- The paper introduces LegalBench-RAG, a benchmark dedicated to evaluating retrieval accuracy in legal RAG systems.
- It employs advanced chunking strategies, like RTCS, to enhance extraction of minimal yet context-rich text snippets.
- Results reveal improved Recall metrics without additional rerankers, underscoring its practical value for legal AI applications.
LegalBench-RAG: A Benchmark for Retrieval-Augmented Generation in the Legal Domain
Abstract
LegalBench-RAG provides a specialized benchmark aimed at assessing the retrieval component of Retrieval-Augmented Generation (RAG) systems within the legal domain. Existing benchmarks like LegalBench focus on evaluating LLMs for their generative capacities, but they inadequately address the distinct retrieval challenges faced in legal contexts. LegalBench-RAG fills this gap by emphasizing minimal and highly relevant text snippets, crucial for legal document processing where context windows are constrained, and hallucination risks higher accuracy demands. Comprising 6,858 human-annotated query-answer pairs over a corpus exceeding 79 million characters, LegalBench-RAG stands as a pivotal asset for both academic research and commercial application development in enhancing RAG system performance in legal arenas.
Introduction
Retrieval-Augmented Generation (RAG) systems have emerged as quintessential tools in the legal technology landscape, combining document retrieval methodologies with generative LLMs to produce contextually-aware outputs. Despite this progress, current benchmarks such as LegalBench fail to robustly evaluate the retrieval aptitude of RAG models, particularly for legal texts which are structurally complex and terminologically dense. To remedy this, LegalBench-RAG specifically targets the retrieval process, providing a comparative evaluation tool designed for the legal industry.
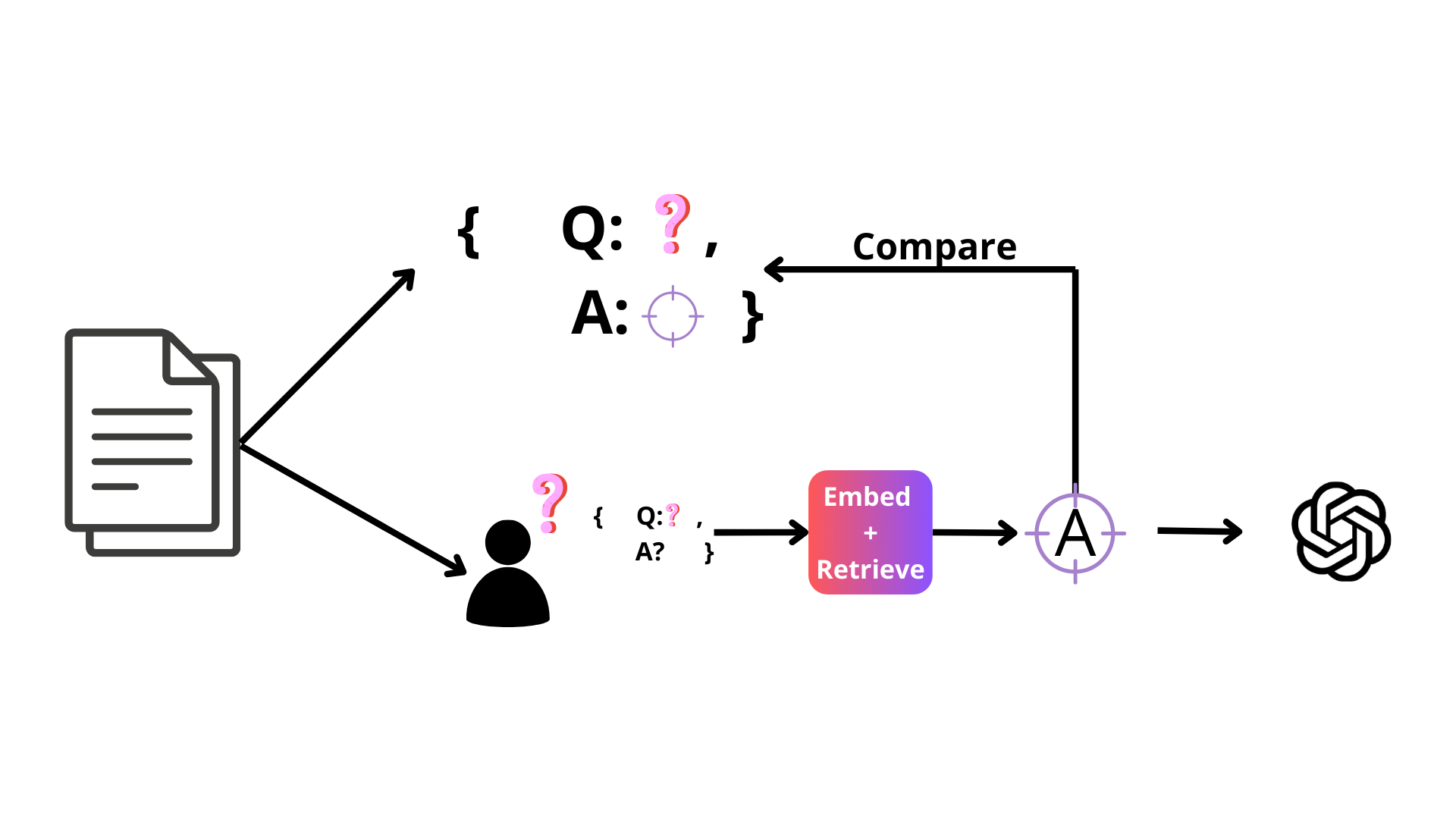
Figure 1: Benchmarking The Retrieval Step Of RAG Systems.
