- The paper introduces a hardware-aware LLM framework that automatically synthesizes swizzling patterns to optimize GPU kernel performance.
- It integrates detailed architectural context and historical profiling feedback to improve L2 cache hit rates by up to 70% on certain kernels.
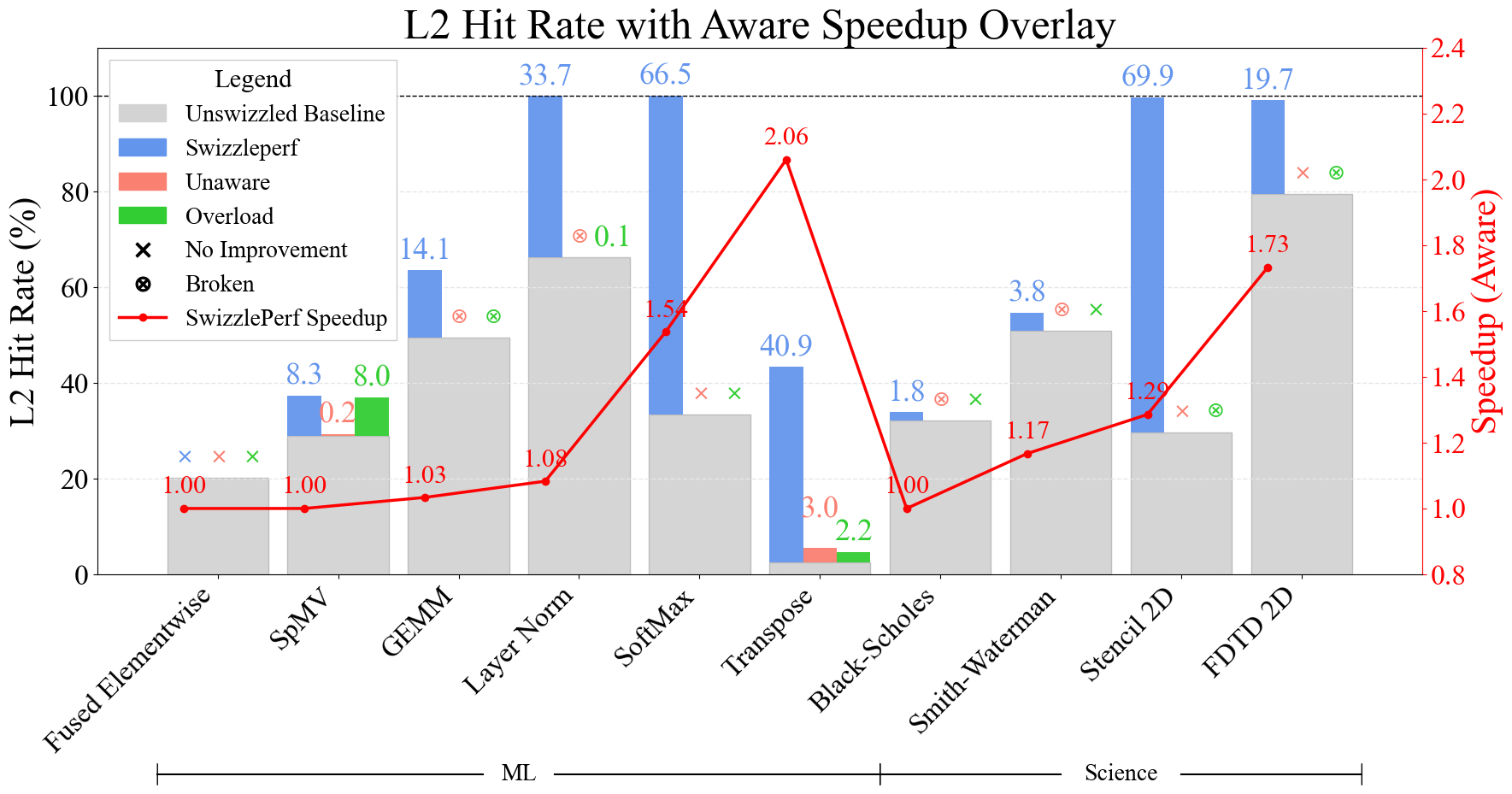
- Experimental results demonstrate speedups ranging from 1.29× to 2.06×, reducing optimization cycles from weeks to minutes.
Introduction and Motivation
SwizzlePerf introduces a hardware-aware, LLM-driven methodology for optimizing GPU kernel performance, specifically targeting spatial remapping (swizzling) to maximize cache locality on disaggregated architectures. The core insight is that existing LLM-based autotuning frameworks lack explicit hardware-awareness, which is essential for achieving near-optimal utilization on modern GPUs with complex memory hierarchies and chiplet-based designs. By integrating detailed architectural context, filtered profiling logs, and historical performance feedback into the LLM prompt, SwizzlePerf enables the automatic synthesis of swizzling patterns that align with the underlying hardware topology and scheduling policies.
