- The paper presents a balanced, human-annotated Marathi STS dataset with 16,860 sentence pairs labeled across uniformly distributed similarity buckets.
- It introduces MahaSBERT-STS-v2, a fine-tuned Sentence-BERT model with MEAN pooling, outperforming multilingual baselines with Pearson 0.9600 and Spearman 0.9523.
- The findings emphasize that targeted, monolingual training and structured supervision improve semantic similarity tasks in low-resource languages like Marathi.
L3Cube-MahaSTS: A Human-Annotated Marathi Sentence Similarity Dataset and Models
Introduction
The paper presents L3Cube-MahaSTS, a large-scale, human-annotated Semantic Textual Similarity (STS) dataset for Marathi, alongside MahaSBERT-STS-v2, a fine-tuned Sentence-BERT model optimized for regression-based similarity scoring. The work addresses the paucity of high-quality, labeled resources for Marathi, a low-resource Indic language, and demonstrates the efficacy of targeted fine-tuning and structured supervision for sentence similarity tasks. The dataset and models are made publicly available, facilitating further research and practical deployment in Marathi NLP.
Dataset Curation and Annotation
MahaSTS comprises 16,860 sentence pairs, each labeled with a continuous similarity score in the range 0–5. The annotation protocol employs six uniformly distributed buckets, each containing 2,810 pairs, to mitigate label bias and promote stable regression learning. The buckets are defined as follows:
- Bucket 0: No semantic similarity
- Bucket 1: Minimal similarity (0.1–1.0)
- Bucket 2: Partial thematic overlap (1.1–2.0)
- Bucket 3: Moderate similarity (2.1–3.0)
- Bucket 4: High similarity (3.1–4.0)
- Bucket 5: Near or full equivalence (4.1–5.0)
Sentence pairs were sourced from the L3Cube-MahaCorpus (1M sentences), filtered for quality, and paired using cosine similarity of MahaSBERT-STS embeddings. Human annotators refined the labels, discarding incomplete or nonsensical pairs, resulting in a balanced and high-quality dataset.
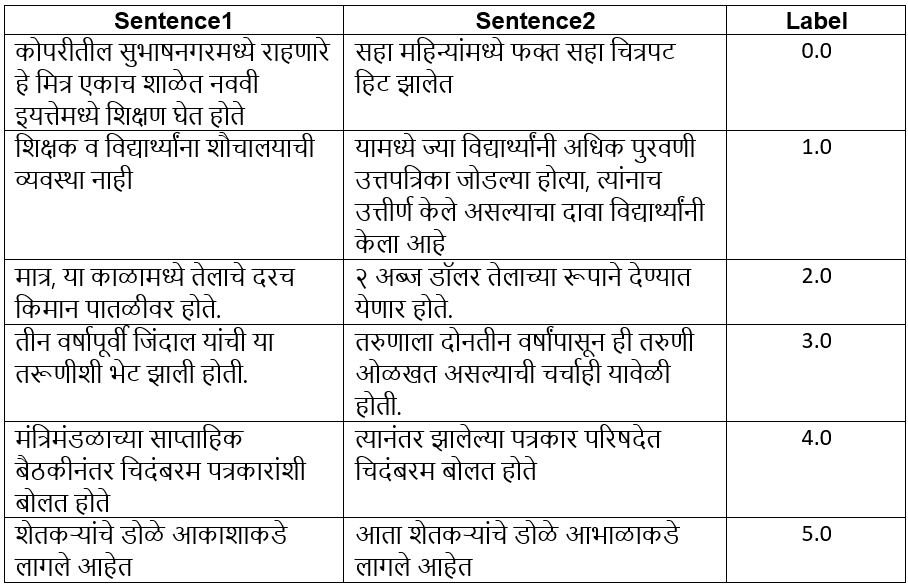
Figure 1: Examples of sentence pairs with labels in the range 0–5 from the L3Cube-MahaSTS dataset.
