- The paper introduces MAO-ARAG, a novel multi-agent system that dynamically tailors retrieval-augmented generation workflows to handle diverse query complexities.
- It employs reinforcement learning with PPO to balance high answer quality against resource usage, specifically optimizing token consumption and execution costs.
- Experimental results demonstrate significant F1 score improvements and enhanced resource efficiency compared to traditional fixed RAG pipelines.
MAO-ARAG: Multi-Agent Orchestration for Adaptive Retrieval-Augmented Generation
The paper "MAO-ARAG: Multi-Agent Orchestration for Adaptive Retrieval-Augmented Generation" introduces an innovative framework called MAO-ARAG, designed to enhance the accuracy and efficiency of question answering (QA) systems through dynamic query-specific workflows. The paper emphasizes the challenges posed by the heterogeneous nature of real-world queries and proposes a multi-agent system with reinforcement learning optimization to tailor the Retrieval-Augmented Generation (RAG) process.
Introduction to RAG Systems
RAG systems have become crucial in QA systems due to their ability to integrate external knowledge, reducing hallucinations and improving answer quality. Traditional RAG systems, whether single-round, iterative, or reasoning-based, often apply fixed pipelines that struggle to handle varying query complexities effectively. This constraint leads to inefficiencies in balancing performance and costs, such as latency and token consumption.
The introduction of MAO-ARAG addresses these concerns by utilizing a planner agent to intelligently orchestrate multiple executor agents, adapting RAG workflows to individual query requirements. This orchestration is driven by reinforcement learning using Proximal Policy Optimization (PPO), ensuring high-quality responses while optimizing computational costs.
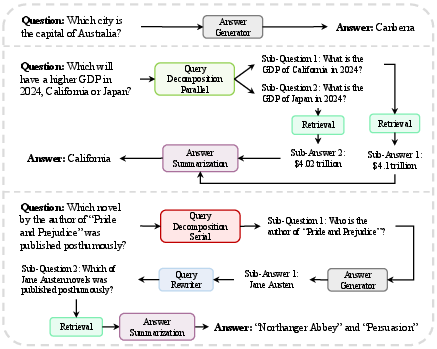
Figure 1: The appropriate workflows for different types of queries are highly heterogeneous.
Modular Framework of MAO-ARAG
MAO-ARAG is conceptualized as a Multi-Agent Semi-Markov Decision Process (MSMDP), capturing the intricacies of agent coordination. Its architecture includes:
- Executor Agents: Comprised of modules like Query Decomposition Serial (QDS), Query Decomposition Parallel (QDP), Query Rewriter (QR), Document Selector (DS), Retrieval Agent (RA), Answer Generator (AG), and Answer Summarization (AS).
- Planner Agent: Responsible for selecting appropriate executors based on the query, forming a personalized workflow.
The MSMDP framework allows for heterogeneous action durations, reflecting the modular and adaptive nature of the system.
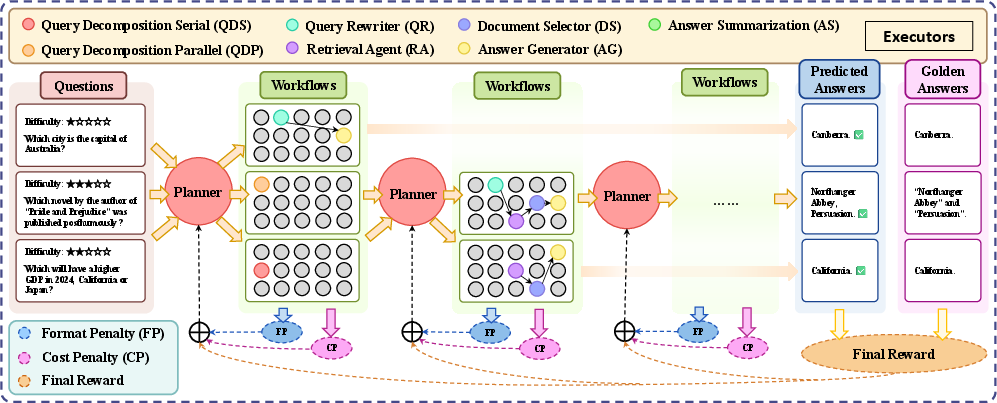
Figure 2: The overall framework of MAO-ARAG.
Reinforcement Learning Optimization
The planner agent's decision-making is optimized using PPO, with a reward function composed of the F1 score and penalties for token usage and workflow execution costs. The training process involves multiple query-specific rounds where agents execute workflows, resulting in a final answer evaluated against the golden standard. This setup not only enhances answer quality but also manages costs effectively.