Methodology: Hardware-Aware Optimization Loop
SwizzlePerf operates as a closed-loop, bottleneck-driven optimization system. The workflow is as follows:
- CodeGen LLM Call: The LLM receives a prompt containing the original kernel code, a summary of memory access patterns, a history of previous optimization attempts, and explicit hardware details (e.g., number of XCDs, cache sizes, block scheduling policy).
- Parsed Context: Structured context is extracted from profilers (e.g., rocprofv3), device attributes, and architecture documentation, exposing both the bottleneck metric (L2 hit rate) and spatial constraints.
- CodeGen Output: Using DSPy, the LLM outputs a reasoning trace, critiques prior attempts, and proposes a new swizzling formula. The generated code is compiled, validated, and profiled.
- Bottleneck History Buffer: Each iteration appends the code diff and bottleneck report to a persistent buffer, enabling the LLM to reflect on failures and diversify remapping strategies. Candidates are ranked by L2 hit rate, and the best validated kernel is retained.
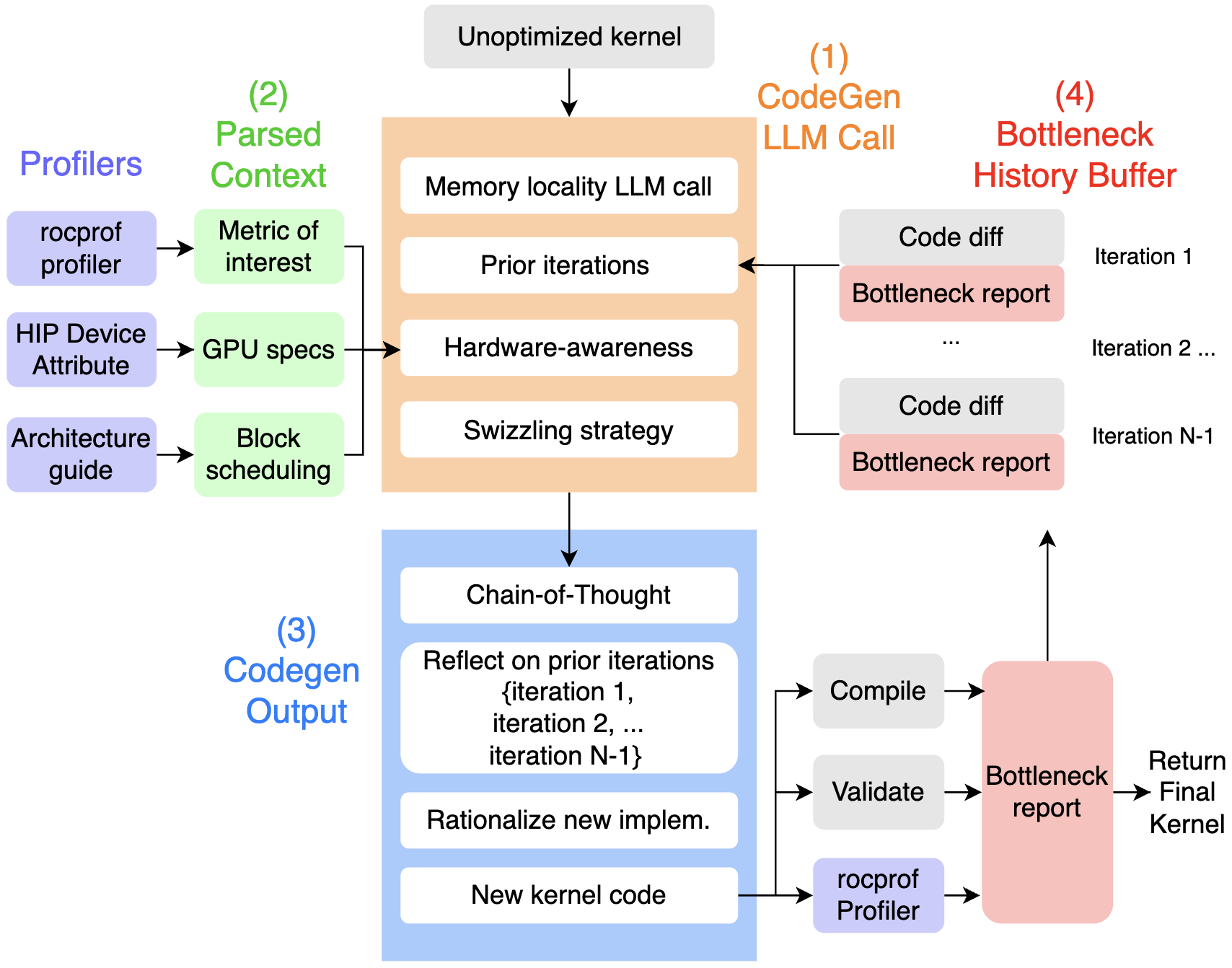
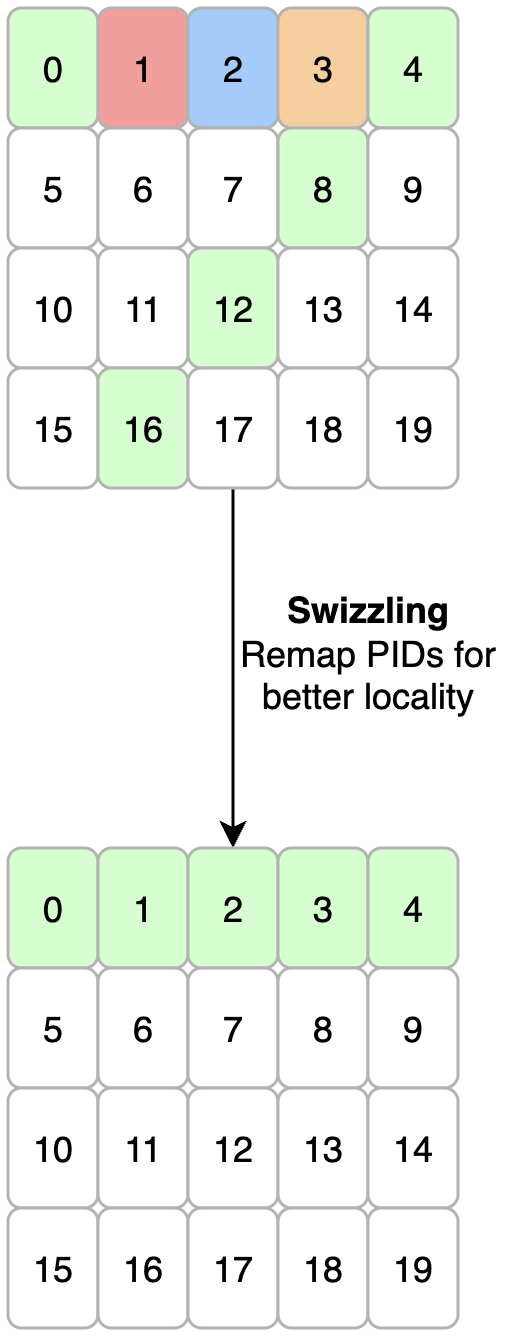
