- The paper introduces BED-LLM, which maximizes expected information gain using sequential Bayesian experimental design combined with LLMs for adaptive multi-turn querying.
- It employs a joint probabilistic model and a sample–then–filter belief update to maintain historical consistency and mitigate mode collapse.
- Experimental results show BED-LLM significantly outperforms baselines in 20–Questions and user preference elicitation tasks, achieving up to 95% success rates.
Introduction and Motivation
The paper introduces BED-LLM, a principled framework for enabling LLMs to perform adaptive, multi-turn information gathering by leveraging sequential Bayesian experimental design (BED). The motivation stems from the observation that while LLMs can generate coherent questions in one-shot settings, they often fail to adaptively tailor queries based on previously collected responses, limiting their effectiveness in interactive tasks such as multi-step guessing games, user preference elicitation, and iterative tool use. BED-LLM addresses this by formulating information gathering as a sequential experimental design problem, iteratively selecting queries that maximize expected information gain (EIG) about a latent target θ.
Sequential Bayesian Experimental Design for LLMs
BED-LLM operationalizes sequential BED in the LLM context by constructing a joint probabilistic model over hypotheses θ and outcomes y given queries x. The framework iterates over four key steps:
- Candidate Question Generation: Propose a diverse set of candidate questions using the LLM, either via unconstrained sampling or conditional generation based on a pool of candidate hypotheses.
- EIG Estimation: For each candidate, estimate the EIG using a Rao-Blackwellized Monte Carlo estimator, leveraging the LLM's logits for entropy calculations.
- Optimal Question Selection: Select and pose the question with maximal EIG, observe the response, and update the history.
- Belief State Update: Update the joint model by filtering sampled hypotheses for compatibility with the observed history, mitigating mode collapse and ensuring historical coherence.
