- The paper introduces UNCAGE, which employs contrastive attention guidance to optimize token unmasking order in Masked Generative Transformers.
- It leverages Gaussian-smoothed attention maps and contrastive scoring to enhance text-image alignment and reduce attribute mixing.
- Experimental results reveal that UNCAGE surpasses baseline methods with superior CLIP similarity scores and improved compositional fidelity.
"UNCAGE: Contrastive Attention Guidance for Masked Generative Transformers in Text-to-Image Generation"
Introduction
Text-to-Image (T2I) generation is a significant task in computer vision that involves generating images from textual descriptions. Masked Generative Transformers (MGTs) have emerged as a promising alternative to Autoregressive Models, offering advantages like bidirectional attention and parallel decoding. Despite these benefits, MGTs struggle with compositional T2I generation, particularly in maintaining accurate attribute binding and text-image alignment. To tackle these challenges, the paper introduces Unmasking with Contrastive Attention Guidance (UNCAGE), a training-free method leveraging attention maps to improve compositional fidelity by prioritizing the unmasking of tokens representing individual objects.
Methodology
UNCAGE addresses the issue of misaligned attribute binding in MGTs through a novel approach centered on unmasking order strategies. The method employs contrastive attention guidance to prioritize tokens that clearly represent each object in the textual prompt. This process is divided into several key steps:
- Attention Map Extraction: UNCAGE utilizes attention maps from the MGT to determine which tokens should be unmasked. These maps are smoothed with a Gaussian filter to enhance stability.
- Contrastive Attention Score: The method computes a contrastive attention score for each token, determining its importance based on positive and negative pair constraints:
- Positive Pair Constraint: Encourages unmasking tokens where object and attribute tokens from the same object in the prompt have high attention.
- Negative Pair Constraint: Discourages unmasking tokens with high attention from unrelated objects to avoid attribute leakage.
- Implementation Strategy: UNCAGE modifies the unmasking logic of the MGT by adding the contrastive attention score to existing confidence and randomness terms, guiding the selection of unmasked tokens during the generation process.
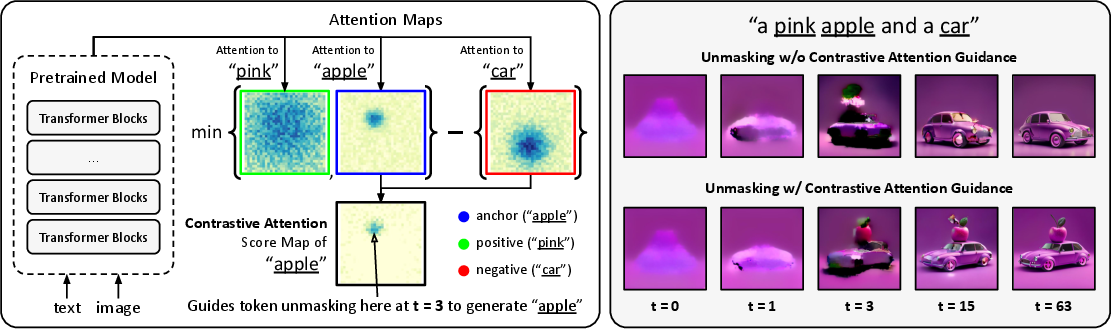
Figure 1: Overview of UNCAGE, illustrating the effectiveness of contrastive attention guidance in generating both a car and an apple from a given prompt.
Experimental Evaluation
The efficacy of UNCAGE is demonstrated through qualitative and quantitative experiments across multiple benchmarks, including the Attend-and-Excite and SSD datasets. Metrics such as CLIP text-image similarity and GPT-based evaluations consistently show that UNCAGE outperforms existing methods in terms of accuracy and text-image alignment with negligible inference overhead.
- Quantitative Results: UNCAGE consistently outperforms baseline methods like Meissonic and the Halton Scheduler in benchmarks evaluating compositional fidelity.
- Qualitative Results: The method effectively generates images where multiple objects and their attributes are correctly aligned with the prompts, avoiding common pitfalls like attribute mixing.








Figure 2: Qualitative results on the Attend-and-Excite dataset showing the improved attribute alignment with UNCAGE.
Limitations and Future Directions
While UNCAGE provides significant improvements in compositional T2I tasks, its performance is limited by the constraints of the pretrained model. Situations involving entrenched biases or unusual compositional scenarios may still present challenges. Future work could explore hybrid methodologies that integrate gradient-based refinement or training extensions to further enhance compositional accuracy.
Conclusion
UNCAGE presents a novel advancement in text-to-image generation with Masked Generative Transformers, specifically addressing the complex issue of compositional fidelity without additional computational overhead. By refining the unmasking process through contrastive attention guidance, UNCAGE offers a promising path forward for enhanced image generation capabilities in AI, with implications for deployment in creative industries and automation requiring nuanced visual synthesis.