- The paper demonstrates that optimized synthetic data generation via enhanced TTS pipelines significantly reduces WER in ASR systems.
- It employs a two-phase methodology, combining target domain finetuning and Generator-Verifier filtering to ensure high linguistic fidelity.
- Combining synthetic with real data notably improves ASR performance in spontaneous Québec French while addressing data scarcity challenges.
Towards Improved Speech Recognition through Optimized Synthetic Data Generation
Introduction
The paper "Towards Improved Speech Recognition through Optimized Synthetic Data Generation" investigates the application of synthetic data to improve Automatic Speech Recognition (ASR) systems, specifically in confidential data scenarios. The authors leverage advanced Text-to-Speech (TTS) capabilities to generate synthetic data that mimics conversational French as spoken in Québec. This approach addresses the scarcity of annotated data within domains that maintain highly confidential recordings, such as healthcare and banking.
Synthetic data has been used in ASR as a data augmentation strategy. Previous works have demonstrated that combining real and synthetic data can match or even surpass performance metrics derived from real data alone. While many studies emphasize synthetic data's effectiveness in controlled environments, the paper focuses on spontaneous speech scenarios, extending this concept to underrepresented languages like Québec French. This focus differentiates the study from traditional ASR research, which primarily deals with standard language variants under clean conditions.
Methodology
The study employs two phases: the optimization of synthetic speech quality and the evaluation of ASR systems trained on these datasets. The methodology is visually summarized below.

Figure 1: Top: Phase 1. Optimization of synthetic quality. Bottom: Phase 2. Speech recognition evaluation. Red indicates target domain data, blue out-of-domain data, and green, LLM-generated data.
Phase 1 involves optimizing a TTS pipeline using both target domain text and voice samples. This phase introduces finetuning methods and quality filtering mechanisms such as Generator-Verifier (G-V) filtering, which reduces error rates in generated audio by ensuring linguistic fidelity.
Phase 2 evaluates the ASR performance using exclusively synthetic data, as well as combined datasets consisting of real and synthetic data. This phase explores ASR models by varying the proportion of synthetic data, employing metrics like Word Error Rate (WER) as a primary evaluation criterion.
Experimental Setup and Result Analysis
Datasets: The study uses CommissionsQC datasets, focusing on Bast and Charb corpora which contain spontaneous, conversational speech.
Finetuning and Filtering: The authors refine a general-purpose TTS model to accommodate dialectal characteristics of Québec French. Finetuning results in significant performance enhancements, with G-V filtering yielding substantial WER reductions.
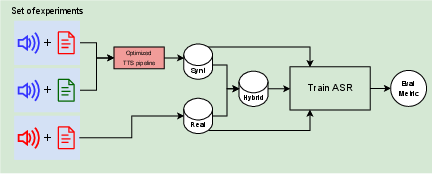
Figure 2: Generator-Verifier based filtering.
ASR Training: Multiple training datasets were produced, involving various combinations of synthetic and real data. An end-to-end transformer-based ASR model was evaluated to benchmark ASR performance across different training configurations.
Key Outcomes: The findings indicate that synthetic data alone cannot fully substitute for real data, particularly in ASR applications requiring high accuracy. However, when paired with even minimal amounts of real data, synthetic datasets effectively mitigate data scarcity, improving overall model performance.
Synthetic Text Generation
An innovative aspect of the study involves generating textual inputs via LLMs to create synthetic speech in scenarios devoid of original text or audio data. The use of GPT-4-based models allowed effective text generation that mimicked the characteristics of the target domain data.
Figure 3: Synthetic text generation pipeline.
Implications and Future Directions
The paper concludes by emphasizing the potential of synthetic data as a means to reduce reliance on real-world data in ASR systems, especially in sensitive contexts. Despite the advancements, the gap in quality between synthetic and real data suggests future research should explore diverse TTS architectures and alternative quality assessment techniques, such as embedding-based clustering.
The authors also highlight the ethical considerations of voice cloning and data privacy, stressing the need for informed consent when employing synthetic generation techniques.
Conclusion
While synthetic data generation poses promising advancements for ASR systems, this study confirms that its optimal application typically involves some level of real data for best results. Ongoing innovation in this area may further enhance ASR capabilities, lending insight into broader AI applications across diverse linguistic and contextual scenarios.