This approach is distinguished by its use of a prior–likelihood pairing for joint model construction, careful filtering of hypotheses, and explicit avoidance of predictive entropy as a proxy for EIG.
Model Construction and Updating
A central technical challenge is constructing a faithful joint model from the LLM. The prior–likelihood pairing (p(θ)p(y∣[θ,x])) is preferred when the hypothesis space θ is more complex than the outcome space y, as is typical in open-ended tasks. Belief updating is performed via a sample–then–filter strategy: hypotheses are sampled from the in-context LLM distribution and rejected if incompatible with the history, with diversity encouraged through high-temperature sampling and batch generation. This approach avoids the computational intractability of full Bayesian updates and the inadequacy of naive in-context learning, which often fails to enforce historical consistency.
EIG Estimation and the Pitfalls of Predictive Entropy
The paper rigorously demonstrates that predictive entropy is not a suitable surrogate for EIG in adaptive information gathering. The expected conditional entropy of the likelihood varies across questions, and omitting it leads to selection of ambiguous or uninformative queries. The Rao-Blackwellized estimator directly utilizes LLM logits for entropy calculations, yielding lower variance and more faithful information gain estimates.
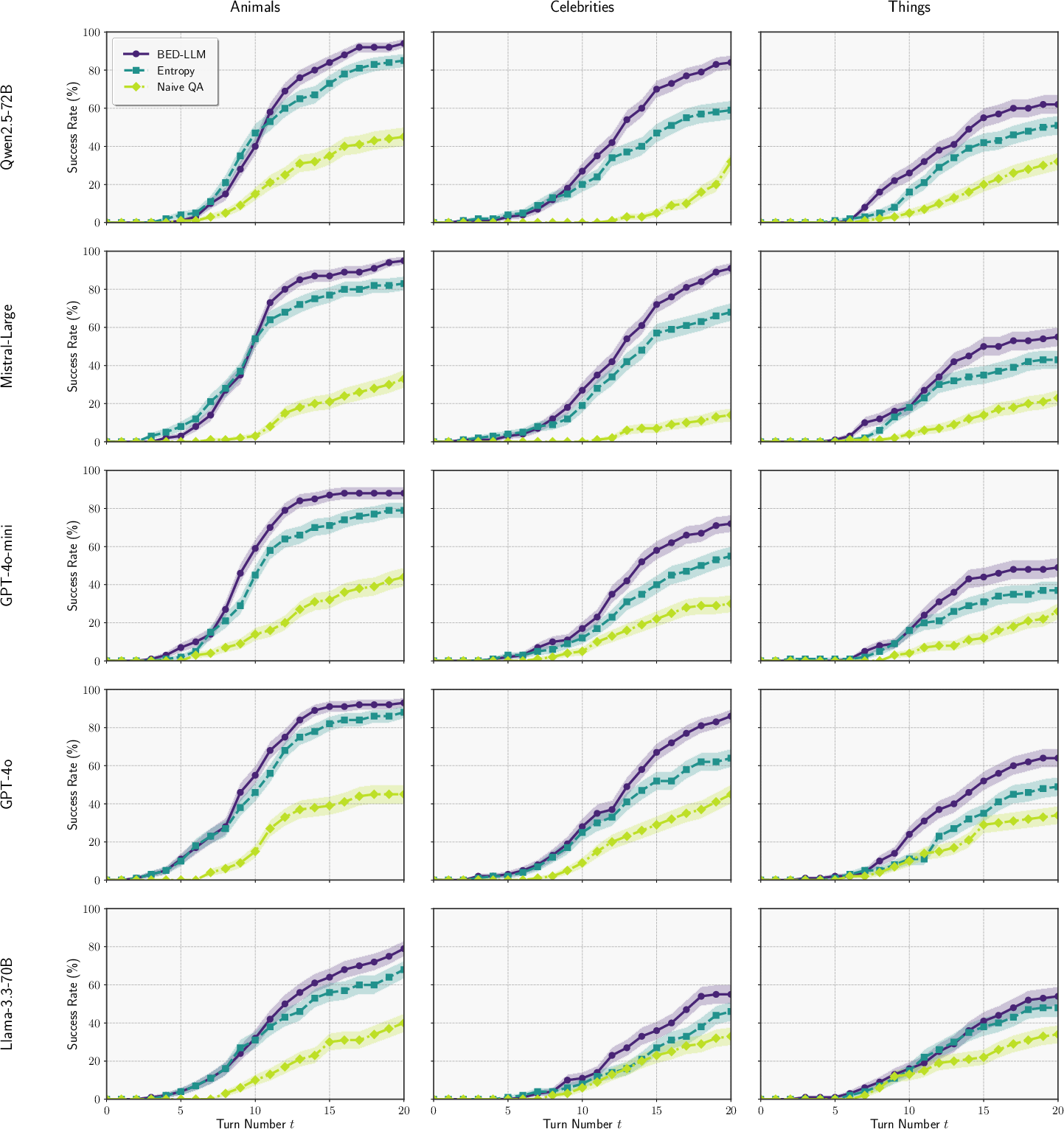
Figure 1: Success rate against turn for the 20--Questions game. Error bars represent the standard error of the mean estimate across 100 target entities in each dataset. The same model used as both questioner and answerer.
Experimental Evaluation
BED-LLM is evaluated on two tasks: the 20–Questions game and active user preference elicitation. In 20–Questions, the hypothesis space is unconstrained, and the questioner must identify a hidden target entity via binary queries. BED-LLM consistently outperforms both the Entropy baseline (predictive entropy maximization) and Naive QA (direct LLM question generation), achieving success rates up to 95% (Mistral-Large, Animals dataset), compared to 14–45% for Naive QA and 43–88% for Entropy. The advantage of BED-LLM becomes pronounced after several turns, as the effect of principled EIG-driven question selection accumulates.