Figure 1: SwizzlePerf methodology and example swizzling outcome. (a) The optimization loop leverages parsed context and historical bottleneck feedback to guide LLM-driven code generation. (b) For GEMM, SwizzlePerf generates a swizzling pattern that co-locates tiles on the same XCD, improving L2 locality.
This approach mimics the workflow of expert performance engineers, but automates the process and accelerates convergence from weeks to minutes.
Swizzling Patterns: Implementation and Examples
Swizzling refers to the remapping of workgroup program IDs (PIDs) to enhance spatial/temporal locality and align computation with hardware topology. SwizzlePerf generates kernel-specific swizzling formulas that maximize intra-XCD L2 reuse. For example, in a tiled GEMM kernel, the swizzling pattern ensures that tiles sharing rows in matrix A are mapped to the same XCD, thus maximizing L2 cache hits.
A representative SwizzlePerf-generated swizzling pattern for GEMM in Triton is:
1
2
3
4
5
|
pid = tl.program_id(0)
num_xcds = 8
num_blocks = NUM_SMS
b_per_xcd = (num_blocks + num_xcds - 1) // num_xcds
pid = (pid % num_xcds) * b_per_xcd + (pid // num_xcds) |
This formula ensures contiguous blocks are assigned to the same XCD, with ceiling division handling edge cases—an improvement over expert-designed patterns.
