- The paper presents a novel zero-shot voice conversion system, REF-VC, leveraging diffusion transformers to fuse ASR and SSL features.
- The model employs a random erasing strategy and implicit alignment to enhance noise robustness and preserve natural expressiveness.
- Shortcut Models streamline inference, achieving superior NMOS and SMOS metrics compared to state-of-the-art baselines in both clean and noisy environments.
Introduction
Voice Conversion (VC) involves transforming the voice of a source speaker into that of a target speaker while preserving the linguistic content. In practical applications, two main challenges arise: robustness to environmental noise and the demand for expressive and natural output. Previous methods, such as those based on Automatic Speech Recognition (ASR), suppress noise but at the cost of expressiveness. Self-supervised learning (SSL) approaches capture expressiveness but suffer from timbre leakage and noise sensitivity.
REF-VC is proposed to address these challenges by combining the strengths of ASR and SSL frameworks. This novel VC system leverages diffusion transformers (DiT) as its backbone to enhance robustness and expressive performance.
Model Architecture and Techniques
As depicted in the architecture overview (Figure 1), REF-VC includes key components such as an input encoder, a fusion module, and a DiT-based estimator. Pretrained Wenet and WavLM are utilized to extract bottleneck features (BNF) and SSL representations, respectively. The model operates on these features to project them into a lower-dimensional latent space for content conditioning.
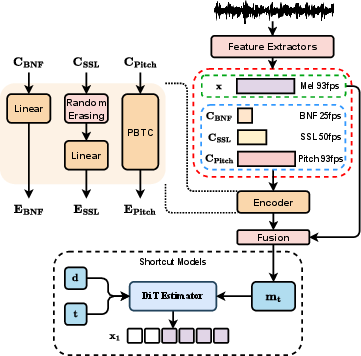
Figure 1: Architecture overview of REF-VC.
Random Erasing Strategy
The paper introduces a random erasing strategy to handle redundancy in SSL features. The method involves randomly erasing parts of SSL features during training, which forces the model to rely on BNF for noise-robust content modeling, while still leveraging SSL features for paralinguistic information.
Implicit Alignment
Traditional frame-to-frame conversions may compromise audio clarity. REF-VC employs an implicit alignment inspired by TTS systems, using blank frame padding to align inputs, enhancing robustness and fidelity. The fusion module combines features into the estimator's input efficiently (Figure 2).
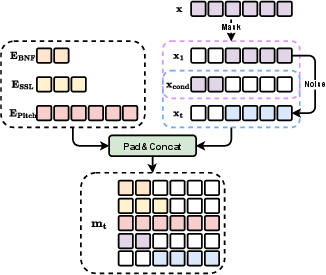
Figure 2: Detail of fusion module.
Shortcut Models
To optimize inference speed, Shortcut Models are implemented, enabling effective inference in just four steps. This approach introduces the step size d to modify sampling paths, significantly reducing error in generating output signals (Figure 3).
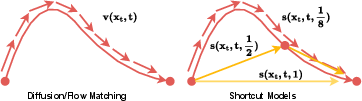
Figure 3: Comparison of shortcut models and flow matching.
Experiments and Evaluation
Objective and Subjective Evaluation
REF-VC is evaluated against baselines like Seed-VC and VITS-VC. On clean audio, REF-VC shows comparable speaker similarity while excelling in challenging noisy conditions due to its robust architecture. It demonstrates superior Naturalness Mean Opinion Score (NMOS) and Speaker Similarity (SMOS) metrics in both environments.
Performance metrics such as Character Error Rate (CER) and Speaker Embedding Cosine Similarity (SECS) reaffirm REF-VC's efficacy in maintaining intelligibility and speaker consistency under varying conditions (Table 1).
Ablation Studies
Ablation studies validate the contributions of key components. The absence of random erasing led to a severe degradation in both naturalness and speaker similarity due to the unchecked reliance on SSL features. The implicit alignment was critical in preserving audio fidelity (Figure 4).