Dataset Construction and Quality Control
LegalBench-RAG's dataset is precisely curated from well-established legal resources, integrating comprehensive queries and corresponding document spans. Four primary datasets inform this benchmark: PrivacyQA, CUAD, MAUD, and ContractNLI. Each document undergoes a rigorous mapping from annotation points back to source material, ensuring annotations reflect high domain relevance. With legal professionals' oversight, each piece is vetted for conformity and precision, optimizing benchmark reliability.
Experimental Framework
LegalBench-RAG assesses retrieval process efficiency using the benchmark's datasets, such as CUAD and MAUD, emphasizing distinct chunking and reranking approaches. Experimentation shows that systems employing Recursive Text Character Splitters (RTCS) notably outperform naive chunking techniques, enhancing relevant retrieval precision and minimizing non-essential data return.
Results
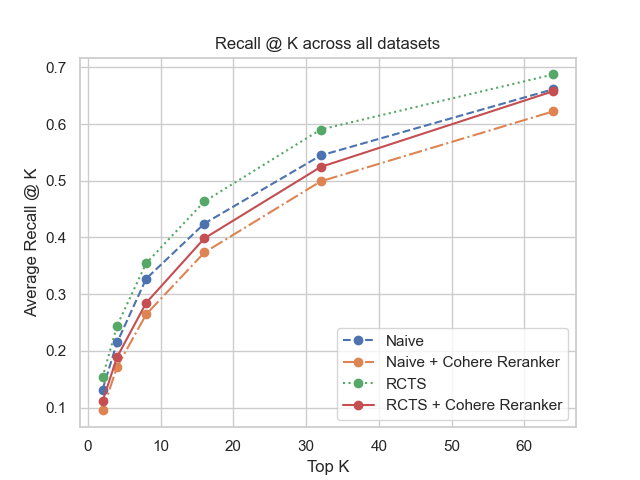
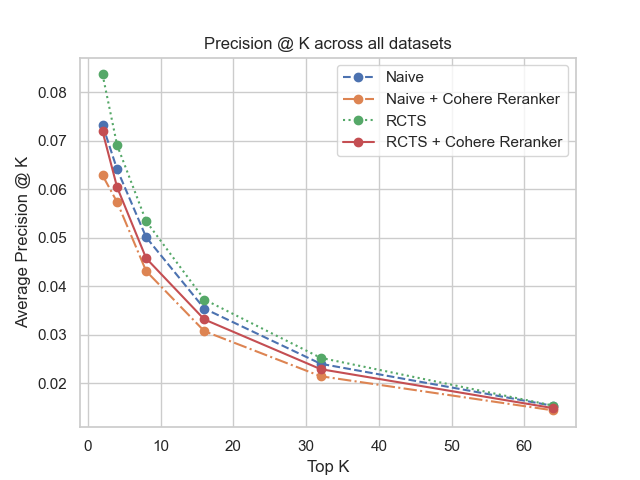
Figure 2: Recall @ k across all datasets.
The benchmark illustrates superior retrieval performance when advanced chunking strategies like RTCS are utilized, devoid of a post-retrieval reranker. Systems integrating such methodologies elevated Recall metrics, underscoring retrieval precision improvement potentials, crucial for legal applications where output integrity is paramount.
Limitations and Future Work
LegalBench-RAG, albeit thorough, does not encompass the full breadth of legal document types. It requires single-source document query responses, limiting evaluation of multi-document reasoning capabilities. Future expansions could incorporate diverse legal document forms and explore multi-hop reasoning complexities to further benchmark sophistication.
Conclusion
LegalBench-RAG fills a crucial void by offering a domain-specific retrieval benchmark for legal RAG systems. Its design allows practitioners to refine LLM-driven legal applications, enhancing retrieval accuracy and application reliability. As RAG systems continue to evolve, benchmarks like LegalBench-RAG will be indispensable for shaping future advancements in legal AI technology landscapes.