- The paper introduces a hierarchical embedding tree that clusters similar prompts, enabling sharing of early denoising steps.
- It leverages a training-free adaptive selection strategy to balance compute savings and image quality across models.
- Empirical results show up to 74% compute reduction, with improved or maintained image quality on diverse datasets.
Efficient Multi-Prompt Generation in Text-to-Image Diffusion via Hierarchical Embedding Reuse
Introduction and Motivation
Text-to-image diffusion models have become central to creative workflows, enabling high-fidelity image synthesis from textual prompts. However, their iterative denoising process incurs substantial computational cost, especially when generating large sets of images for prompt exploration or batch ideation. While prior work has focused on per-inference acceleration (e.g., distillation, improved solvers), this paper introduces a method for reducing redundancy across correlated prompts by reusing computation in early diffusion steps. The approach leverages the coarse-to-fine nature of diffusion models, where early denoising steps capture shared low-frequency structure among similar prompts, and later steps refine high-frequency details.
Hierarchical Embedding Tree Construction
The core of the method is a training-free, automatic pipeline that organizes prompts into a hierarchical tree via agglomerative clustering of their text embeddings. Each node in the tree represents the mean embedding of its children, and a heterogeneity score quantifies semantic diversity within the node. This structure enables efficient sharing of denoising steps: early steps use embeddings from higher-level (more generic) nodes, while later steps specialize to leaf (prompt-specific) embeddings.

Figure 1: Tree traversal for hierarchical embedding reuse, showing how early denoising steps are shared across similar prompts and gradually diverge to prompt-specific embeddings.
The embedding tree is constructed as follows:
- Encode all prompts into latent vectors.
- Iteratively merge the closest clusters (by cosine similarity of mean embeddings), forming a binary tree.
- Each node stores the mean embedding and a heterogeneity score (distance between merged children).
This process is computationally negligible compared to diffusion inference.
Adaptive Embedding Selection During Diffusion
During inference, the denoising process traverses the tree from root to leaves, selecting the appropriate embedding for each step based on a mapping function ϕ(k), which linearly decreases the allowed heterogeneity as the diffusion progresses. The parameter τ controls the trade-off between compute savings and image quality: higher τ allows more sharing (greater savings, possible quality loss), while lower τ specializes earlier (less sharing, higher quality).
Pseudocode for the hierarchical diffusion algorithm is provided in the supplementary material, demonstrating how to avoid redundant evaluations of the denoiser by caching results at each node.
Model Suitability and the Role of Text-to-Image Priors
The method is most effective for diffusion models where the emergence of fine details is gradual, such as those trained with UnCLIP-style text-to-image priors (e.g., Kandinsky, Karlo). In these models, early denoising steps predominantly set coarse structure, allowing shared computation without sacrificing diversity or quality. In contrast, models like Stable Diffusion and Stable UnCLIP, which generate fine details earlier, offer limited opportunities for sharing.

