- The paper's main contribution is the AGQ framework, which uses an enhanced CEIRT model to dynamically assess users' knowledge and generate targeted questions.
- It leverages adaptive inspiring text to fill conceptual gaps, offering precise guiding questions to improve information retrieval efficiency.
- Experimental results demonstrate that AGQ outperforms baseline methods in dialog accuracy and user knowledge acquisition across various LLM configurations.
Ask Good Questions for LLMs
Introduction
The paper addresses the limitations of current LLM-driven dialog systems when it comes to effective question-generation during information retrieval tasks. These models often struggle to identify users' knowledge deficiencies and generate guidance questions accordingly. The Ask-Good-Question (AGQ) framework is introduced, leveraging an enhanced Concept-Enhanced Item Response Theory (CEIRT) model to more accurately gauge users' knowledge states and dynamically generate targeted questions. This approach aims to improve information retrieval efficiency and the overall user experience by crafting more contextually relevant questions.
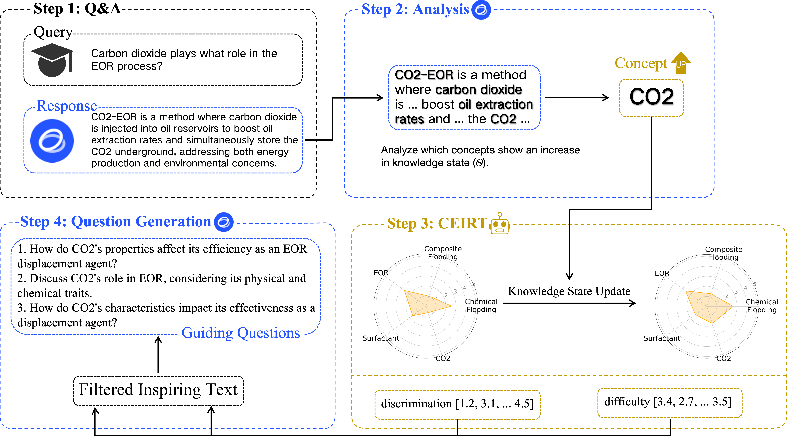
Figure 1: The diagram shows a single cycle of the Ask-Good-Question (AGQ) framework: processing user-LLM interactions, dynamically updating knowledge state vectors (θ), and using discrimination (a) and difficulty (b) parameters to filter inspiring texts for generating guiding questions that enhance information retrieval.
Methodology
Concept-Enhanced Item Response Theory (CEIRT) Model
The AGQ framework employs the CEIRT model which extends the 2-PL model typically used in psychometrics by introducing vector representations for the user's knowledge state (θ), item difficulty (b), and item discrimination (a). This allows for a dynamic and rigorous assessment of users' conceptual understanding. The core equation determining the probability of a correct user response is:
