Minimal Convolutional RNNs Accelerate Spatiotemporal Learning
Abstract: We introduce MinConvLSTM and MinConvGRU, two novel spatiotemporal models that combine the spatial inductive biases of convolutional recurrent networks with the training efficiency of minimal, parallelizable RNNs. Our approach extends the log-domain prefix-sum formulation of MinLSTM and MinGRU to convolutional architectures, enabling fully parallel training while retaining localized spatial modeling. This eliminates the need for sequential hidden state updates during teacher forcing - a major bottleneck in conventional ConvRNN models. In addition, we incorporate an exponential gating mechanism inspired by the xLSTM architecture into the MinConvLSTM, which further simplifies the log-domain computation. Our models are structurally minimal and computationally efficient, with reduced parameter count and improved scalability. We evaluate our models on two spatiotemporal forecasting tasks: Navier-Stokes dynamics and real-world geopotential data. In terms of training speed, our architectures significantly outperform standard ConvLSTMs and ConvGRUs. Moreover, our models also achieve lower prediction errors in both domains, even in closed-loop autoregressive mode. These findings demonstrate that minimal recurrent structures, when combined with convolutional input aggregation, offer a compelling and efficient alternative for spatiotemporal sequence modeling, bridging the gap between recurrent simplicity and spatial complexity.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Minimal Convolutional RNNs Accelerate Spatiotemporal Learning — A Simple Explanation
What this paper is about
This paper introduces faster and simpler versions of popular neural networks used to predict how things change over space and time, like weather maps or fluid motion. The new models are called MinConvLSTM, MinConvGRU, and MinConvExpLSTM. They learn just as well as (and often better than) older models but train much faster.
The main questions the authors ask
- Can we make recurrent neural networks (RNNs) for videos and weather run much faster without losing accuracy?
- Can we keep the useful “look at nearby pixels” behavior of convolutional networks while making the time part (the “sequence” part) easy to compute in parallel?
- Do these faster models actually work well on real tasks, like fluid dynamics and global weather data?
How the method works (in everyday language)
Predicting things over space and time needs two skills:
- Space: Look at nearby spots (like neighboring pixels on a map). Convolutions do this well.
- Time: Remember what happened before. RNNs do this well.
Classic models that do both (ConvLSTM and ConvGRU) are powerful, but they process time one step after another. That’s like building a tower by placing one block at a time—you can’t speed it up much.
The authors take a smarter route:
- They use “minimal” RNNs (MinLSTM/MinGRU) that remove some tricky feedback loops inside the network. Think of it as a simpler recipe with fewer steps.
- They keep convolutions to handle space, so the model still pays attention to local areas (like nearby pixels).
- They transform the time computations so they can be done in parallel (many steps at once), using a technique similar to a “parallel assembly line.” This is called a “prefix-sum” or “scan.” It turns what used to be a slow, step-by-step process into one that many processors can do together.
- They do some math in “log space,” which basically changes multiplications into additions, making calculations more stable and easier to run in parallel.
- For one model (MinConvExpLSTM), they replace the usual “sigmoid gates” with “exponential gates,” which simplifies the math further and reduces how much work the computer has to do.
In short: keep the useful parts (convolutions for space), simplify the memory part (minimal RNN), and reorganize the math so the whole time sequence can be processed very quickly in parallel.
Key ideas they introduce
- Remove hidden-state feedback from the gates (the parts that decide what to remember). This makes the time updates linear and parallel-friendly.
- Use convolutions for inputs, so the model still understands local patterns in images/maps.
- Compute in the log domain and use a parallel “scan” to process entire sequences at once.
- Use exponential gates (MinConvExpLSTM) to share work between the gates and cut computation even more.
