- The paper demonstrates that integrating SLAC's SNL with Rogue Software and Auto-SNL achieves ultra-low-latency FPGA inference.
- It presents a detailed benchmark showing SNL’s superior latency performance compared to hls4ml across various models.
- It highlights dynamic weight reloading and automated HLS code generation as key enablers for real-time experimental adaptation.
Neural Network Acceleration on MPSoC Board: Integrating SLAC's SNL, Rogue Software and Auto-SNL
Introduction
This paper presents a comprehensive framework for accelerating neural networks on FPGA platforms, specifically the Xilinx ZCU102 board. The framework utilizes the SLAC Neural Network Library (SNL), which is designed for ultra-low-latency inference by leveraging the dynamic reconfiguration capabilities of FPGAs. Auto-SNL, a Python extension, facilitates the conversion of high-level neural network models into SNL-compatible high-level synthesis (HLS) code, thereby lowering the barrier for deploying machine learning models in high-rate environments such as the Linac Coherent Light Source II (LCLS-II). The paper provides a detailed benchmark comparison against the widely used hls4ml toolchain, focusing on latency and resource utilization across various network architectures and precisions.
SNL and Auto-SNL Workflow with SLAC's Rogue Software
SNL efficiently deploys neural networks into the programmable logic of FPGAs. As illustrated in (Figure 1), SNL's workflow is optimized for edge inference in real-time experimental setups. A key attribute is the dynamic reloading of model weights and biases without necessitating FPGA resynthesis, which is particularly advantageous for adaptive scientific experiments demanding frequent updates.
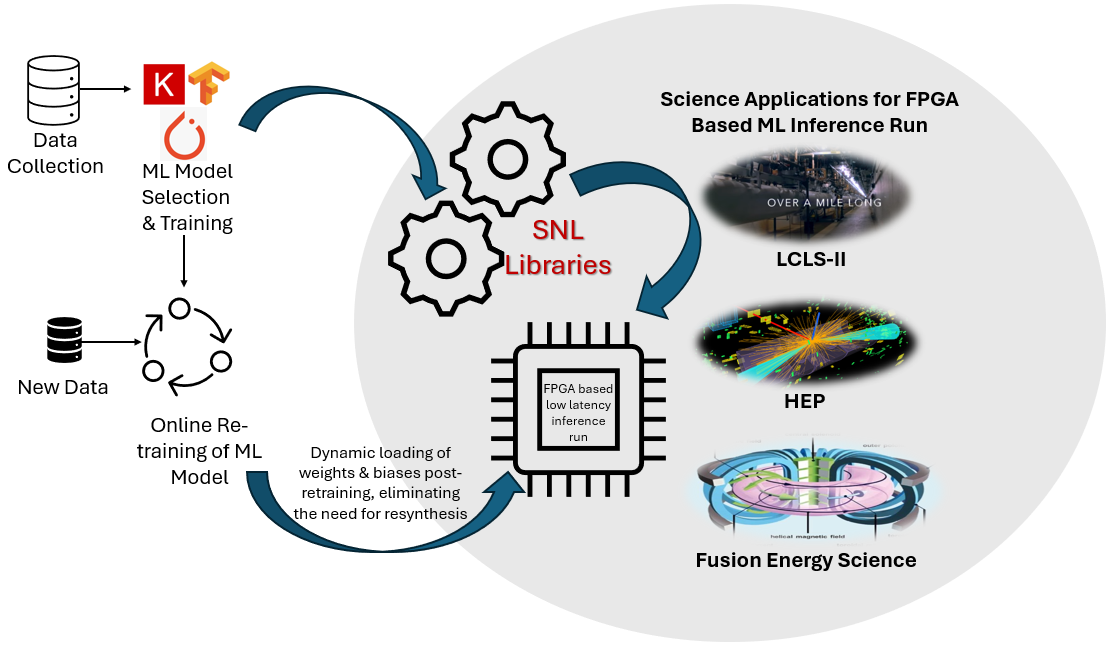
Figure 1: High-level view of SNL's workflow.
