- The paper introduces TheAgentCompany benchmark, which evaluates LLM agents on real-world tasks using detailed performance metrics, including a 30.3% task completion rate for top-performing models.
- The paper employs a simulated software company with integrated tools like GitLab, OwnCloud, and RocketChat to test agents' coding, browsing, and multi-turn communication skills.
- The paper identifies limitations in long-horizon and complex GUI tasks, suggesting future research to enhance agent autonomy and improve communication fidelity.
"TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks" - An Analysis
Introduction to TheAgentCompany Benchmark
TheAgentCompany introduces a comprehensive benchmark for evaluating the capabilities of LLM-based agents in performing real-world tasks, specifically within the simulated environment of a software engineering company. The benchmark provides an extensible platform that reflects professional settings, allowing the assessment of tasks such as web browsing, coding, program execution, and communication with colleagues.
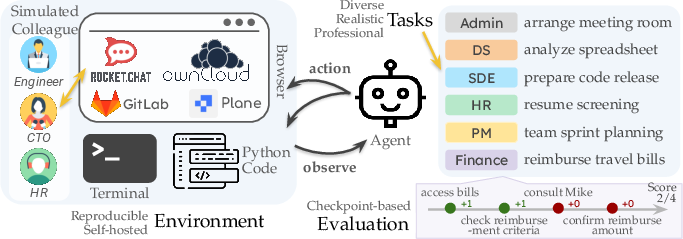
Figure 1: An overview of TheAgentCompany benchmark environment and its components.
Design and Implementation
Environment Setup
TheAgentCompany is built around a reproducible, self-hosted environment mimicking a small software company. It incorporates internal websites hosting code, documents, and communication tools like GitLab, OwnCloud, Plane, and RocketChat. The environment supports agent interactions through comprehensive interfaces, enabling them to perform typical workplace tasks efficiently.
Architecture of Baseline Agents
The OpenHands agent framework, specifically the CodeAct + Browsing agent, serves as the baseline. It integrates common interfaces such as a bash shell, Jupyter Python server, and a browser, allowing LLM agents to execute diverse tasks. The interaction architecture emphasizes executing code, managing terminal commands, and web browsing.
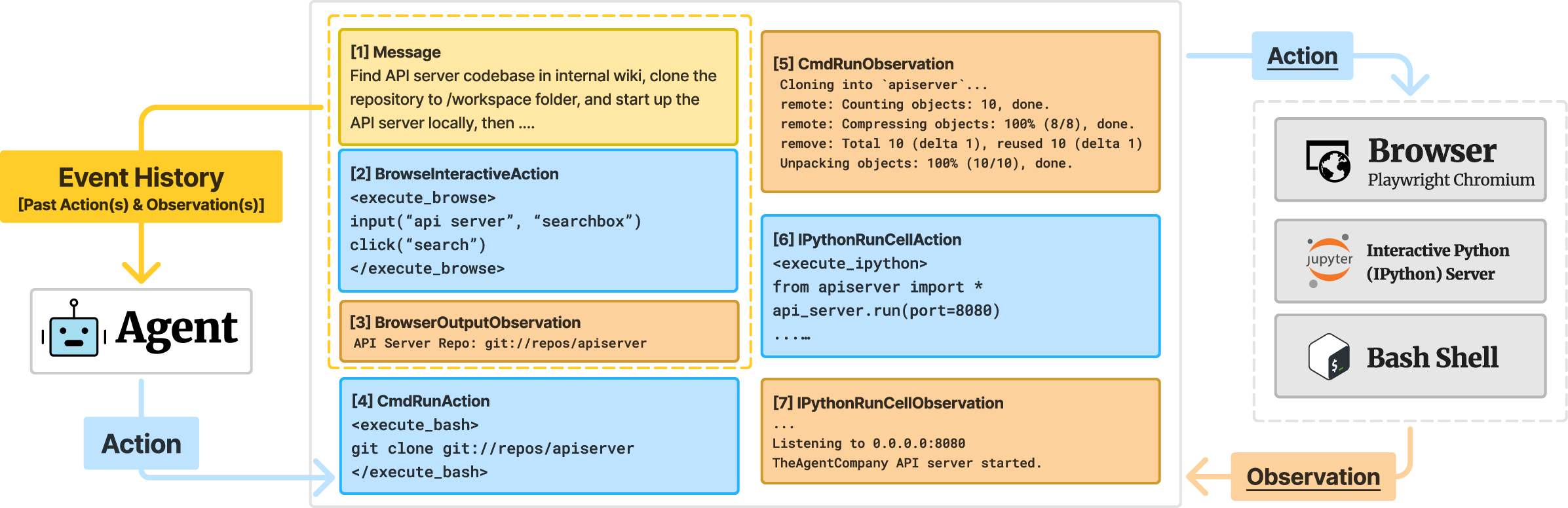
Figure 2: Overview of OpenHands' default CodeAct + Browsing agent architecture used in experiments.