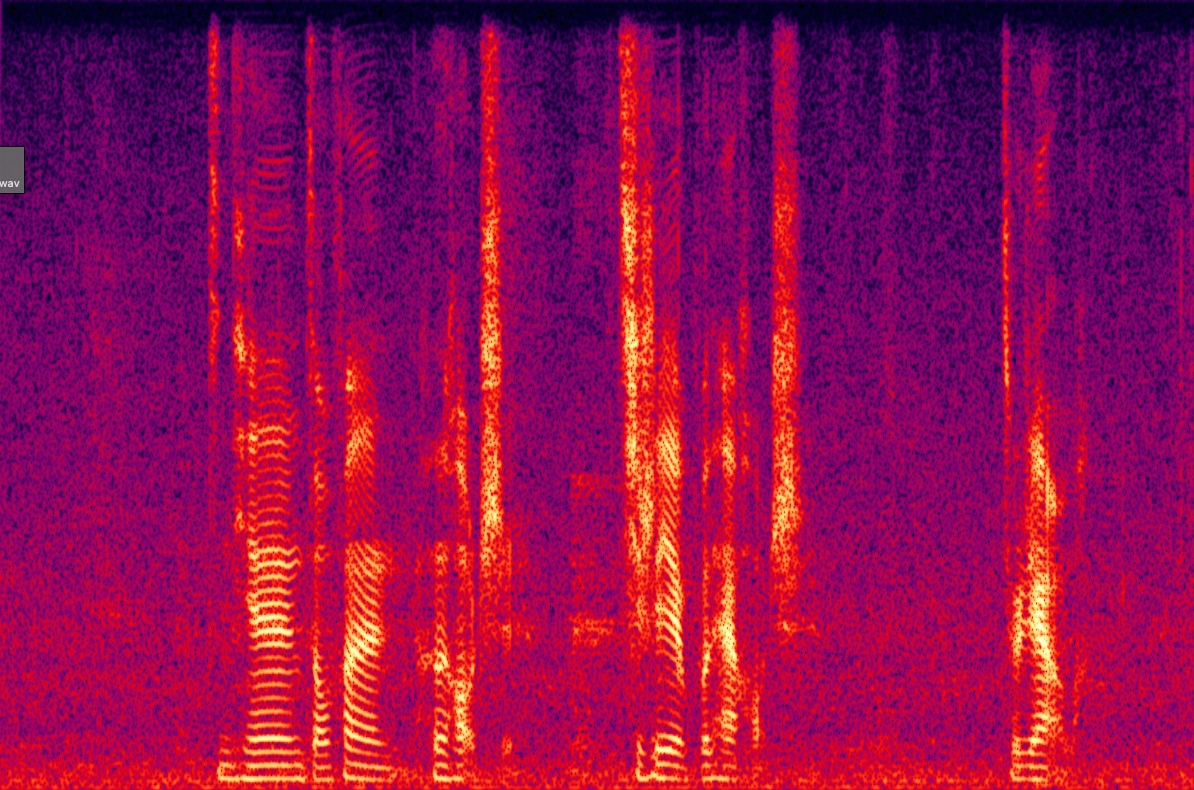
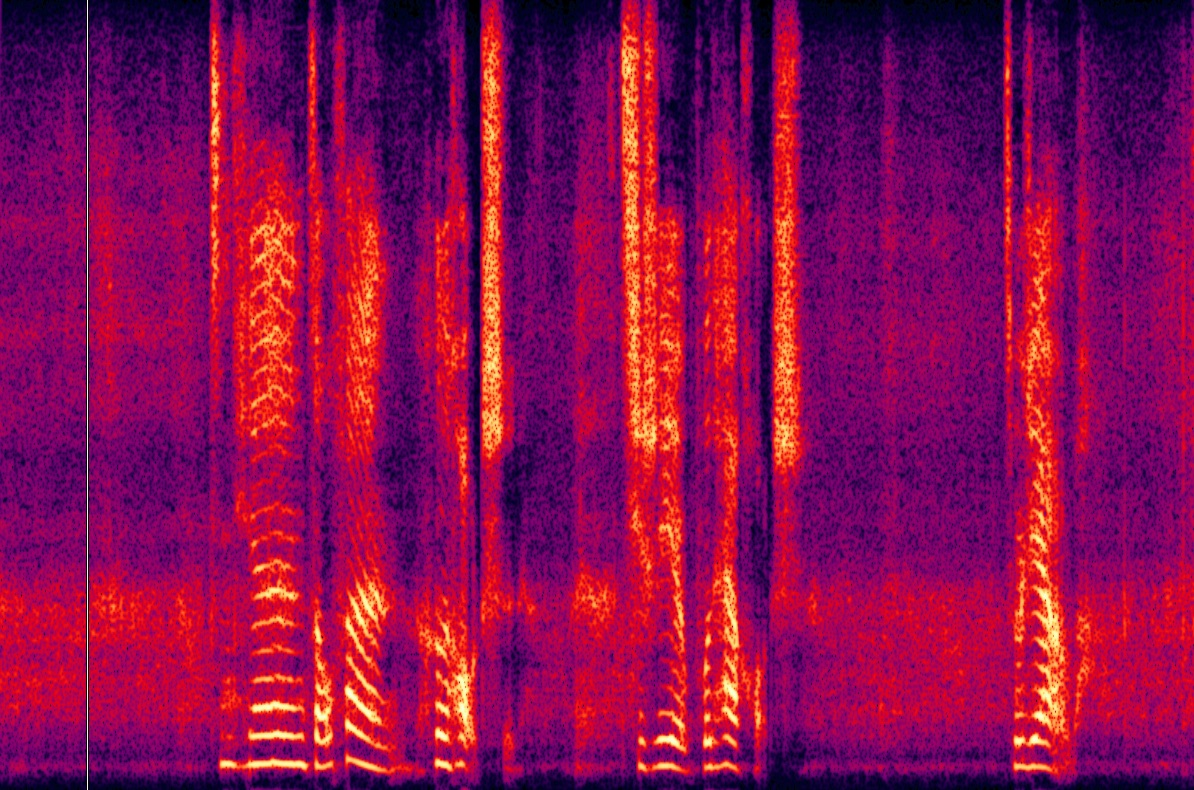
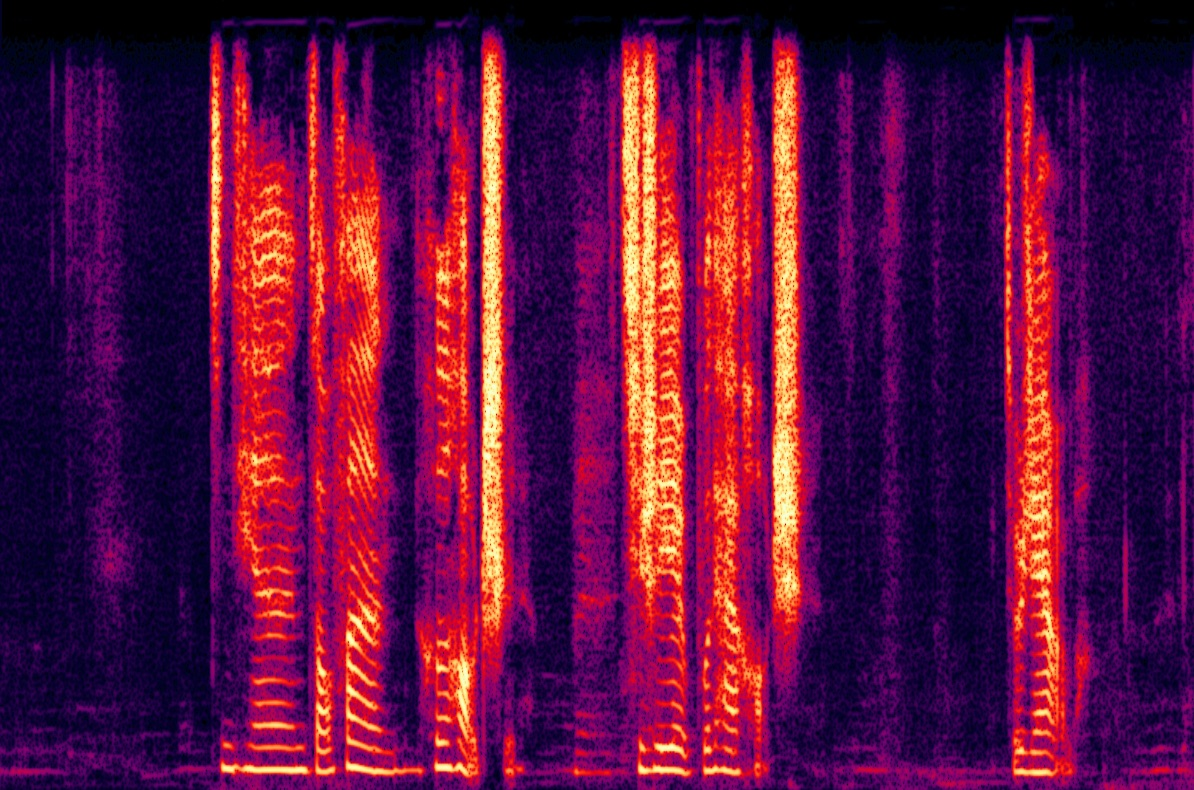
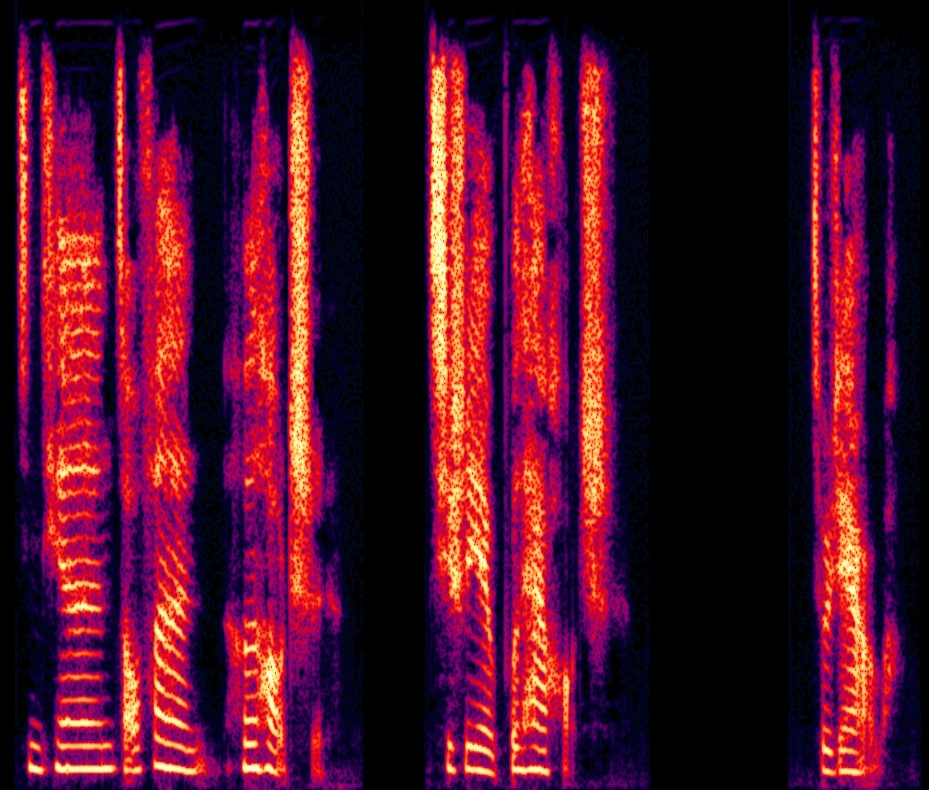
Figure 4: Spectrogram visualization of ablation experiments.
Conclusion
REF-VC effectively integrates BNF and SSL features through a random erasing strategy to enhance noise robustness while preserving expressiveness. It offers significant improvements over state-of-the-art systems in both subjective and objective evaluations, particularly in noise-robust scenarios. Shortcut Models significantly streamline inference without compromising quality, highlighting REF-VC's practical applicability in real-world VC tasks.
Future Work
Future developments aim at achieving an optimal balance between prosodic preservation and style transfer, addressing current user preferences for converting both timbre and style simultaneously. An additional focus will be on resolving existing limitations related to generating arbitrarily long speech, akin to TTS systems, due to inherent alignment constraints.