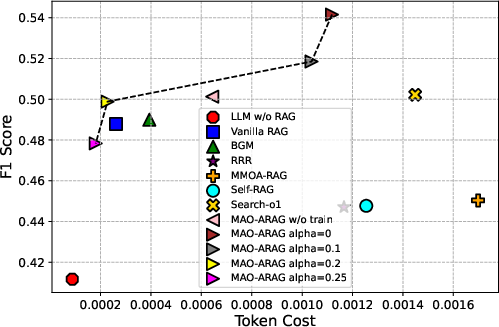
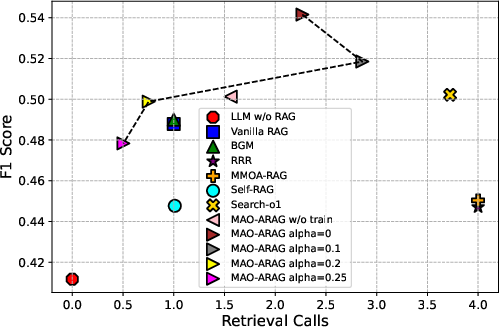
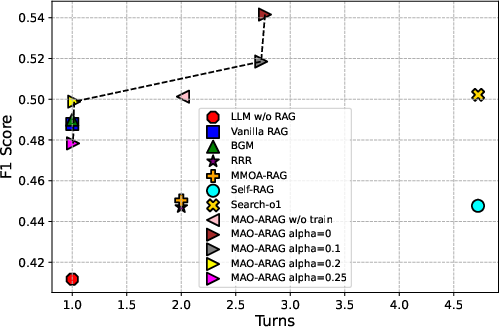
Figure 3: F1 score vs. Token Cost
Experimental Validation
Experiments conducted on diverse QA datasets demonstrate that MAO-ARAG significantly outperforms fixed RAG pipelines in terms of