- The paper presents StructureCoder, a method that leverages fill-in-the-middle training and AST-based segmentation to refine code generation.
- The methodology employs fine-grained DPO preference pairs and curriculum learning to focus on critical code segments.
- Experimental results show a consistent 1.5–1.6 point improvement in pass@1 accuracy across diverse benchmarks.
Alignment with Fill-In-the-Middle for Enhancing Code Generation
Introduction
The paper presents StructureCoder, a novel alignment method for code generation in LLMs that leverages Fill-In-the-Middle (FIM) training and Abstract Syntax Tree (AST)-based segmentation to address the limitations of Direct Preference Optimization (DPO) in code tasks. The approach is motivated by the observation that DPO, while effective in other domains, struggles with code generation due to the scarcity of high-quality, test-case-verified training data and the minimal differences between correct and incorrect code completions. StructureCoder decomposes code into granular blocks, constructs fine-grained DPO preference pairs, and employs curriculum learning to maximize the utility of limited data.

Figure 1: A preference pair case in the code generation field. The left is the correct response, and the right is the incorrect response. The only difference between the two responses is in Line 16.
Methodology
FIM-Enhanced DPO
StructureCoder integrates FIM with DPO to mitigate the negative impact of DPO loss on code suffixes. In standard DPO, the loss is computed over the entire sequence, which can penalize correct tokens in the suffix if an error occurs earlier in the code. By using FIM, the model is prompted to generate only the middle segment of code given the prefix and suffix, and the DPO loss is restricted to this segment. This design ensures that the model focuses on the critical region where errors are likely to occur, improving token-level reward assignment and learning efficiency.
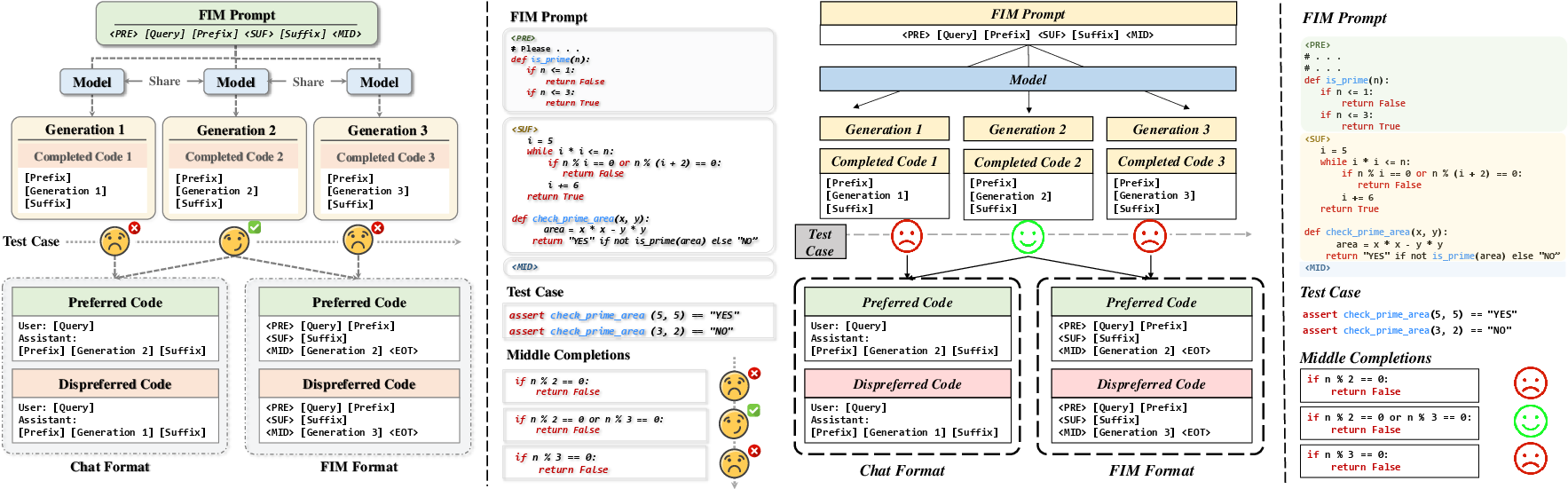
Figure 2: An overview of the FIM-style preference modeling process, illustrating code completion and correctness evaluation via downstream function tests.
AST-Based Segmentation
To construct syntactically and semantically coherent middle segments, StructureCoder parses code into ASTs and selects blocks corresponding to key node types (if, for, while, def). This segmentation ensures that each middle segment is functionally independent and structurally diverse, facilitating effective FIM-based fine-tuning. The approach avoids entangled or partial code fragments, exposing the model to a broad range of code patterns.