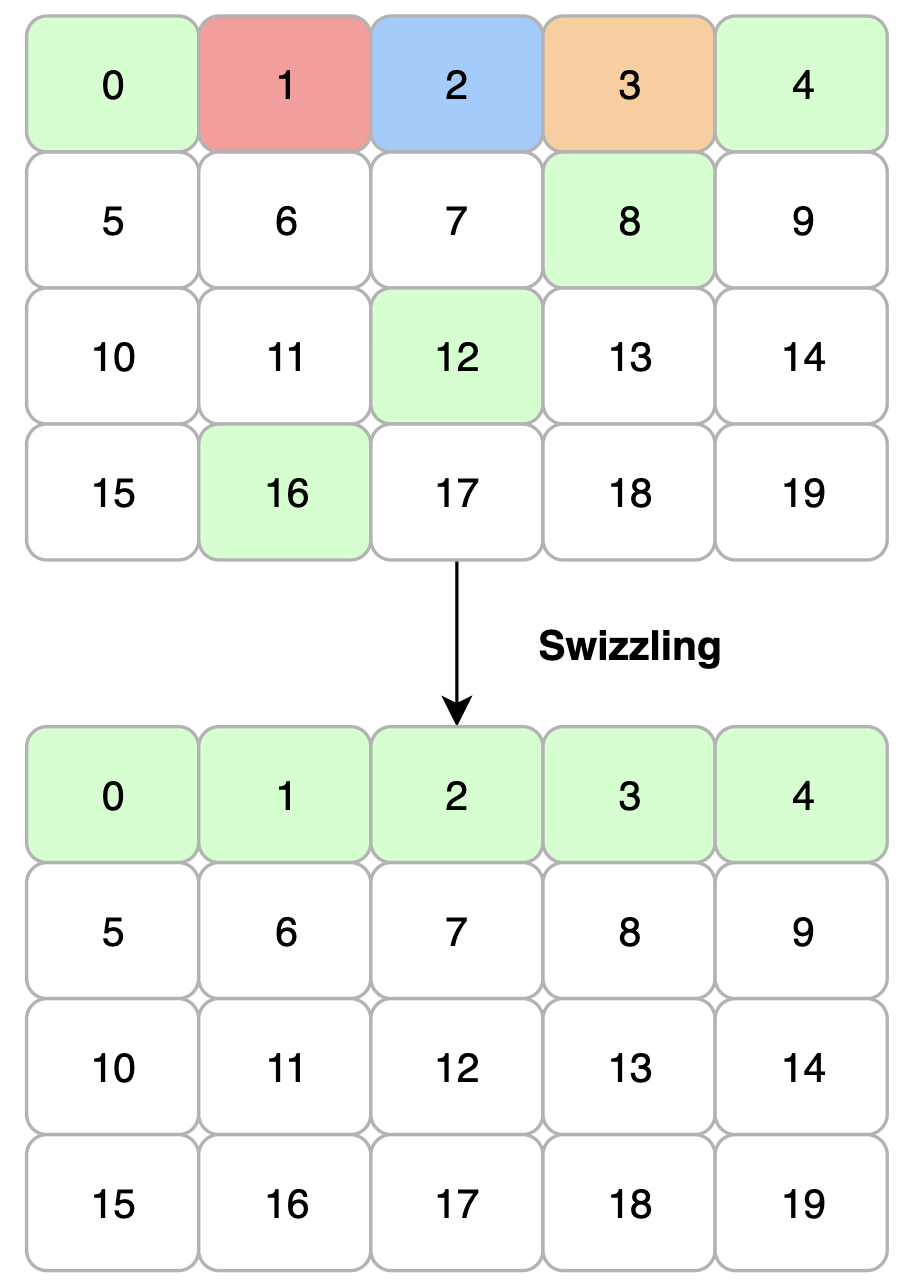
Figure 3: GEMM swizzling pattern generated by SwizzlePerf, demonstrating hardware-specific remapping for improved cache locality.
SwizzlePerf generalizes to a variety of kernels, including LayerNorm, Softmax, FDTD, Stencil 2D, and Transpose, each requiring distinct remapping strategies to align with their memory access patterns and the hardware's cache topology.
