- The paper introduces a dual-brain planner–executor architecture that decouples high-level planning from precise execution through specialized and generalist training stages.
- It employs Group Relative Policy Optimization for decoupled RL, using fixed execution and aggregated specialist trajectories to enhance cross-domain generalization.
- Empirical results on scientific software benchmarks demonstrate significant improvements in planning accuracy, execution precision, and overall robustness.
CODA: A Dual-Brain Planner–Executor Framework for GUI Agents with Decoupled Reinforcement Learning
Motivation and Problem Setting
The automation of complex GUI-based workflows, particularly in scientific computing and engineering domains, presents a dual challenge: agents must perform long-horizon, high-level planning while also executing precise, low-level actions in visually and functionally intricate environments. Existing monolithic or compositional agent architectures exhibit a trade-off: generalist models (e.g., Qwen2.5-VL) are effective at planning but lack execution precision, while specialist models (e.g., UI-TARS) excel at grounding but are limited in generalization and strategic reasoning. Prior compositional frameworks that decouple planning and execution are typically static and non-trainable, precluding adaptation from experience and limiting their applicability in data-scarce, specialized domains.
Architecture: Planner–Executor Decoupling
CODA introduces a trainable, compositional agent architecture inspired by the functional separation of the human cerebrum (planning) and cerebellum (execution). The framework consists of a high-level Planner (Qwen2.5-VL) and a low-level Executor (UI-TARS-1.5), with a strict decoupling: only the Planner is updated during training, while the Executor remains fixed, providing stable and generalizable action grounding.
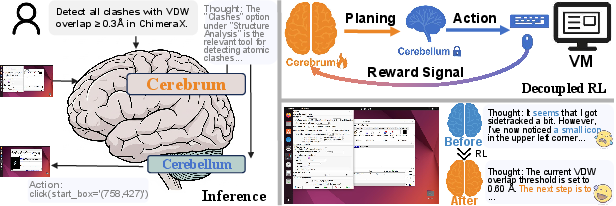
Figure 1: The Planner–Executor architecture, with the Planner generating high-level thoughts and the Executor translating them into concrete GUI actions.
The Planner receives the full interaction history and current/previous screenshots, generating explicit, structured plans that specify immediate objectives and target UI elements. The Executor, conditioned on the Planner’s output and the same context, produces parameterized pyautogui commands (e.g., click(x, y)), ensuring precise execution.
Training Pipeline: Specialization and Generalization
CODA employs a two-stage training pipeline:
- Specialization (Stage 1): For each target software, the Planner is trained via decoupled reinforcement learning using Group Relative Policy Optimization (GRPO). The Executor is held fixed. The Planner generates multiple candidate plans per step; each is executed by the Executor, and a reward is computed based on action type correctness and parameter precision (e.g., L1 distance for coordinates). The GRPO loss is applied only to the Planner’s reasoning tokens, enabling targeted improvement in strategic planning.
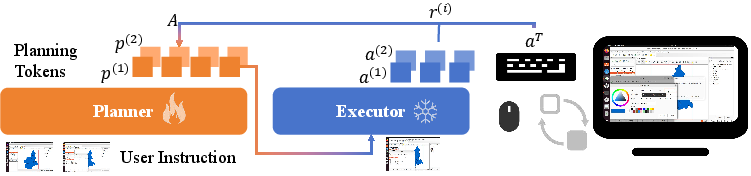
Figure 2: The training process, with the Planner generating plans, the Executor executing actions, and rewards computed for Planner optimization.
- Generalization (Stage 2): Following the specialist-to-generalist paradigm, multiple specialist Planners (one per software) are used to generate high-quality trajectories. These are aggregated to fine-tune a generalist Planner via supervised learning, leveraging the diverse, high-quality data distilled from the specialists.
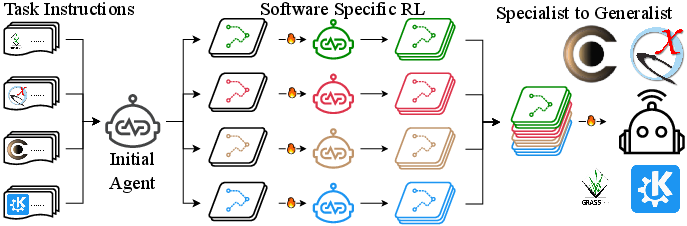
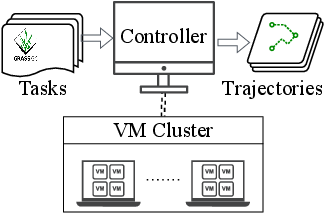
Figure 3: The specialist-to-generalist strategy, aggregating specialist knowledge into a generalist Planner.
This curriculum enables the Planner to acquire both domain-specific expertise and cross-domain generalization, while maintaining execution reliability via the fixed Executor.
Data Generation and Reward Signal
CODA’s training pipeline is supported by an automated data generation and evaluation system:
- Task Generation: High-level tasks are generated using Qwen2.5-72B, seeded with a small set of human-instructed examples and detailed prompts.
- Judge System: A fine-tuned, ensemble-based judge model (Qwen2.5-VL-72B) provides dense, high-precision reward signals by evaluating agent trajectories for correctness, redundancy, and error localization. Voting and multi-resolution input strategies are used to maximize precision and recall.
- Distributed VM System: Task execution is parallelized across a distributed cluster of virtual machines, enabling efficient large-scale trajectory collection.
Empirical Results
CODA is evaluated on four scientific software applications from the ScienceBoard benchmark. The results demonstrate:
The judge system achieves high precision and recall on both in-domain and out-of-domain benchmarks, ensuring reliable reward signals for RL.
Implementation Considerations
- Computational Requirements: Training leverages distributed RL and SFT, with the most intensive component being large-scale trajectory collection and judge model inference. The fixed Executor reduces retraining costs and data requirements.
- Scalability: The distributed VM system supports hundreds of concurrent environments, enabling efficient scaling to new domains and larger datasets.
- Modularity: The decoupled architecture allows for independent upgrades of the Planner and Executor, facilitating continual learning and adaptation.
- Limitations: The approach assumes the availability of a strong, generalizable Executor. In domains where grounding is fundamentally different, Executor retraining or adaptation may be required.
Theoretical and Practical Implications
CODA’s results provide strong evidence for the efficacy of decoupled, trainable Planner–Executor architectures in complex, real-world GUI automation. The specialist-to-generalist curriculum demonstrates that domain-specific RL, followed by cross-domain SFT, yields robust generalization without sacrificing execution precision. The reliance on automated, high-precision reward signals and distributed data generation addresses the data scarcity and evaluation bottlenecks prevalent in specialized domains.
Future Directions
Potential extensions include:
- Richer Multi-Modal Feedback: Incorporating additional sensory modalities (e.g., audio, haptic) for more comprehensive environment understanding.
- Broader Domain Coverage: Scaling to professional and industrial software with highly idiosyncratic interfaces.
- Continual and Lifelong Learning: Enabling the Planner to adapt online to novel tasks and environments, leveraging continual RL and meta-learning.
- Executor Adaptation: Investigating methods for dynamic Executor adaptation in domains with non-standard action spaces or grounding requirements.
Conclusion
CODA establishes a new state-of-the-art among open-source GUI agents for scientific computing, demonstrating that a trainable, decoupled Planner–Executor framework, supported by robust reward modeling and scalable data generation, can effectively address the dual challenges of long-horizon planning and precise execution. The architecture and training methodology provide a principled foundation for future research in adaptive, generalist computer use agents.