To enhance usability, Auto-SNL automates converting Python-defined models into SNL-compatible HLS code. The process, depicted in (Figure 2), allows for seamless integration from high-level frameworks like Keras directly to FPGA deployment, abstracting FPGA toolchain intricacies. This enables fine-tuning of hardware parameters like data types and clock periods to align with specific experimental needs.
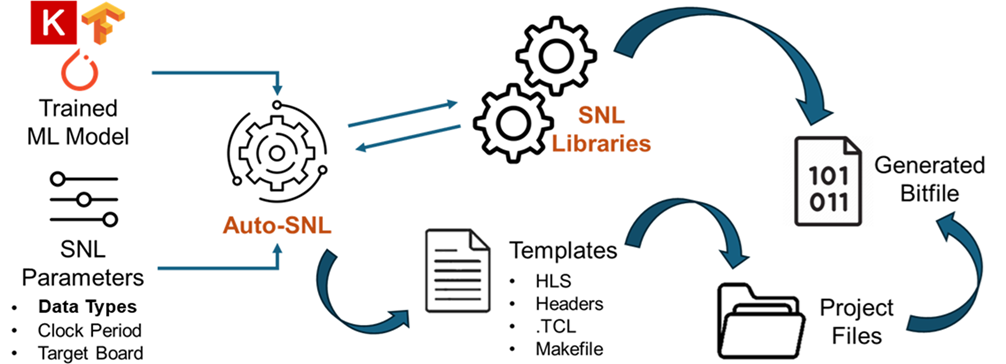
Figure 2: Auto-SNL conversion and implementation workflow.
Figure 3 showcases SNL's deployment strategy on the ZCU102 board, integrating hardware (PL), software (SNL), and Rogue design flow to ensure efficient real-time neural network inference for scientific applications. This pipeline is optimized for maximal throughput and minimal latency, utilizing a combination of AXI-Lite and AXI-Stream protocols with a direct memory access engine for fast data transfers.
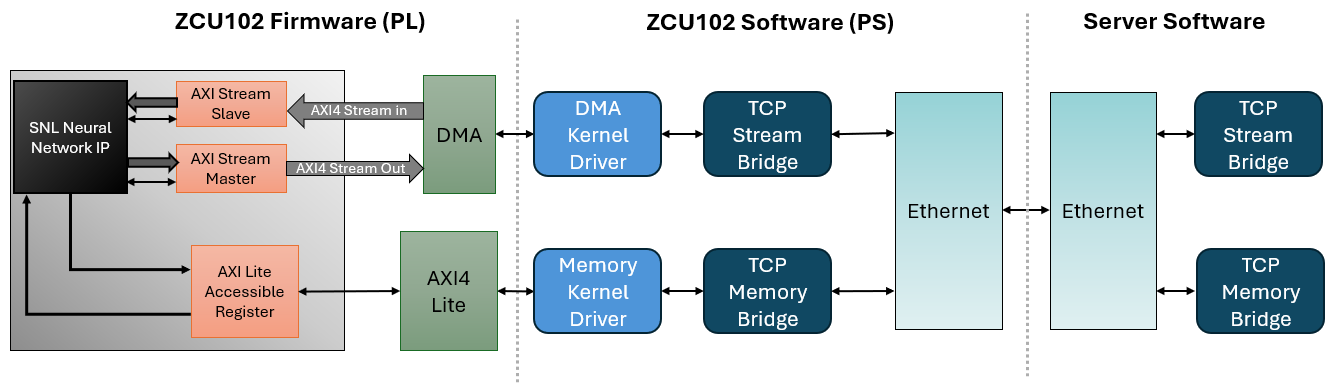
Figure 3: SNL's workflow for NN Deployment on ZCU102: Hardware (PL) -- Software (SNL) -- Rogue design flow.
Workflow for Deployment and Inference on the ZCU102 using hls4ml
The hls4ml toolchain, depicted in Figure 4, offers an alternative approach, emphasizing flexibility and configurability through parameters such as IO type, strategy, and reuse factor. Unlike SNL, hls4ml embeds weights and biases during synthesis, necessitating resynthesis for any updates. This impacts runtime flexibility but provides granulated control over resource and latency trade-offs.