Experimental Results
SwizzlePerf is evaluated on 10 diverse GPU kernels (6 ML, 4 scientific), benchmarked on AMD MI300x with medium problem sizes. The primary metric is L2 hit rate, serving as a low-noise proxy for spatial locality, with end-to-end speedup as a secondary metric.
Key results:
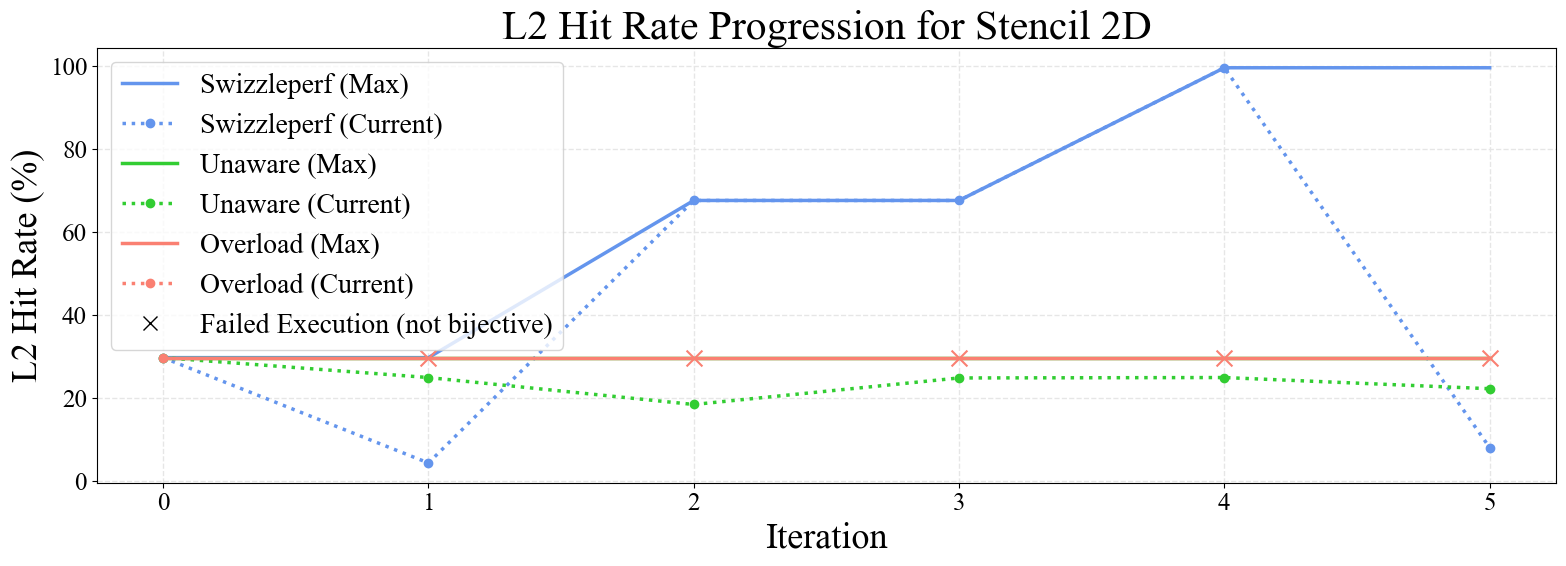
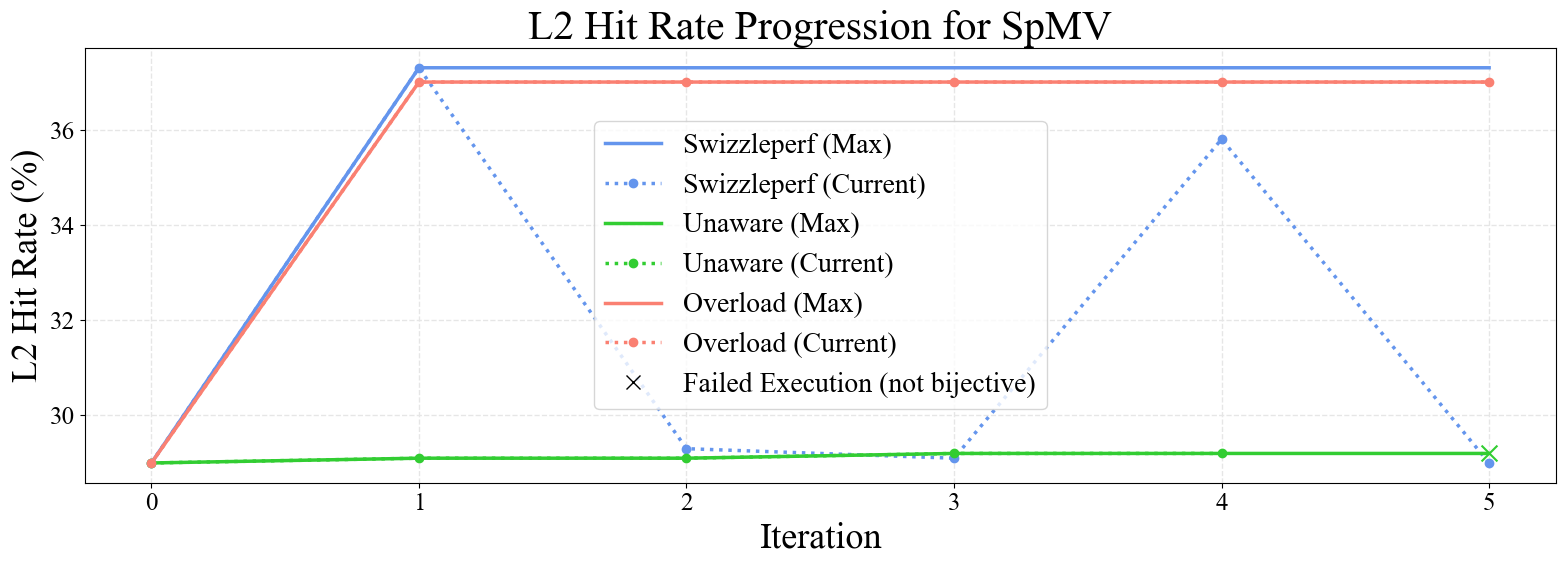
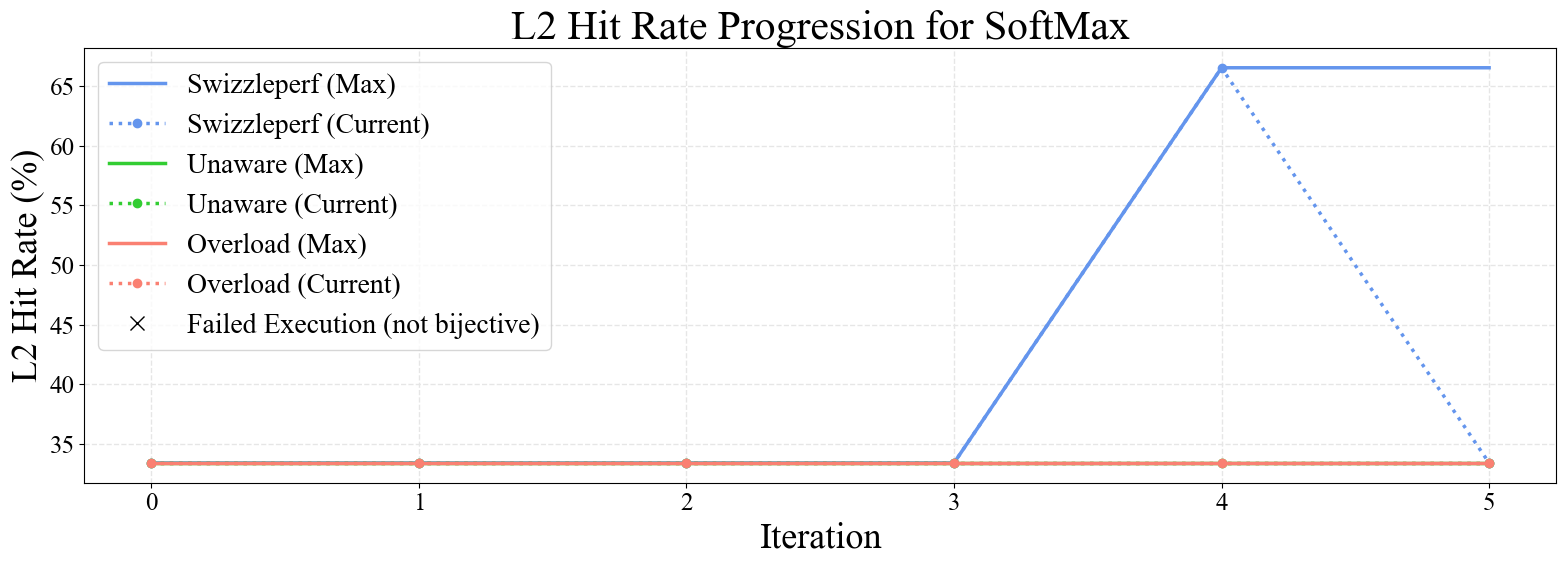
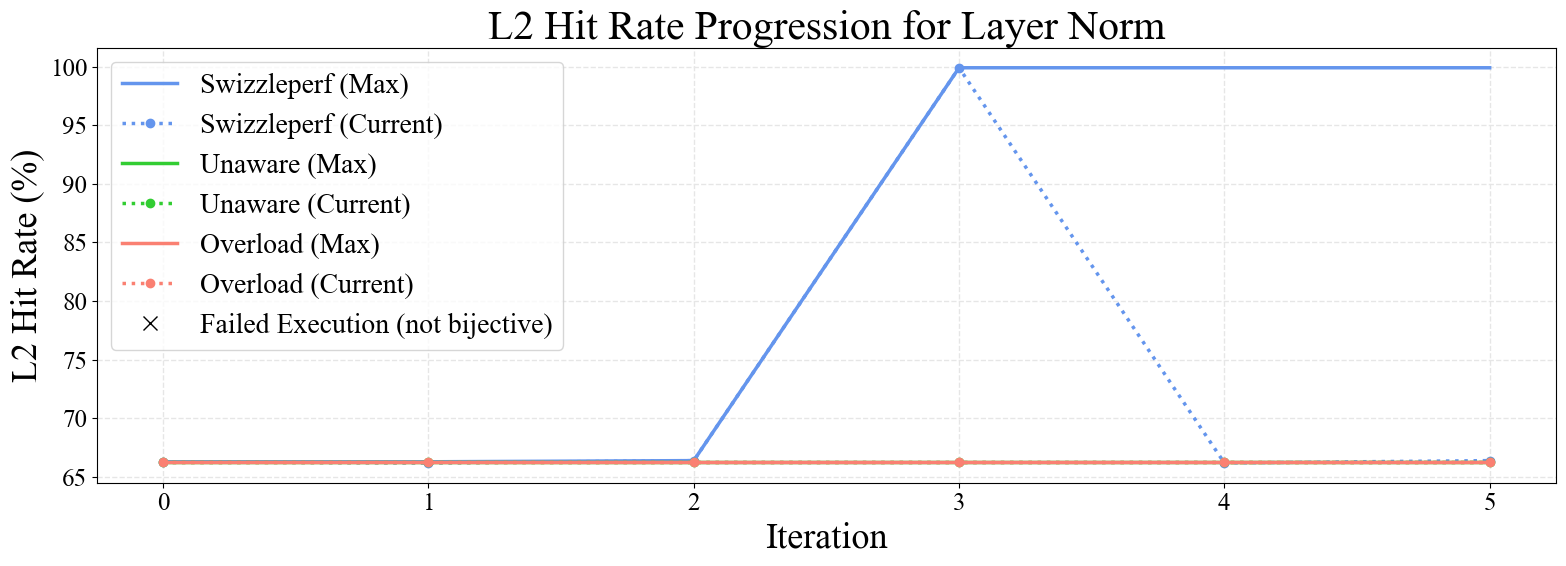
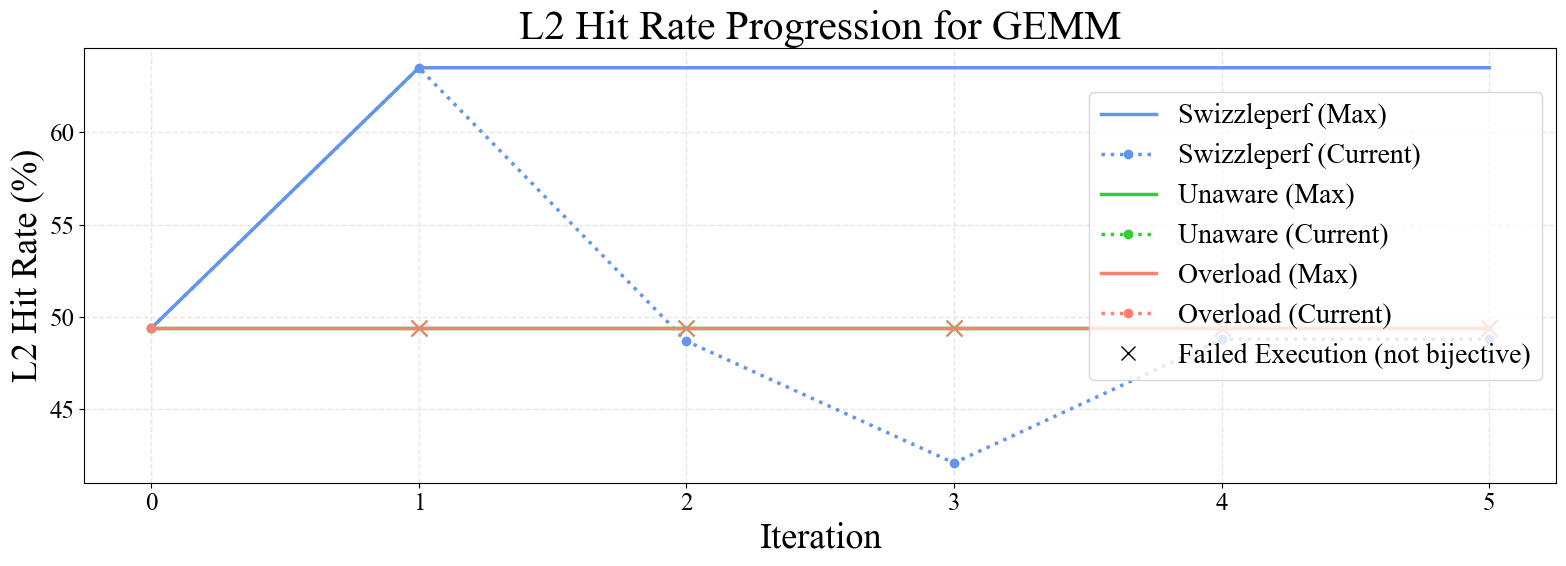
Figure 6: Progression plots for GEMM, Stencil 2D, SpMV, Softmax, and LayerNorm kernels. SwizzlePerf rapidly converges to performant swizzling patterns, while baselines stagnate or degrade.
Notably, SwizzlePerf finds the optimal swizzling pattern for GEMM in under 5 minutes, matching a solution that required two weeks of expert engineering. For memory-bound kernels (e.g., Stencil 2D, Transpose), L2 hit rate improvements translate to substantial speedups, while for compute-bound kernels (e.g., GEMM), the impact is more modest.
