segmentation and captioning components to process videos frame-by-frame with object-specific memory. The segmentation pipeline is based on memory-augmented trackers (SAM2), while the captioning modules employ a shared BERT-based text encoder/decoder and a QFormer-style feature extractor. The model supports multi-modal prompts and outputs, enabling joint mask and caption prediction.
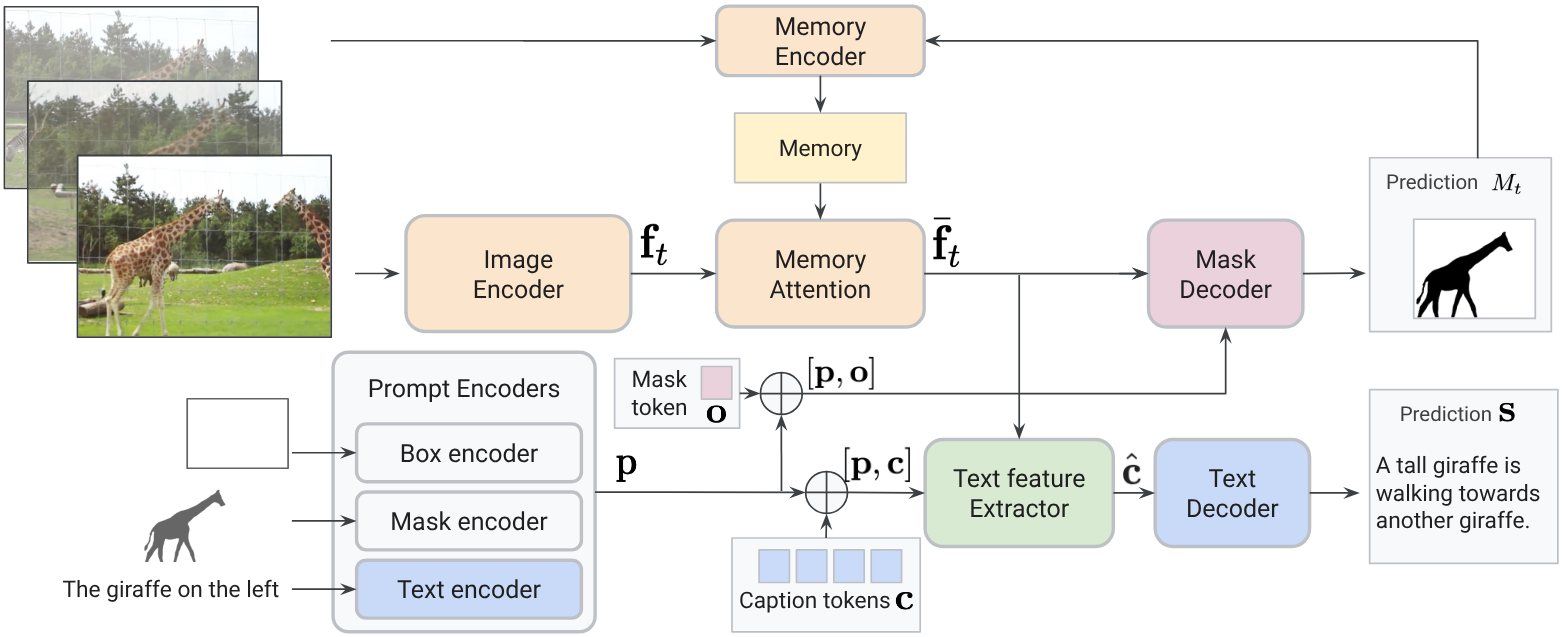
Figure 1: VoCap processes each video frame with an image encoder, cross-attends to object memory, and decodes masks and captions using shared text modules.
The image encoder (EVA02-L) extracts multi-scale features per frame. Temporal consistency is maintained via a memory bank, updated with per-frame mask predictions and image features. Location prompts (box/mask) and text prompts are encoded into embeddings, which condition the mask decoder. The mask decoder uses cross-attention to fuse image and prompt features, outputting binary masks and object appearance indicators. Captioning is performed by extracting object-aware features via learned caption tokens and cross-attention, followed by autoregressive decoding with a shared BERT transformer.