F1 score, while maintaining resource efficiency. The average F1 score improvement across datasets indicates the flexibility and adaptability of the framework.
By tuning the α hyperparameter in the reward function, MAO-ARAG achieves a balance between effectiveness and cost, showcasing its capability to adjust to varying query demands.
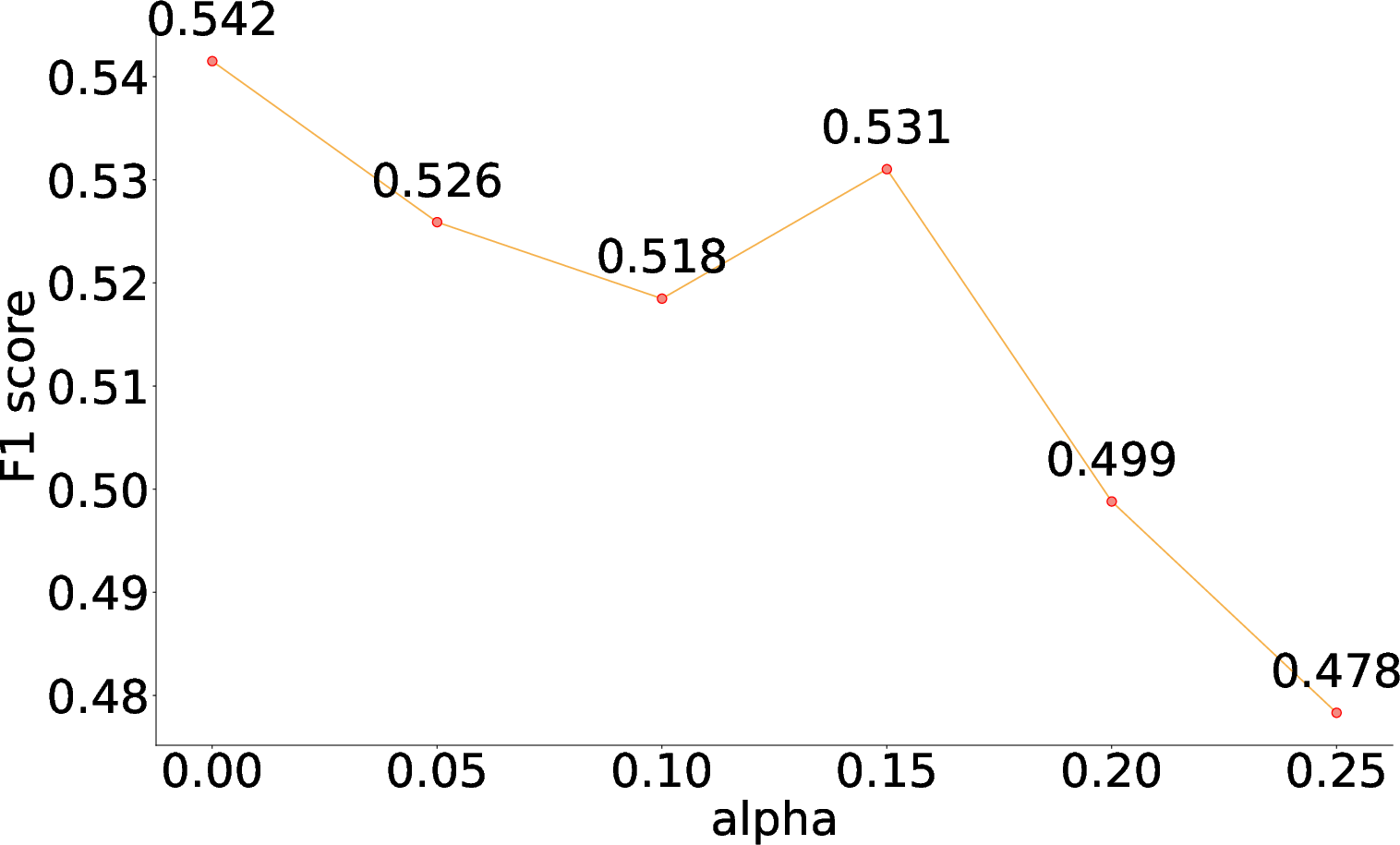
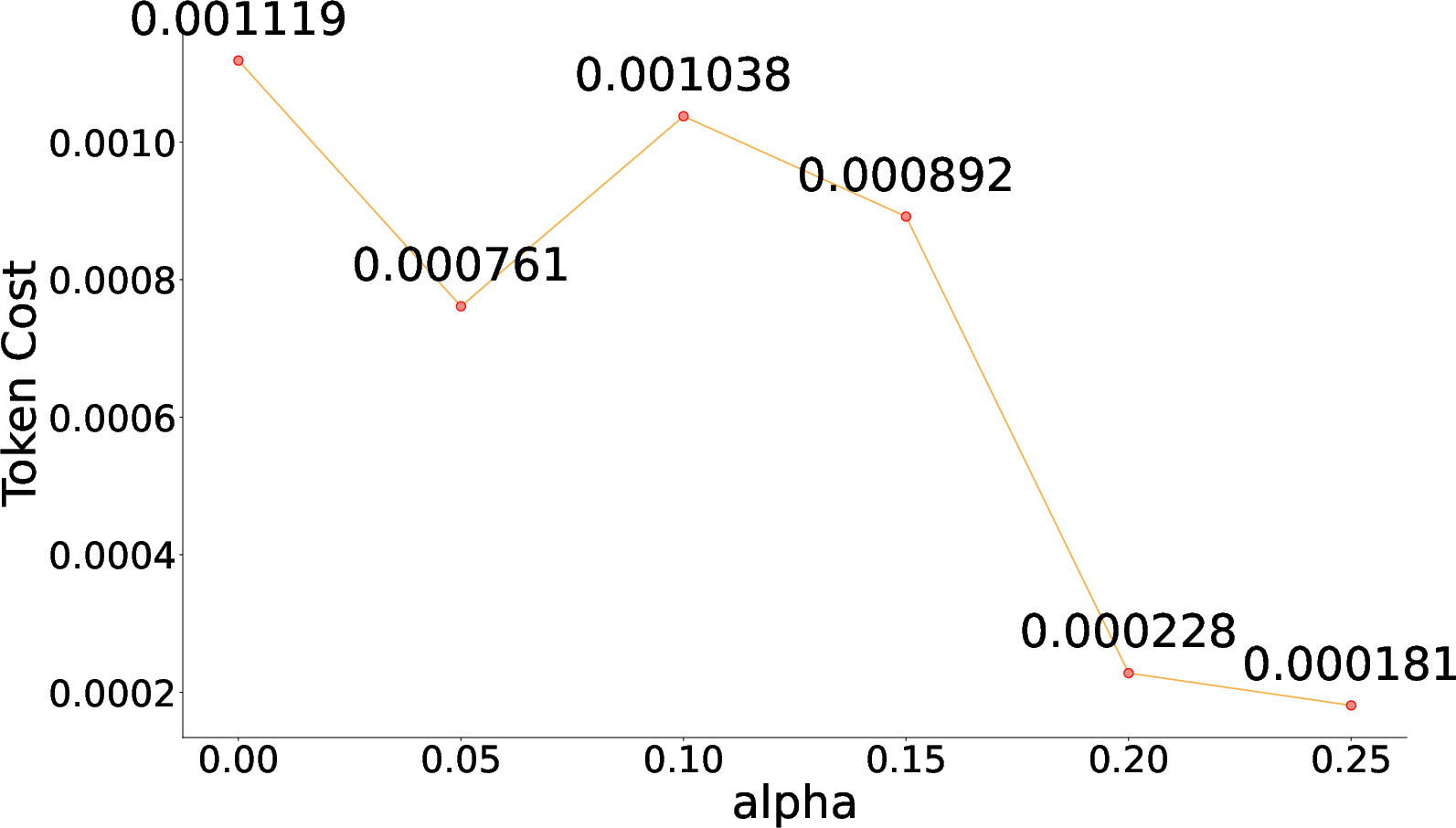
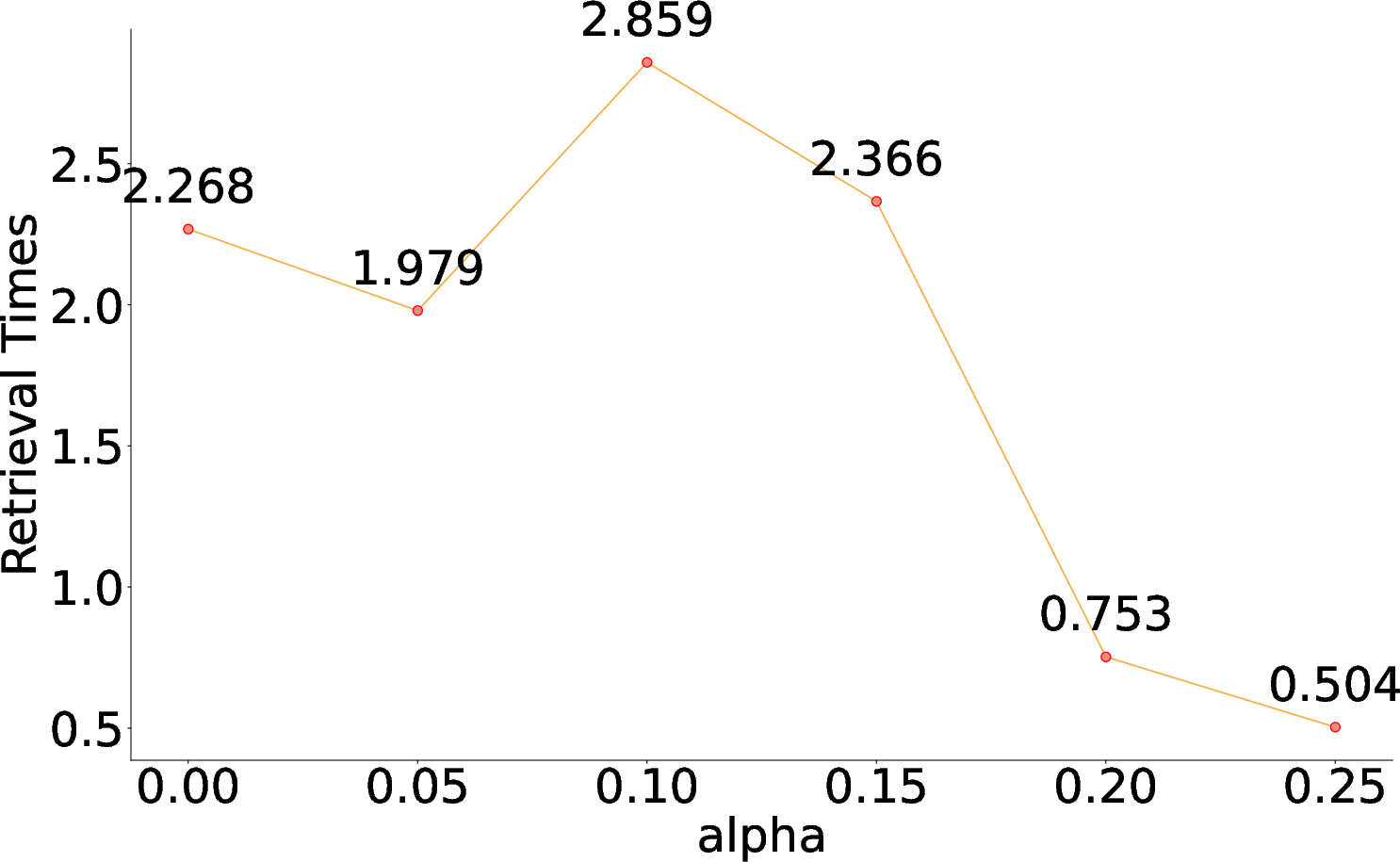
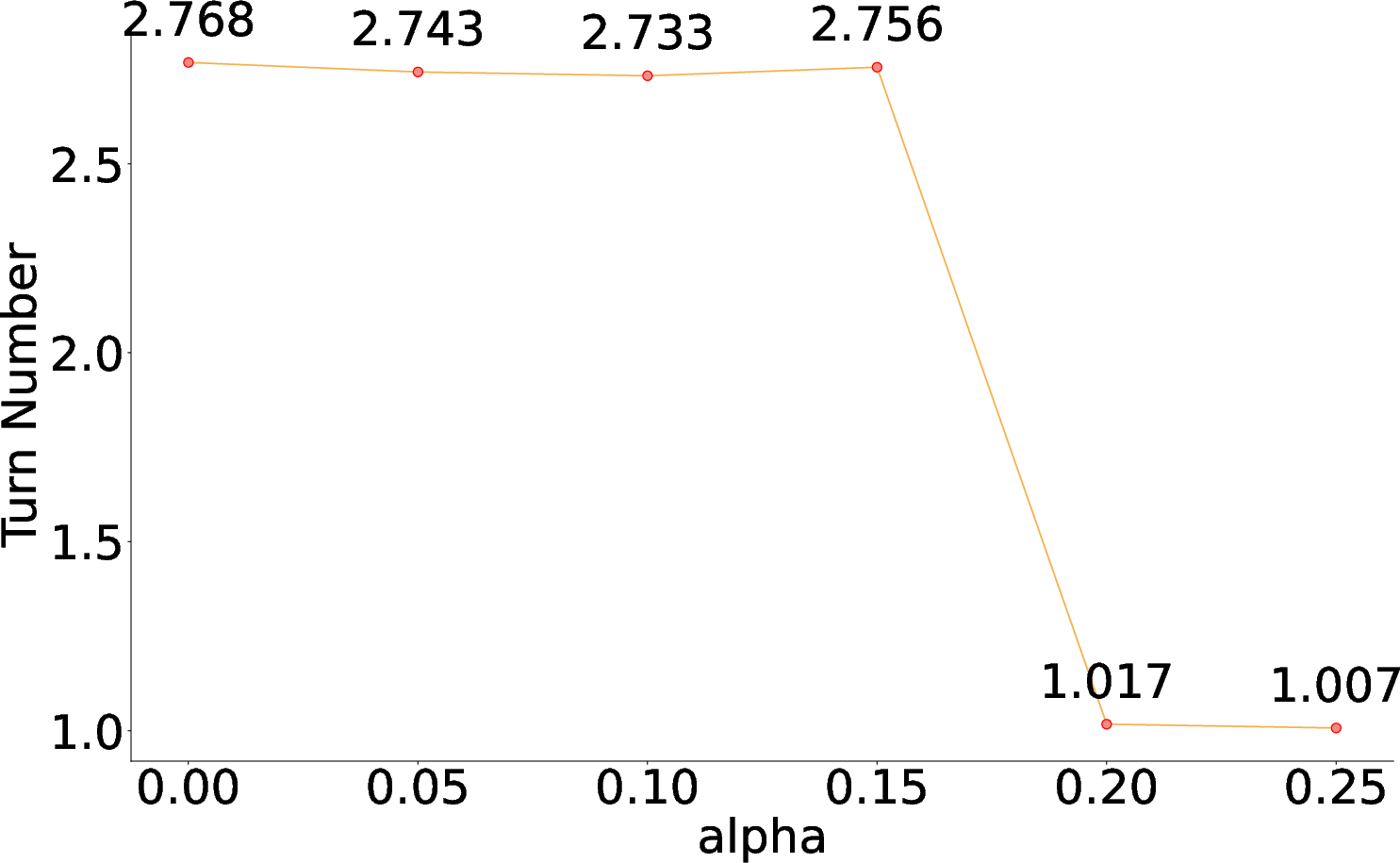
Figure 4: F1 Score vs. α
Conclusion
MAO-ARAG sets a new standard in adaptive RAG systems for QA by dynamically constructing query-specific workflows through multi-agent orchestration. The use of reinforcement learning ensures high-level performance while optimizing resource usage. Future research directions include refining cost penalties and exploring multi-modal agent configurations to further enhance efficiency and adaptability.