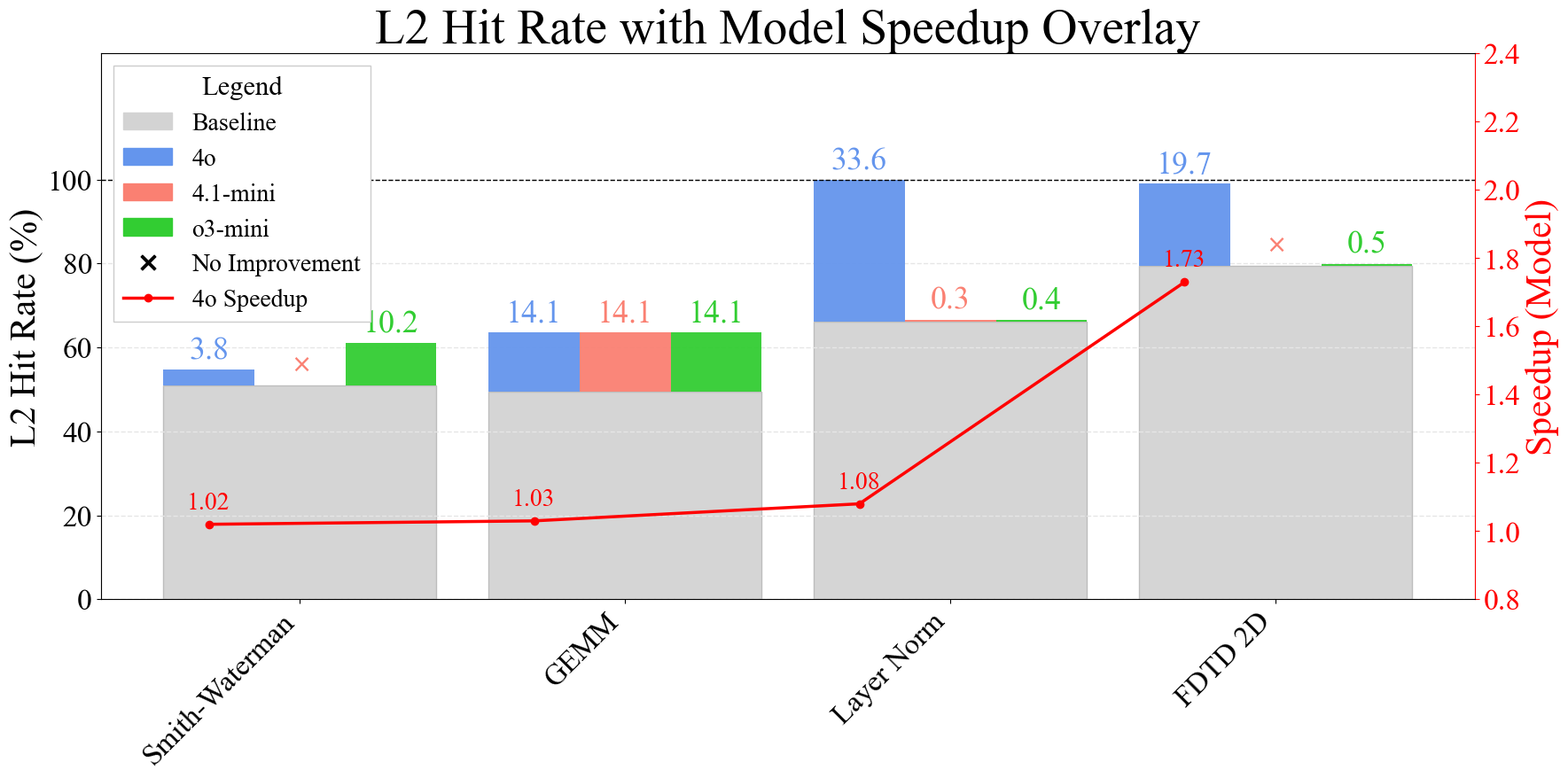
Ablation Studies and Model Analysis
SwizzlePerf's effectiveness is robust to kernel type, problem size, and LLM choice:
Implementation Considerations
SwizzlePerf is built atop the open-source IntelliPerf framework, with key modifications to inject hardware-aware context and structure the LLM prompt/output. The system leverages public profilers (rocprofv3), device attributes (HIP), and architecture documentation to construct the context. The optimization loop is implemented using DSPy, which enforces a structured output signature for reasoning and code generation.
Resource requirements are modest: each optimization loop iteration involves a single LLM call, code compilation, and profiling run. The approach is scalable to large kernels and problem sizes, as the swizzling formulas are synthesized symbolically and validated empirically.
Potential limitations include dependence on the quality of profiler data and the LLM's ability to reason about complex mappings. For highly irregular or data-dependent access patterns, swizzling may yield diminishing returns.
Implications and Future Directions
SwizzlePerf demonstrates that explicit hardware-awareness is essential for unlocking the full potential of LLM-driven performance engineering. The methodology closes the hardware–software feedback loop, enabling LLMs to replicate and, in some cases, surpass expert reasoning in spatial optimization tasks.
Practical implications include:
- Accelerated Kernel Optimization: Drastically reduces the time and expertise required to achieve near-optimal cache locality on modern GPUs.
- Generalizability: The approach is extensible to new architectures, kernels, and bottleneck metrics (e.g., power efficiency).
- Integration with Compiler Toolchains: SwizzlePerf's structured context and output can be integrated into autotuning and code generation pipelines for ML and HPC workloads.
Theoretically, the work raises questions about the modalities of hardware-awareness most conducive to LLM reasoning. Future research directions include:
- Expanding the context to include non-textual modalities (e.g., visualizations of memory access patterns).
- Exploring swizzling for power efficiency and DVFS-aware optimization.
- Systematic benchmarking of LLMs across vendors and architectures for hardware-aware code synthesis.
Conclusion
SwizzlePerf establishes a principled, hardware-aware LLM workflow for GPU kernel performance optimization, with empirical evidence of substantial gains in cache locality and runtime efficiency across a range of real-world kernels. By structuring the optimization loop around explicit hardware context and bottleneck metrics, SwizzlePerf bridges the gap between human expert reasoning and autonomous code generation, setting a new standard for LLM-driven performance engineering on modern accelerators.