- The paper introduces Nequix, a resource-efficient materials model that reduces training costs with a compact 700K-parameter, simplified NequIP architecture.
- The paper leverages JAX with dynamic batching and combines the Muon optimizer with RMSNorm to achieve stable and rapid convergence.
- The paper demonstrates that Nequix outperforms larger models in inference speed and benchmark accuracy while requiring only a fraction of the computational resources.
Training a Foundation Model for Materials on a Budget: Nequix
Introduction
The paper presents Nequix, an E(3)-equivariant interatomic potential designed to deliver competitive accuracy for atomistic materials modeling while dramatically reducing computational resource requirements. The work addresses the prohibitive cost of training large-scale foundation models for materials, proposing a compact architecture and efficient training pipeline that enables high-quality results on standard benchmarks with a fraction of the compute typically required.
Model Architecture and Implementation
Nequix is based on a simplified NequIP architecture, incorporating several modifications to enhance efficiency and stability. The species-specific self-connection layer is replaced with a single linear layer, and non-scalar representations are discarded from the final layer. A key innovation is the integration of equivariant root-mean-square layer normalization (RMSNorm), which improves optimization stability and reduces validation error variance, particularly when paired with the Muon optimizer.
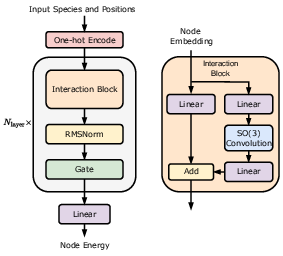
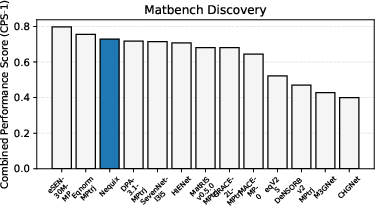
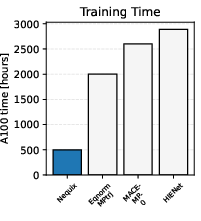
Figure 1: Nequix architecture, a simplified version of NequIP, with species-independent residual connection and layer normalization.
The model is implemented in JAX using Equinox, leveraging just-in-time compilation and efficient autodiff. Forces and stresses are computed via energy gradients with respect to atomic positions and strain, respectively, following standard MLIP practice. Dynamic batching is employed to maximize GPU utilization, with batch caps set relative to dataset-average graph sizes and padded to meet JAX's static shape requirements.
Optimization Strategies
The training pipeline compares Adam and Muon optimizers across learning rates and normalization configurations. Muon, which orthogonalizes weight updates via the Newton-Schulz algorithm, achieves comparable or superior energy/force errors to Adam in most epochs and yields a 7% reduction in energy MAE. RMSNorm further reduces stress error variance and generally improves validation error for Muon-based runs.
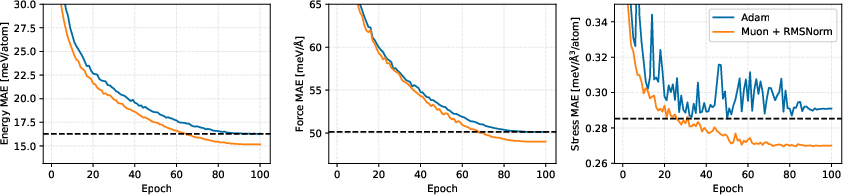
Figure 2: Validation metrics during training of a smaller Nequix configuration with Adam and Muon, across learning rates and normalization settings.
The final Nequix model comprises 700K parameters and is trained for 100 epochs on the MPtrj dataset, utilizing 4 NVIDIA A100 GPUs over 125 hours (500 GPU hours total). The training procedure employs MAE loss for energy and stress, l2 loss for forces, and a linear warmup with cosine decay learning rate schedule.
Benchmark Results
Matbench-Discovery
On the Matbench-Discovery benchmark, Nequix ranks third among compliant models by combined performance score (CPS-1), outperforming most models at a fraction of the training cost. The model demonstrates strong performance in thermal conductivity prediction, with F1 scores comparable to other leading methods. Notably, Nequix achieves this with less than one quarter of the training cost of most competitors and an order-of-magnitude faster inference speed than the top-ranked model.
MDR Phonon Benchmark
Nequix is also evaluated on the MDR phonon benchmark, reporting MAE for maximum phonon frequency, vibrational entropy, Helmholtz free energy, and heat capacity. The model ranks within the top three for all metrics, despite having significantly fewer parameters than other high-performing models.
Inference Speed
Inference speed is a critical practical consideration for high-throughput materials screening. Nequix achieves approximately 10× faster inference than eSEN and is only 2× slower than MACE-MP-0, establishing a new Pareto frontier in accuracy versus speed for materials foundation models.
Training Dynamics
Validation curves for energy, force, and stress MAE throughout training indicate stable convergence and low final errors: 10.05 meV/atom (energy), 32.79 meV/Å (forces), and 0.22 meV/Å3/atom (stress).
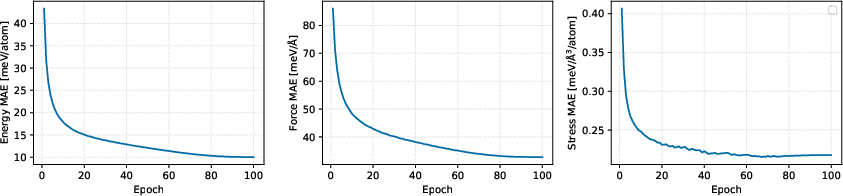
Figure 3: Validation curves for Nequix training on MPtrj.
Implementation Considerations
Nequix's compact architecture and efficient training pipeline make it accessible for research groups with limited computational resources. The use of JAX and dynamic batching ensures high hardware utilization, while the Muon optimizer and RMSNorm contribute to fast convergence and robust generalization. The released codebase and model weights facilitate reproducibility and extension.
Implications and Future Directions
The results demonstrate that strong downstream accuracy in materials modeling can be achieved without resorting to large, resource-intensive models. This has significant implications for democratizing access to high-quality atomistic modeling, enabling broader participation in materials discovery. Future work may explore scaling training duration and data, pretraining and fine-tuning across diverse datasets, and further cost reductions via model distillation, pruning, quantization, and kernel optimizations.
Conclusion
Nequix exemplifies a resource-efficient approach to training foundation models for materials, achieving competitive accuracy and fast inference at a fraction of the typical computational cost. The model provides a practical alternative to large-scale architectures and sets a strong baseline for future research on accessible materials foundation models. The open-source release of weights and codebase further supports adoption and innovation in the field.