Visual Prompting and Pseudo-Labeling
To generate large-scale training data, VoCap employs a visual prompting strategy for VLM annotation. Target objects are highlighted with a red contour and the background is blurred, focusing the VLM's attention and reducing distractors. The textual prompt is structured to elicit object category, properties, and actions, resulting in high-quality, object-centric captions.


Figure 2: Visual prompting augments frames with red contours and blurred backgrounds to guide VLMs in object-centric caption generation.
This pipeline enables the creation of SAV-Caption, a dataset with over 50k videos and 170k object captions, an order of magnitude larger than previous datasets. Manual annotation on the validation set ensures unbiased evaluation.
Training and Multi-Task Learning
VoCap is trained in three phases: (i) modality-specific pretraining, (ii) multi-task joint training on diverse datasets (SAV-Caption, VisualGenome, RefCOCO, RefVOS-YTVOS), and (iii) dataset-specific finetuning. The model leverages partial annotations, supporting mask-to-text, text-to-mask, and box-to-text tasks. Training is performed in JAX, with EVA02-L as the visual backbone and a 6-layer BERT for language modules. The multi-task phase utilizes a data mixture ratio to balance captioning and segmentation objectives.
Experimental Results
Video Object Captioning
VoCap establishes a new benchmark for video object captioning, outperforming strong baselines such as SAM2+BLIP2 and SAM2+Gemini pseudo-labeling. On SAV-Caption-val, VoCap achieves 47.8 CIDEr, surpassing SAM2+Gemini (40.5 CIDEr) and image-based models (BLIP2: 21.9 CIDEr, PixelLLM: 35.5 CIDEr). The model demonstrates robustness to small objects and actor bias, consistently describing the tracked object.
Localized Image Captioning
On VisualGenome, VoCap achieves 163 CIDEr, outperforming GRiT (142), PixelLLM (149), and SCA (150), demonstrating its generalization to image-level tasks with box prompts.
Video Object Segmentation
VoCap matches or exceeds state-of-the-art performance in semi-supervised (SS-VOS) and referring expression (RefVOS) video object segmentation. On YTVOS 2018, VoCap achieves 85.0 J&F, matching SAM2 and outperforming UniRef++ (83.2) and GLEE (80.4). On MOSE (zero-shot), VoCap yields 66.3 J&F, significantly higher than UniRef++ (59.0) and GLEE (56.1). For RefVOS, VoCap + FindTrack achieves top results across all datasets, with notable improvements on MeViS (+4.8%), RefVOS-YTVOS (+0.9%), RefVOS-DAVIS (+0.5%), and UVO-VLN (+16.5%).
Ablation Studies
Ablation on SAV-Caption training data reveals its critical role: removing SAV-Caption reduces captioning performance from 47.8 to 27.4 CIDEr and segmentation from 75.5 to 57.7 J&F. The synergy between captioning and segmentation tasks is evident, with joint training improving both modalities.
Qualitative Analysis
VoCap demonstrates superior object tracking and captioning, especially for small objects and in the presence of nearby actors. Gemini-based pseudo-labeling often misattributes actions or fails on small objects, while VoCap maintains object-centric descriptions.


Figure 3: Qualitative comparison showing VoCap's accurate object-centric captions versus Gemini's actor-biased or incorrect outputs.
Implications and Future Directions
VoCap's unified framework for promptable video object segmentation and captioning advances fine-grained spatio-temporal video understanding. The scalable pseudo-labeling pipeline addresses data bottlenecks, enabling large-scale training. The model's flexibility in input/output modalities and strong performance across tasks suggest applicability in video editing, autonomous systems, and wildlife monitoring. Future work may explore further scaling, integration with more expressive LLMs, and extension to multi-object and relational captioning.
Conclusion
VoCap presents a unified, promptable model for video object segmentation and captioning, leveraging large-scale pseudo-labeled data and multi-task training. It achieves state-of-the-art results in referring expression segmentation and competitive performance in semi-supervised segmentation and captioning. The framework and dataset provide a foundation for future research in fine-grained video understanding.