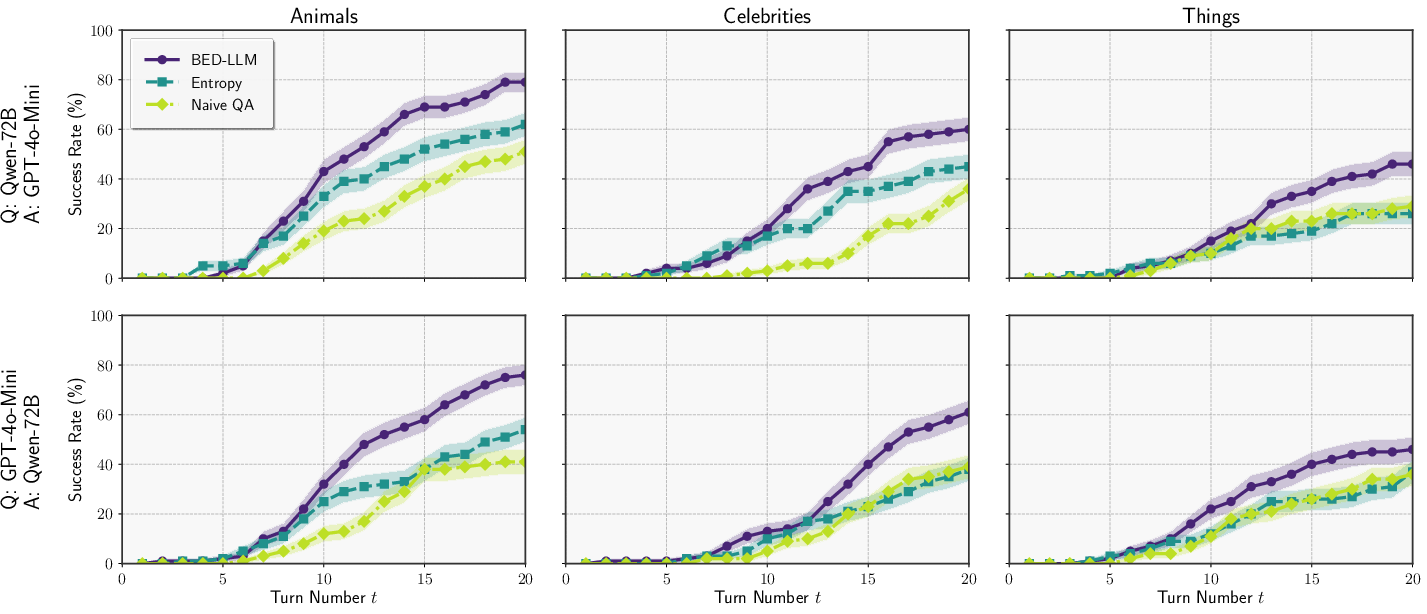
Figure 2: Success rates for the 20--Questions game with different models: the questioner Q and answerer A.
Robustness to model misspecification is demonstrated by using different LLMs for the questioner and answerer, with BED-LLM maintaining superior performance relative to baselines.
In active preference elicitation, where θ is a free-form user persona, BED-LLM again outperforms baselines in recommending films aligned with user preferences, as measured by LLM-as-judge ratings. The framework is shown to be robust to both model misspecification and the increased complexity of the hypothesis space.
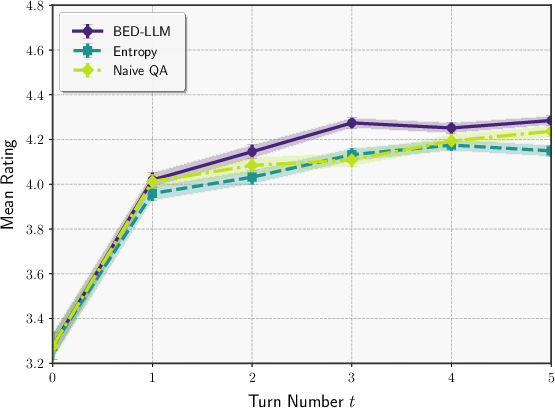
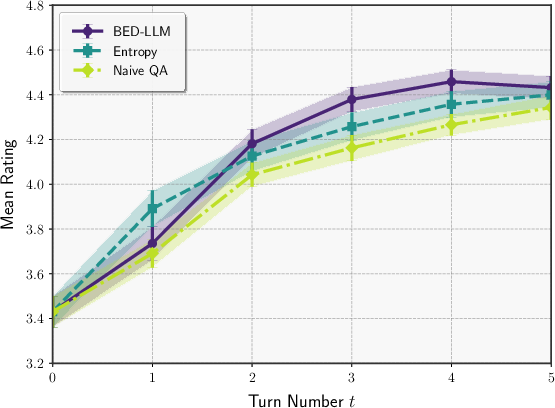
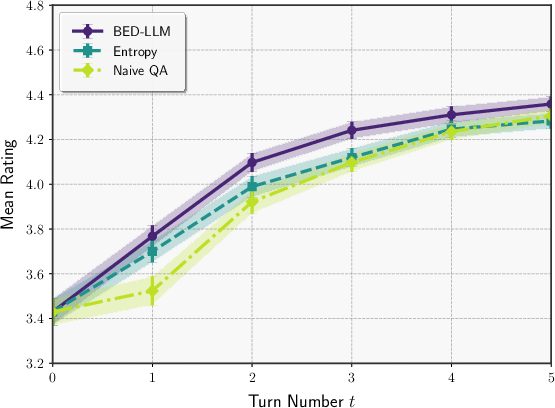
Figure 3: Qwen2.5-72B model performance in active preference elicitation.
