- The paper introduces UI-Bench, an expert-driven benchmark for assessing the visual design quality of AI-generated web UIs using blinded pairwise comparisons.
- The evaluation protocol uses 30 standardized prompts across five UI categories and Bayesian TrueSkill modeling to rank ten AI text-to-app tools.
- Key findings reveal significant performance gaps among tools, highlighting the importance of orchestration, template libraries, and asset curation in achieving high design quality.
UI-Bench: A Benchmark for Evaluating Design Capabilities of AI Text-to-App Tools
Motivation and Context
The proliferation of AI text-to-app tools has accelerated the development of low-code and no-code platforms, promising rapid generation of professional-grade web applications and sites. Despite aggressive marketing claims, there has been a lack of rigorous, reproducible benchmarks to evaluate the visual design quality of outputs from these systems. Existing evaluation protocols in the literature have focused on code correctness, functional fidelity, or automated image-based metrics, which are poorly aligned with human aesthetic judgment, especially in the context of multi-section web UIs. UI-Bench addresses this gap by introducing a large-scale, blinded, expert-driven benchmark for the comparative assessment of visual design quality in AI-generated web UIs.
Benchmark Design and Methodology
UI-Bench is constructed around a forced-choice, blinded pairwise comparison protocol, leveraging expert evaluators with professional UI/UX backgrounds. The benchmark comprises 30 standardized prompts spanning five categories (Marketing/Landing, Editorial/Blog, Portfolio/Case Study, E-commerce, Local/Service), each designed to reflect realistic client briefs and diverse design requirements. Prompts were synthetically generated using GPT-5 (Thinking) and subjected to editorial review for coverage and clarity.
Ten leading commercial AI text-to-app tools were evaluated, each generating UIs for all prompts under controlled conditions: default settings, no manual prompt engineering, and a 60-minute time limit per prompt. Outputs were standardized and presented in a blinded interface to raters, with randomized left-right placement and a full-view requirement to ensure holistic assessment.
The evaluation question was explicitly anchored to professional standards: "Which project would you be more likely to deliver to a client?" This framing avoids the pitfalls of subjective taste and grounds judgments in industry-relevant criteria.
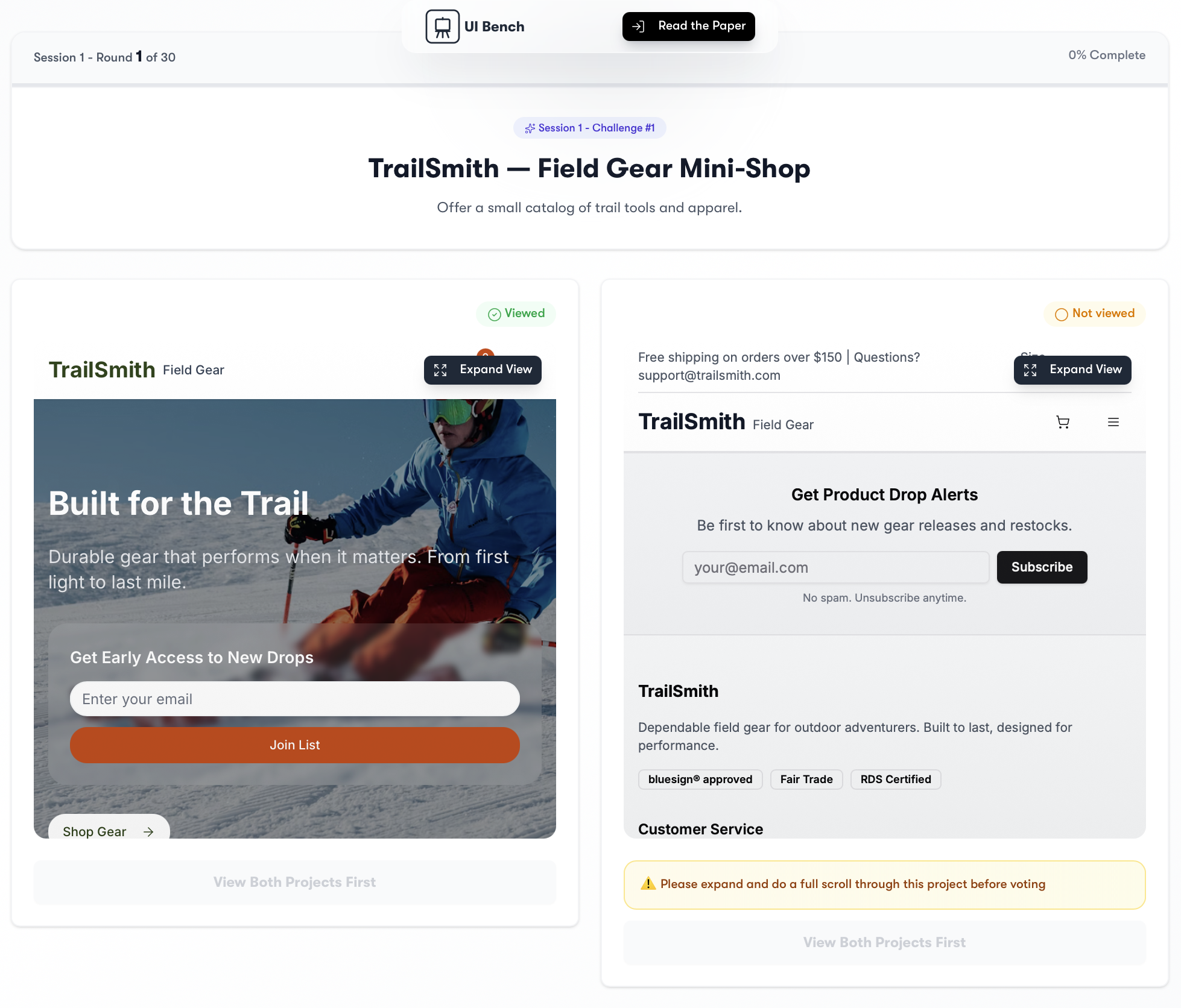
Figure 1: Example comparison interface used in UI-Bench. Raters view two webpages in a blinded layout with randomized placement and a full-view requirement.
Pairwise votes were aggregated using a Bayesian TrueSkill model, yielding prompt-specific and global tool ratings with calibrated uncertainty estimates. The protocol incorporates adaptive sampling to maximize information gain and exposure balance across tools and prompts.
Results and Analysis