The dataset is split into train (85%), test (10%), and validation (5%) sets, maintaining bucket uniformity across splits. This design ensures robust evaluation and minimizes overfitting to specific similarity levels.
Model Architectures and Training
The primary model, MahaSBERT-STS-v2, is a Sentence-BERT variant for Marathi, initialized from MahaSBERT (trained on IndicXNLI) and fine-tuned on MahaSTS. The training regimen utilizes CosineSimilarityLoss, AdamW optimizer, a learning rate of 1×10−5, batch size 8, and MEAN pooling over token embeddings. Training is conducted for 2 epochs.
Baseline models include:
- MahaBERT: Marathi BERT, fine-tuned on monolingual corpora.
- MuRIL: Multilingual BERT for 17 Indian languages.
- IndicBERT: Multilingual ALBERT for 12 Indic languages.
- IndicSBERT: Sentence-BERT for 10 Indic languages, fine-tuned on NLI.
Pooling strategies (CLS, MEAN, MAX) are systematically evaluated, with MEAN pooling yielding the highest correlation with human judgments.
Experimental Results
On the MahaSTS test set, MahaSBERT-STS-v2 achieves a Pearson correlation of 0.9600 and Spearman correlation of 0.9523, outperforming all baselines. The results substantiate the claim that monolingual, task-specific fine-tuning is superior to multilingual or generic approaches for sentence similarity in Marathi.
Key findings:
- MahaSBERT-STS-v2 (MEAN pooling): Pearson 0.9600, Spearman 0.9523
- MahaBERT: Pearson 0.9483, Spearman 0.9386
- MuRIL: Pearson 0.9361, Spearman 0.9267
- IndicSBERT: Pearson 0.9515, Spearman 0.9441
- IndicBERT: Pearson 0.7311, Spearman 0.7004
Pooling strategy analysis reveals MEAN pooling as optimal, with CLS and MAX pooling trailing slightly in performance.
Discussion
The results demonstrate that human-annotated, balanced datasets are critical for robust semantic similarity modeling in low-resource languages. The uniform bucket distribution in MahaSTS reduces label bias, enabling stable regression and generalization. The superiority of MahaSBERT-STS-v2 over multilingual models corroborates prior findings in other languages, emphasizing the value of monolingual, domain-specific pretraining and fine-tuning.
The dataset's design and annotation protocol facilitate nuanced semantic modeling, capturing a spectrum from complete dissimilarity to near equivalence. However, the model's generalization to longer or more complex sentences remains limited, a common issue in SBERT architectures for Indic languages. Addressing this requires future datasets with greater syntactic and semantic diversity.
Practical and Theoretical Implications
Practically, MahaSTS and MahaSBERT-STS-v2 enable high-fidelity semantic similarity estimation for Marathi, supporting downstream tasks such as RAG, IR, QA, paraphrase detection, and clustering. The public release of the dataset and models lowers the barrier for Marathi NLP research and deployment.
Theoretically, the work reinforces the importance of structured supervision and balanced annotation in regression-based NLP tasks. It also highlights the limitations of cross-lingual transfer and machine translation for semantic tasks in culturally rich, low-resource languages.
Future Directions
Potential avenues for future research include:
- Expansion of MahaSTS to cover longer, more complex sentences and diverse domains.
- Exploration of contrastive learning and advanced pooling strategies for improved sentence representations.
- Cross-lingual transfer experiments leveraging MahaSTS for other Indic languages.
- Integration of MahaSBERT-STS-v2 into large-scale retrieval and generation pipelines for Marathi.
Conclusion
L3Cube-MahaSTS establishes a new benchmark for semantic textual similarity in Marathi, providing a balanced, human-annotated dataset and a high-performing, fine-tuned SBERT model. The work demonstrates that targeted, monolingual fine-tuning on carefully curated data yields superior results in low-resource settings. The dataset and models are poised to accelerate research and practical applications in Marathi NLP, with implications for other Indic languages and low-resource domains.