Figure 3: Illustration of the AST-based segmentation strategy, ensuring each middle segment is syntactically and semantically coherent.
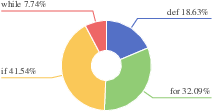
Figure 4: Distribution of extracted code blocks based on AST node types, reflecting the syntactic diversity in the training corpus.
Curriculum Training
StructureCoder employs curriculum learning by ordering training samples according to code snippet length. The model is first fine-tuned on shorter, simpler blocks before progressing to longer, more complex ones. This staged approach enables the model to master token-level rewards in simple contexts before tackling intricate logic and dependencies.
Training Pipeline
The training pipeline consists of parsing code into ASTs, generating FIM prompts for each block, producing multiple completions, evaluating them against test cases, and constructing preference pairs based on correctness and edit distance. Two prompt formats are used: FIM and chat, sampled via a Bernoulli distribution to preserve both code completion and conversational capabilities.
Experimental Results
StructureCoder is evaluated on multiple benchmarks: HumanEval(+), MBPP(+), APPS, LiveCodeBench, and BigCodeBench, using Qwen2.5-Coder-Instruct models of varying sizes. The method consistently outperforms DPO, KTO, and Focused-DPO across all tasks and model scales, with average improvements of 1.5–1.6 points in pass@1 accuracy. The gains are more pronounced in tasks with greater structural diversity and complexity, demonstrating the effectiveness of fine-grained preference modeling and curriculum learning.
Ablation and Analysis
Ablation studies confirm the critical role of each component: FIM, AST segmentation, curriculum learning, and mixed prompt formats. Removing any element degrades performance, especially on challenging datasets like LiveCodeBench. Notably, computing DPO loss on the suffix segment harms optimization, while loss on the prefix is neutral. StructureCoder's restriction of loss to the middle segment is validated as essential for precise error localization and reward assignment.


Figure 5: Credit assignment with different methods. The left is the correct response and the right is the incorrect response (error in Line 2). Each token is colored by DPO implicit reward (darker is higher).


Figure 6: Credit assignment with different methods on Qwen2.5-Coder-3B-Instruct. The left is the correct response and the right is the incorrect response (error from last token of Line 4).


Figure 7: Credit assignment with different methods on Qwen2.5-Coder-7B-Instruct. The left is the correct response and the right is the incorrect response (error in Line 6).
FIM Evaluation
Targeted FIM evaluations on APPS demonstrate that StructureCoder improves middle-span code generation across all model sizes, achieving the highest pass@1 accuracy compared to baselines. This underscores the method's robustness and generalizability in enhancing contextual reasoning for code completion.
Practical and Theoretical Implications
StructureCoder advances alignment for code LLMs by maximizing the utility of limited, test-case-verified data. The approach is data-efficient, scalable, and model-agnostic, provided the underlying LLM supports strong FIM capabilities. Theoretical implications include improved token-level reward assignment and error localization, while practical benefits encompass enhanced code generation quality, generalization, and robustness in real-world programming tasks.
Limitations and Future Directions
The method's effectiveness depends on the model's FIM proficiency, which is not universally available in current LLMs. Additionally, the approach is tailored to code generation and has not been validated in other domains. Future work may explore alternative segmentation strategies, broader application to closed-question tasks, and integration with additional data sources.
Conclusion
StructureCoder introduces a principled, data-efficient alignment strategy for code generation in LLMs, leveraging FIM and AST-based segmentation to construct fine-grained DPO preference pairs and curriculum learning. Extensive experiments demonstrate consistent improvements over existing methods, with strong performance across diverse benchmarks. The approach offers a robust framework for enhancing code LLMs, with potential for further refinement and broader applicability in AI alignment research.