Across 4,075 blinded pairwise matches (8,150 unique tool comparisons), UI-Bench establishes a clear stratification among evaluated systems. Orchids leads with a mean TrueSkill rating of 30.12 and a 67.5% empirical win rate, followed by Figma Make (27.46, 57.1%) and Lovable (27.14, 54.8%). The mid-tier cluster (Anything, Bolt, Magic Patterns) exhibits overlapping credible intervals, indicating no statistically significant separation. Lower-ranked tools (Base44 by Wix, Same.new, v0, Replit) consistently underperform, with ratings below 24 and win rates under 48%.
A notable finding is the substantial quality gap between top and bottom performers, despite the likelihood that many tools share similar foundation models. Qualitative analysis attributes this divergence to differences in prompt handling, template libraries, agent orchestration, post-processing, and asset pipelines. Lower-ranked tools frequently defaulted to generic templates, repetitive layouts, and minimal interactivity, while top systems demonstrated deliberate layout planning, coherent visual systems, and higher-quality asset integration.
Limitations
UI-Bench is a static snapshot of tool capabilities as of August 2025, limited to desktop layouts and English-language prompts. The Figma Make tool was evaluated on condensed prompts due to input length constraints, which may affect comparability. The benchmark isolates visual craft (layout, typography, color, hierarchy) and intentionally excludes UX metrics such as load time, accessibility, or code quality. No human-designed baseline is included, so results should be interpreted as relative rankings among AI tools, not as claims of parity with professional designers. The expert pool is predominantly English-speaking, which may bias aesthetic judgments.
Implications and Future Directions
UI-Bench provides a reproducible, expert-driven standard for evaluating the visual design quality of AI text-to-app tools, filling a critical gap in the evaluation landscape. The protocol's reliance on blinded, forced-choice expert judgment, standardized prompts, and Bayesian skill modeling sets a new bar for rigor in this domain. The public release of prompts, evaluation framework, and leaderboard enables ongoing benchmarking and transparency.
Practically, the results highlight the importance of orchestration, template diversity, and asset curation in achieving high-quality AI-generated UIs, beyond mere model selection. Theoretically, the work underscores the limitations of automated aesthetic metrics and the necessity of human-in-the-loop evaluation for design-centric tasks.
Future work should extend the benchmark to include human-designed baselines, mobile and multilingual layouts, and a broader set of UX and accessibility metrics. The development of a failure-mode dataset with expert gold labels will further enable diagnostic analysis and targeted improvement of AI design systems.
Conclusion
UI-Bench introduces a rigorous, blinded, expert-driven benchmark for the comparative evaluation of AI text-to-app tools on visual design quality. The results reveal significant stratification among leading systems and identify orchestration and asset pipeline choices as key differentiators. By releasing standardized prompts, an open-source evaluation framework, and a public leaderboard, UI-Bench establishes a foundation for reproducible, transparent progress in AI-driven web design.