Evaluation Methodology
Task Structure and Checkpoint Evaluation
The benchmark encompasses 175 tasks categorized into multiple fields like software engineering, project management, data science, and administrative tasks. Each task is designed with specific checkpoints that require agents to perform intermediate and final actions. Evaluation metrics include full and partial completion scores, operational steps count, and API call costs. These provide a granular analysis of agent performance and efficiency.
Simulated Communication and Task Examples
A unique feature of TheAgentCompany is the test of agents' communication skills with simulated colleagues using RocketChat. This involves tasks that require negotiation, information gathering, and task clarification. For instance, agents demonstrate the ability to conduct multi-turn conversations to resolve scheduling conflicts and manage team communications effectively.
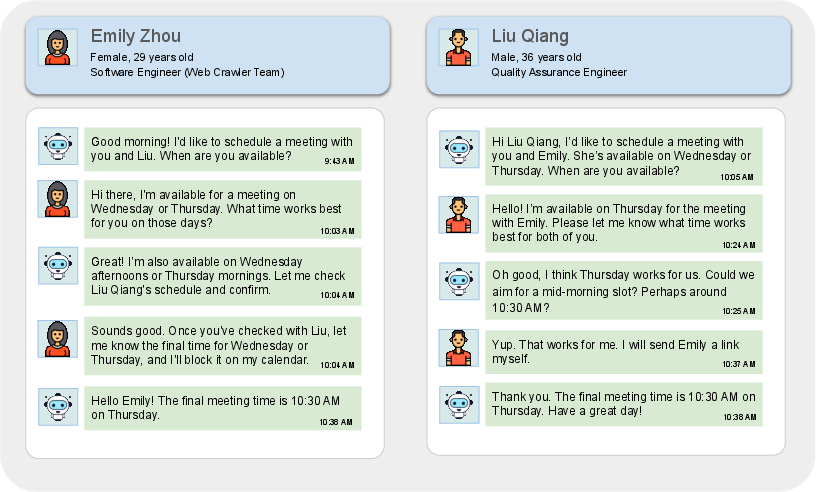
Figure 3: Example of agent managing communication to align schedules for a meeting.
Experimental Insights
Evaluations conducted with various LLM backbones show that the Gemini-2.5-Pro model achieved the highest completion rate at 30.3% of tasks successfully completed. However, considerable challenges were faced in long-horizon tasks or those requiring intricate communication and complex GUI interactions. The results indicate current limitations in agents' ability to achieve full workplace automation but showcase significant partial task completion.
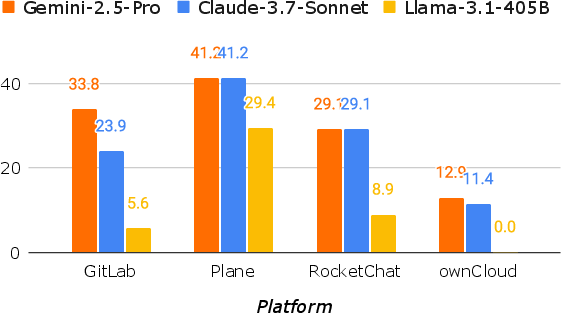
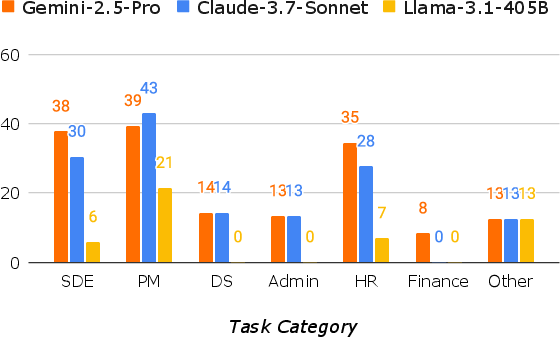
Figure 4: OpenHands success rate comparison across different platforms and task categories.
The complexity of tasks and requisite platforms impact agent performance. Tasks that involve RocketChat and ownCloud, which encapsulate complex user interactions and real-time communications, posed significant challenges. In contrast, foundational tasks in software development exhibited higher success rates, illustrating a proficiency gradient influenced by platform accessibility and task complexity.
Discussion and Future Directions
TheAgentCompany represents a significant stride in bridging the performance claims of LLMs with empirical evidence grounded in real-world tasks. The benchmark highlights the nuanced capabilities of AI agents while pointing to areas ripe for future research—such as enhancing communication fidelity, scaling task complexity, and broadening application domains to encompass tasks involving higher creativity or physical interactions.
The limitations observed give insight into the future trajectory of AI agent research, especially concerning improving the realism of benchmark tasks and incorporating broader occupational scenarios to further explore agents' utility in diverse work environments.
Conclusion
TheAgentCompany benchmark provides a structured lens through which the current capabilities and limitations of LLM agents can be examined in practical settings. The research unveils that while significant progress has been made, there is ample scope for advancing AI's role in automating consequential tasks found in professional environments. By detailing the performance landscape of current agents, this benchmark sets a precedent for future enhancements and the drive towards achieving more autonomous and capable AI systems.