What they tested
They tested the models on:
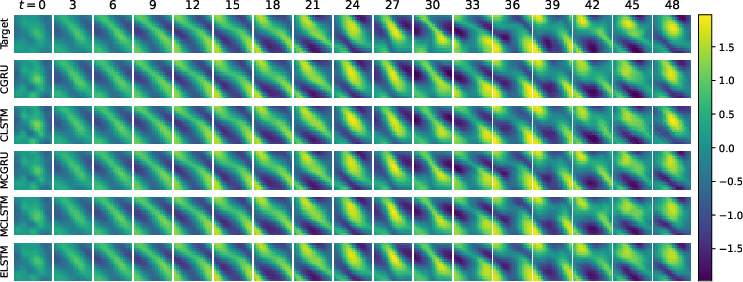
- Fluid motion (Navier–Stokes simulation): Predicting how a fluid moves across a 2D grid over time.
- Real-world weather (geopotential at 500 hPa): A standard weather map layer used by meteorologists to understand large-scale atmospheric patterns.
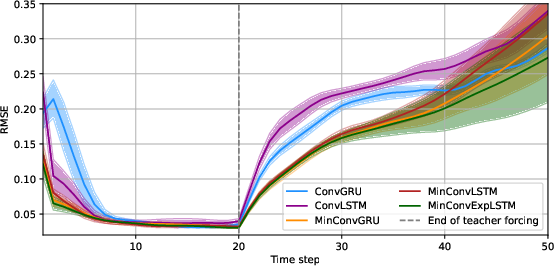
They trained with “teacher forcing” for the first part of each sequence (feeding the model the true previous frame), then switched to “closed loop,” where the model feeds its own predictions back in to forecast further into the future.
What they found and why it matters
Here are the main results:
- Training speed: Their models trained about 3–5 times faster than standard ConvLSTM/ConvGRU on the same hardware and settings.
- Accuracy: The minimal models didn’t just keep up—they often did better. On both fluid dynamics and weather data, the new models had lower prediction errors, including in the tougher “closed loop” setting.
- Best model: MinConvExpLSTM (with exponential gates) was the fastest and achieved the best accuracy on the fluid task.
- Fewer parameters and better scaling: The models are smaller and easier to scale to longer sequences.
- Hardware notes: The speed-ups depend on hardware. GPUs speed up a lot, but the benefit can shrink with very large images. TPUs keep stronger speed-ups even for large images.
Why this is important:
- Faster training means you can train on more data, try more ideas, and get results sooner.
- Better accuracy helps make more reliable forecasts (for instance, in weather nowcasting).
- Smaller models can be cheaper and more energy-efficient to run, which is helpful in real-world systems.
What this could lead to
These minimal convolutional RNNs show that you can have both speed and quality for space-time predictions. This could:
- Make real-time forecasting (like short-term weather nowcasts) more practical and affordable.
- Allow training on higher-resolution data or longer sequences.
- Encourage hybrid models that mix these fast recurrent parts with other tools (like attention) for even better global context.
- Inspire new designs that are simple, parallel, and strong—useful for any time-based data, from videos to climate to sensors.
Takeaway
By simplifying the “memory” part of ConvLSTMs/ConvGRUs and reorganizing the math to run in parallel, the authors built models that are both faster and more accurate for predicting how things change across space and time. Their approach keeps the good parts (learning local spatial patterns) while removing the slow parts (strict step-by-step time updates), showing a clear path to quicker and better spatiotemporal learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, written to guide actionable follow-up research:
- Scalability to higher spatial resolutions: Evaluate training/inference speed, memory, and accuracy at ≥256×256 and ≥512×512, where GPU convolution kernels and memory bandwidth become bottlenecks; include end-to-end profiling and kernel-level analysis.
- Long-horizon closed-loop stability: Test substantially longer autoregressive rollouts (≥100–1000 steps) to characterize error growth, drift, and stability relative to ConvRNNs, SSMs, and attention models.
- Batch size effects on speedups: Current results use batch size 1; quantify how speedups change with larger batch sizes and sequence lengths on GPUs vs TPUs (including mixed precision).