Figure 2: Models trained with a text-to-image prior (Kandinsky, Karlo) exhibit higher quality and diversity under hierarchical compute sharing than those without such priors (Stable Diffusion, Stable UnCLIP).
Quantitative and Qualitative Results
Empirical evaluation across diverse datasets (GenAI Bench, Prompt Template, Animals, Style Variations) demonstrates substantial compute savings—ranging from 50% to 74%—while maintaining or improving image quality as measured by VQA Score. Notably, for fixed compute budgets, the hierarchical approach outperforms standard diffusion, achieving higher VQA scores with fewer steps. For fixed quality targets, the method consistently saves compute across datasets.
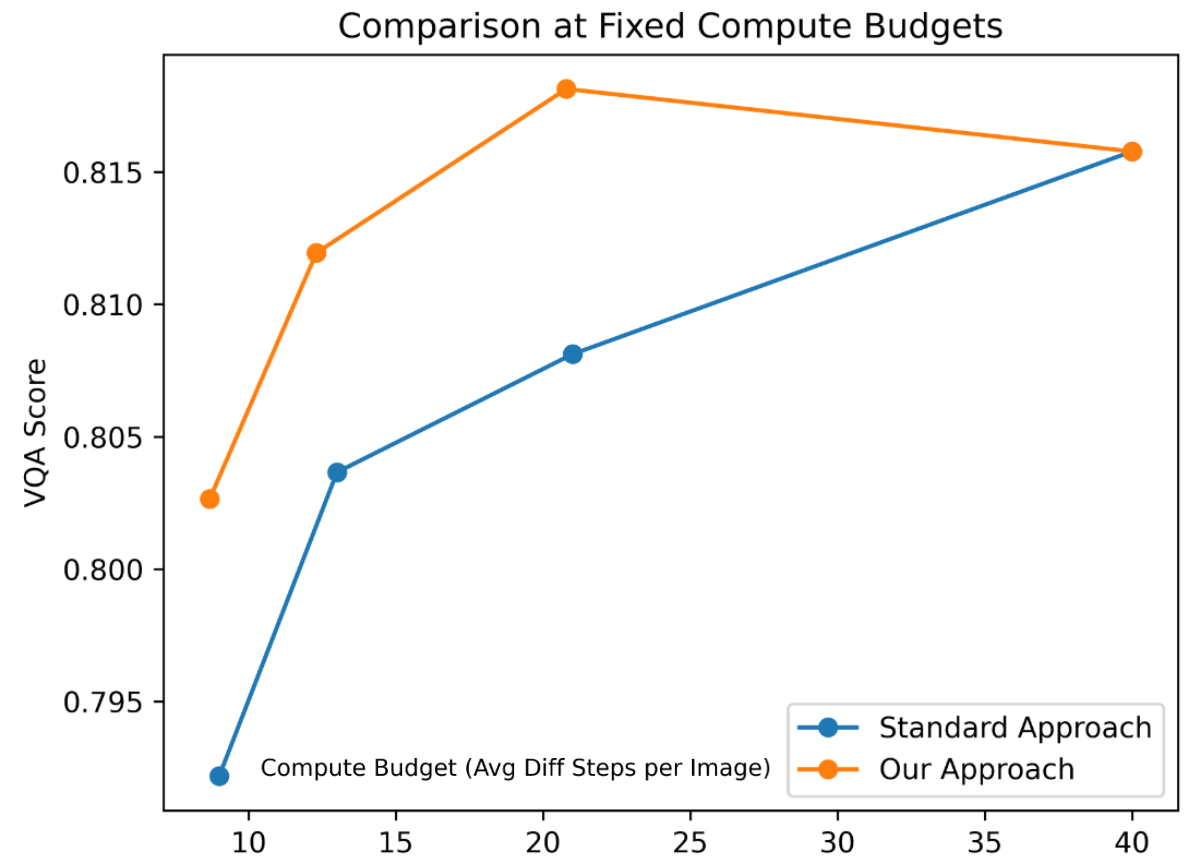
Figure 3: Generation quality (VQA Score) at fixed compute budgets, showing that hierarchical sharing achieves higher scores than standard diffusion for the same or lower compute.
Qualitative comparisons further illustrate that, under constrained compute, the method produces sharper, more detailed images than standard diffusion, which tends to over-smooth outputs when steps are reduced.
Applications
The approach is applicable to a range of practical scenarios:
Ablations and Limitations
Ablation studies confirm the necessity of semantic clustering: random clustering yields negligible savings. The method's effectiveness is contingent on the underlying model's denoising dynamics; models with early detail emergence (e.g., SD 1.5, FLUX) offer only moderate savings. The approach is best suited for large or homogeneous prompt sets; efficiency diminishes for small, highly diverse sets.

Figure 5: Visualization of the de-noised mean embedding and its children, illustrating the semantic mixture captured by higher-level nodes.
Theoretical and Practical Implications
The hierarchical reuse of computation introduces a new axis of efficiency for generative models, orthogonal to per-inference acceleration. It exploits the statistical correlation of low-frequency image content across prompts, aligning with the coarse-to-fine generative process. The method is fully compatible with existing pipelines, requires no retraining, and scales favorably with prompt set size (O(logN) complexity for balanced trees).
Practically, this enables more sustainable deployment of diffusion models, reducing energy consumption and environmental impact for batch generation tasks. Theoretically, it suggests that embedding space structure and denoising schedule design can be further optimized for multi-prompt efficiency.
Future Directions
Potential extensions include adapting the approach to autoregressive models with coarse-to-fine generation (e.g., VAR), exploring non-linear mappings for embedding specialization, and integrating prompt expansion tools for dynamic multi-prompt workflows. Further research may investigate embedding tree construction strategies that account for downstream visual diversity or user intent.
Conclusion
This work presents a method for efficient multi-prompt image generation in text-to-image diffusion models by reusing computation via hierarchical embedding trees. The approach achieves substantial compute savings while preserving or enhancing image quality, particularly for models trained with text-to-image priors. It offers a practical solution for scalable, sustainable generative workflows and opens avenues for further research in multi-prompt optimization and model design.