pi=1+exp(−∑j(aiθj−bi))1
This captures how various conceptual abilities contribute to answering questions correctly, modifying the user's understanding during interactions.
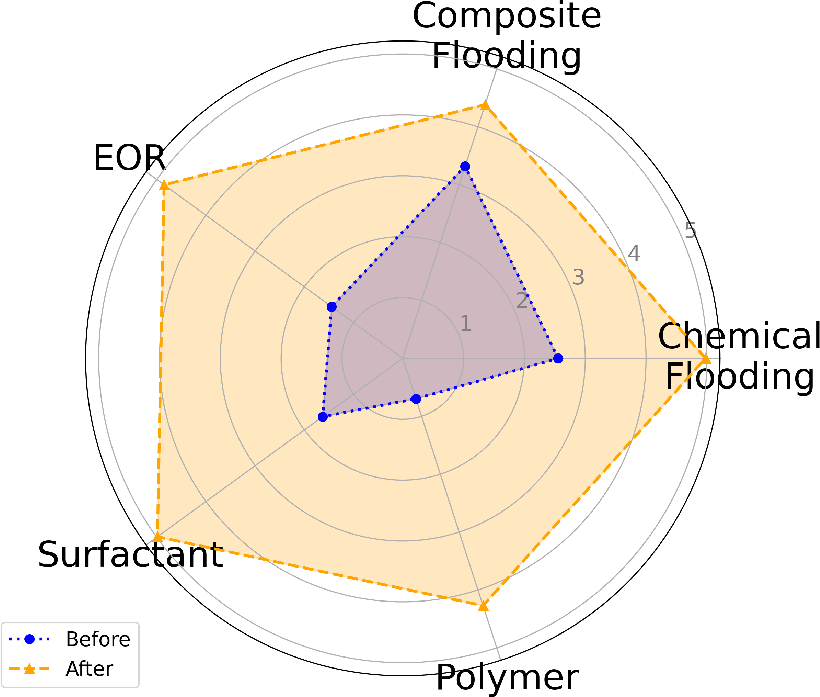
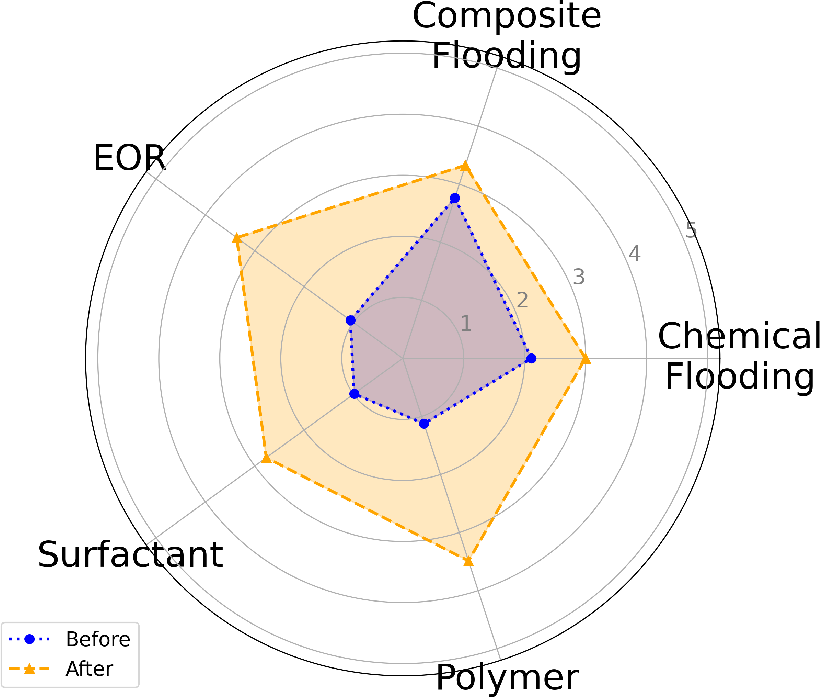
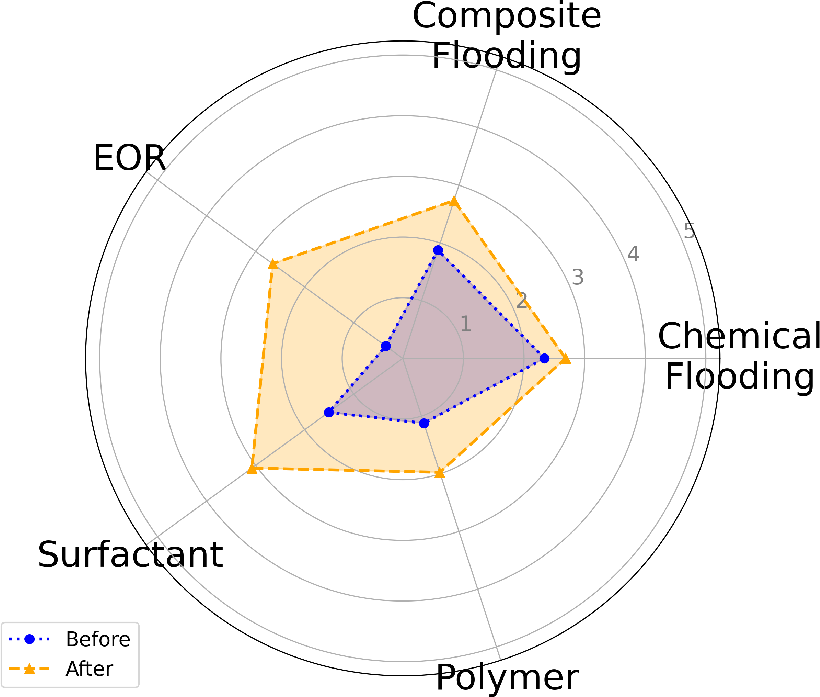
Figure 2: Evolution of user knowledge states (θ) across five key concepts using different guiding question generation methods.
Inspiring Text and Adaptive Question Generation
To tailor questions effectively, the AGQ uses 'Inspiring Text' to contextualize guidance. The framework employs a scoring function S(t,j) which measures the suitability of text t for a user with a knowledge state θj. This is calculated using:
S(t,j)=exp(−(∣θj−bi∣−1)2)
Aiming for a moderate challenge, this feature enables focusing on the conceptual gaps where users will benefit most from guidance.
Algorithm
Algorithmically, AGQ processes user inputs to determine interaction outcomes and updates knowledge states via the CEIRT model. The framework involves filtering text to find the most suitable passages for user queries, leveraging LLMs for generating variants of instructional prompts—conditioned on knowledge state thresholds—resulting in targeted inquiry questions for the user.
Algorithm Steps:
- User submits a query, which the model attempts to resolve, updating the user's knowledge estimation.
- The model identifies text suitable for bridging specific knowledge gaps.
- It generates targeted guiding questions, initially focusing on foundational knowledge (PQGlow) and transitioning to more complex, application-oriented questions (PQGhigh) as users advance.