- Inference-time latency and throughput: Report decoding latency for single-step and multi-step inference, not just training-time speed; explore chunkwise/segment-parallel decoding strategies compatible with scan.
- Numerical stability in log-domain scan: Analyze underflow/overflow and accumulated floating-point error in prefix-scan over long sequences (FP32 vs FP16/BF16), and whether stability degrades with extreme gate values.
- Expressivity of input-only gating: Removing hidden-state-dependent gates may limit context-dependent control; benchmark on regime-switching, chaotic systems, and tasks requiring error-corrective gating to quantify any expressivity gap.
- Theoretical analysis of capacity: Provide formal characterization of the effective memory kernel and representational power of MinConvLSTM/GRU vs conventional ConvRNNs and SSMs (e.g., bounds, equivalences to LTV systems).
- Exponential gating behavior: Conduct ablations isolating MinConvExpLSTM’s exponential gating, including gate distribution statistics, gradient behavior, saturation, and calibration, as well as robustness to outliers.
- Architectural ablations: Systematically vary kernel sizes, dilations, depth, normalization types (LN/GN), skip connections, and encoder/decoder design to quantify what drives performance vs efficiency.
- Fairness of capacity matching: Parameter-count matching may not equalize effective capacity or FLOPs; include FLOPs, activations, and compute-time-normalized comparisons across models.
- Comparison with stronger baselines: Add modern non-recurrent and linear baselines (e.g., FNO, U-/UNet-style backbones, PredRNN/PredRNN++/PhyDNet/TrajGRU, Video Transformers, Mamba/S4-style spatiotemporal models).
- Multi-scale and hierarchical modeling: Implement and evaluate multi-resolution/tiling/pyramid variants to test whether scan-compatible minimal recurrence scales across spatial scales without losing locality.
- Irregular temporal sampling: Verify the claimed advantage of scan for irregular time steps by evaluating on non-uniformly sampled sequences; assess how gate computations adapt in this setting.
- Non-Euclidean/spherical domains: Replace planar convs with spherical or graph convolutions for global geophysical data; quantify impact near poles and at wrap-around boundaries.
- Multivariate and multimodal inputs: Test multi-channel atmospheric variables (e.g., winds, temperature), radar reflectivity, and coupled fields to assess cross-variable temporal gating without hidden-state feedback.
- Robustness and OOD generalization: Evaluate across changing regimes (e.g., different Reynolds numbers, seasons/years, climate shifts) and under noise/missing data to assess robustness of minimal gating.
- Uncertainty quantification: Extend to probabilistic forecasting (CRPS, reliability diagrams) using ensembling, variational methods, or distributional heads; assess behavior on extremes/heavy tails.
- Training curriculum and objectives: Study scheduled sampling, free-running training, multi-horizon losses, and curriculum rollouts to reduce exposure bias; quantify their effect on closed-loop performance.
- Energy and memory efficiency: Report GPU/TPU energy usage, peak memory, and activation checkpointing costs; quantify wall-clock vs energy trade-offs of scan vs sequential recurrence.
- Implementation portability: The TPU/GPU speed discrepancy suggests kernel-level constraints; explore custom CUDA/XLA kernels, operator fusion, and memory layouts to recover TPU-like speedups on GPUs.
- Precision and hardware sensitivity: Systematically evaluate FP16/BF16/FP32 trade-offs on different accelerators (A100/H100/TPUv4) to determine when scan remains advantageous.
- Application breadth: Validate on more demanding real-world tasks (e.g., precipitation nowcasting, ocean/sea-ice dynamics, high-res video) to probe limits and domain transferability.
- Error-correction in closed-loop: Since gates depend only on inputs, explore mechanisms (e.g., lightweight state-feedback, hybrid attention) that retain scan-compatibility but enable corrective dynamics during free running.
- Code and reproducibility details: Provide full code, exact preprocessing/normalization, kernel specs, padding/boundary conditions, and seeds to ensure reproducibility across hardware and frameworks.
Collections
Sign up for free to add this paper to one or more collections.