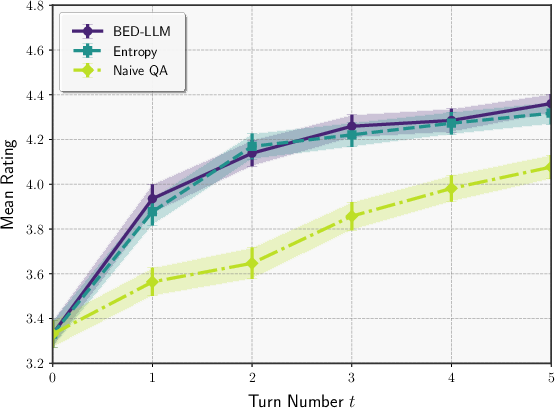
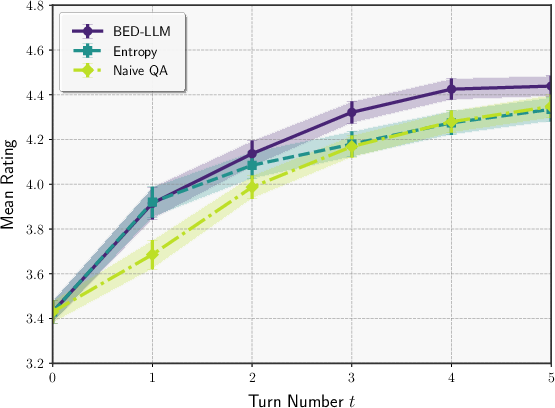
Figure 4: Cross-model evaluation: Qwen2.5-72B as questioner, GPT-4o-mini as answerer.
Ablations and Theoretical Insights
Ablation studies confirm the superiority of the prior–likelihood pairing over data–estimation pairings, especially in large or unbounded hypothesis spaces. The sample–then–filter updating procedure is shown to be critical for maintaining historical consistency and avoiding premature mode collapse. Theoretical analysis clarifies that the choice of joint model factorization should be guided by the relative complexity of θ and y, and by the intended belief updating procedure.
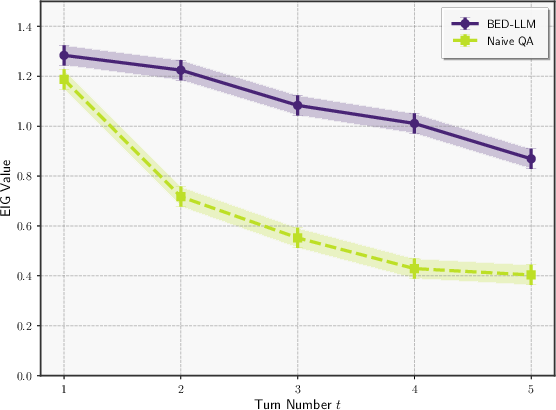
Figure 5: The average information gains for each strategy at each turn for the Qwen2.5-72B vs Qwen2.5-72B example. Initial questions have similar information gains, but EIG gains become much larger in later turns, explaining the superior performance of BED-LLM.
Implications and Future Directions
BED-LLM demonstrates that principled, information-theoretic strategies can substantially improve the adaptive information gathering capabilities of LLMs, enabling more effective multi-turn conversational agents and interactive systems. The framework is broadly applicable to domains such as medical diagnostics, personalized tutoring, automated surveys, and scientific discovery, where adaptive querying is essential. The results highlight the importance of careful joint model construction, robust belief updating, and faithful EIG estimation.
Future work may explore policy-based BED approaches for non-myopic planning, integration with external simulators for scientific applications, and extensions to richer interaction modalities (e.g., document retrieval, function calling). Further research into improving LLM uncertainty quantification and belief state extraction will enhance the reliability and applicability of BED-LLM in real-world deployments.
Conclusion
BED-LLM provides a rigorous, general-purpose framework for adaptive information gathering with LLMs, grounded in sequential Bayesian experimental design. By maximizing expected information gain through principled joint model construction and robust belief updating, BED-LLM achieves substantial gains over existing baselines in both deductive reasoning and user preference elicitation tasks. The approach sets a new standard for interactive intelligence in LLMs and opens avenues for future research in adaptive, multi-turn AI systems.