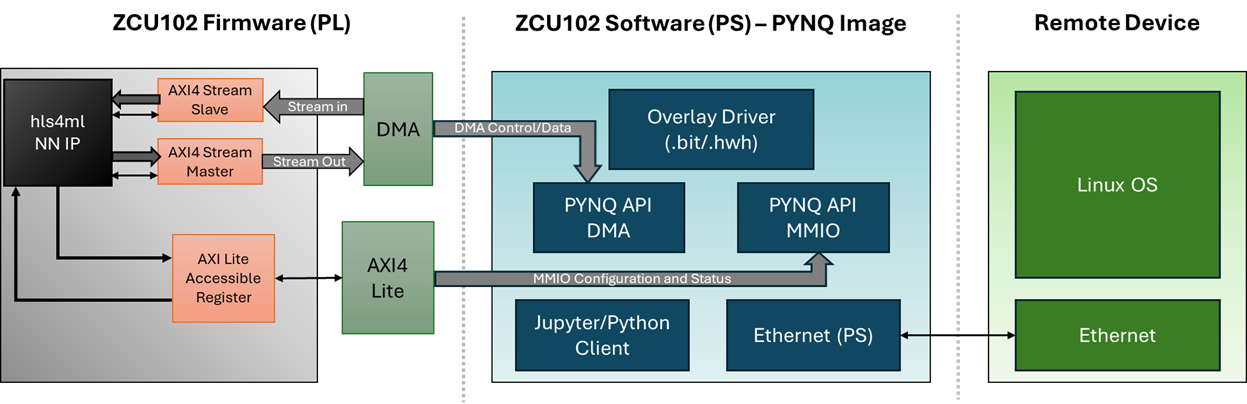
Figure 4: Standard hls4ml workflow for a streaming-based NN deployment on a ZCU102 running a PYNQ image.
Benchmarking
The benchmarking process involved comparing SNL and hls4ml across various neural network architectures, presented in Table 1. The focus was on assessing latency and resource utilization, with precision, synthesis strategy, and reuse factor as variable parameters. Results demonstrated that SNL often achieves lower latency but may require more resources such as BRAM and FFs compared to hls4ml, which benefits from fine-grained control over these parameters.
Table 1: Benchmark Task Summary
| Model |
Dataset |
Input Size |
Task |
Performance |
| Jet |
LHC Jet |
(16,) |
Classification |
74.90% |
| Anomaly |
ToyADMOS |
(320,) |
Detection |
0.70 (AUC) |
| KWS |
Speech Commands |
(32, 32, 1) |
Classification |
59.33% |
| VWW |
Visual Wake Words |
(49, 10, 1) |
Classification |
70.14% |
Results
Figures 5 and 6 illustrate resource utilization and latency respectively, across different models and synthesis configurations. Notably, SNL demonstrated superior latency performance in three out of the four architectures tested, while often incurring higher resource usage compared to hls4ml. These findings indicate that while SNL prioritizes fast inference, hls4ml provides better resource efficiency under constrained settings.

Figure 5: Resource utilization across models and different synthesis parameters, comparing SNL (bars with shading) and hls4ml.
Figure 6: Absolute latency across models and different synthesis parameters, comparing SNL (bars with shading) and hls4ml.
Discussion
The benchmarking highlights SNL's strength in achieving low-latency inference, essential for high-rate experimental environments. However, the trade-off in resource utilization suggests avenues for future optimization. By contrast, hls4ml offers flexibility via synthesis parameters, allowing for more adaptable trade-offs between resource usage and latency.
Conclusion
The integration of SNL, Auto-SNL, and SLAC's Rogue software provides a robust framework for FPGAs in high-speed scientific applications. While SNL excels in latency performance, future work should focus on enhancing its resource efficiency. Continued development of Auto-SNL will further democratize FPGA deployment by simplifying model translation and allowing for seamless adaptation to new hardware platforms and evolving ML frameworks.