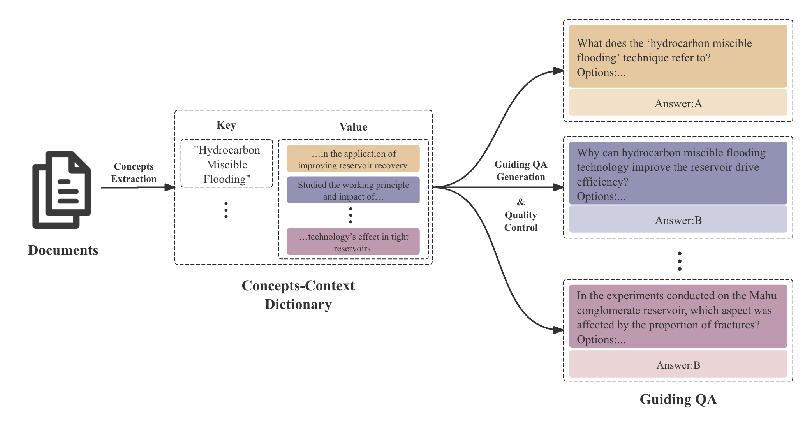
Figure 3: This diagram illustrates the EOR-QA generation process using hydrocarbon miscible flooding as an example, including the extraction of concepts, the construction of a Concepts-Context Dictionary, and the subsequent generation and quality control of guiding questions.
Experimental Results
In evaluations against baselines, AGQ notably outperformed existing methods such as Zero-shot generation and Chain-of-Thought prompts. These metrics measured increases in user retrieval accuracy and progressive knowledge acquisition across interaction rounds.
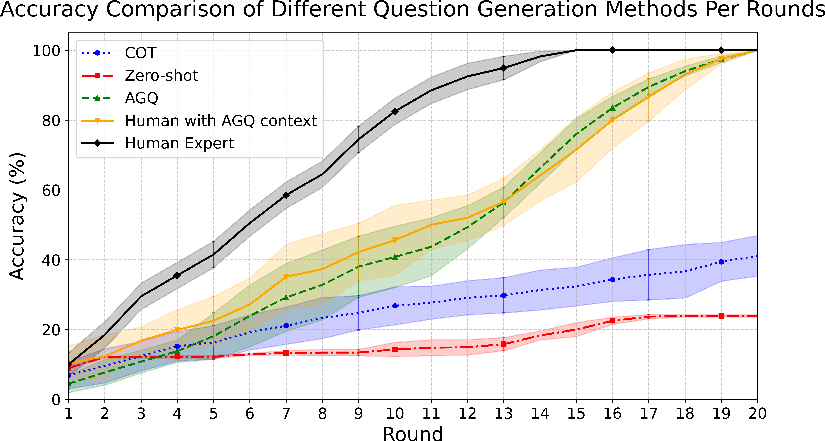
Figure 4: Accuracy comparison of different guiding question generation methods over dialogue rounds. The AGQ method demonstrates performance significantly exceeding CoT and Zero-shot approaches, closely approaching the effectiveness of Human Experts.
Cross-Model Adaptability
AGQ's framework was tested across various LLMs, showing robustness and adaptability in different configurations. The method's efficacy did not significantly diminish between model scales, suggesting strong generalizability.
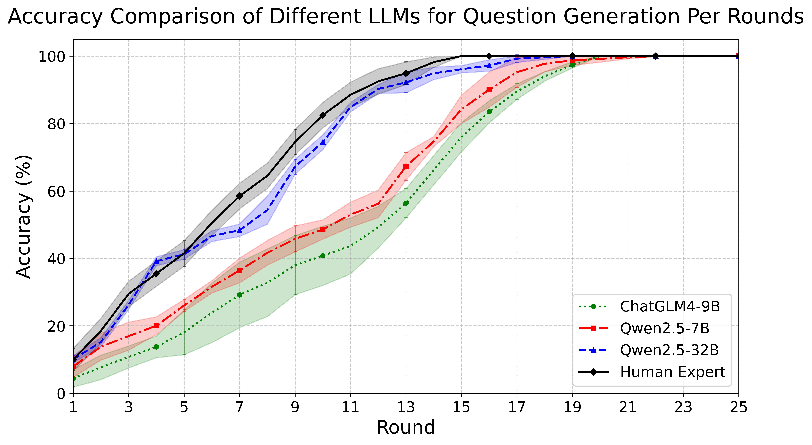
Figure 5: Accuracy comparison of guiding question generation using the AGQ framework with different LLMs (ChatGLM4-9B, Qwen2.5-7B, Qwen2.5-32B) and Human Expert over dialogue rounds.
Conclusion
AGQ introduces an effective approach for QA generation in IR settings by integrating CEIRT into LLM workflows for dynamic, user-specific question crafting. This framework holds promise across domains requiring tailored instructional guidance, such as education and specialized industry training. While initial demonstrations focused on resource-intensive tasks like enhanced oil recovery, future research may extend its applications to other complex, knowledge-driven environments.

