- The paper introduces security tensors that transfer the safety mechanisms of text to visual inputs without modifying the model parameters.
- It demonstrates significant improvements in rejecting harmful visual content while maintaining performance on benign tasks.
- The method achieves robust generalization across seen and unseen malicious categories with minimal trade-offs in model performance.
Security Tensors as a Cross-Modal Bridge in LVLMs
This paper introduces "security tensors," a novel approach to enhance the safety of Large Vision-LLMs (LVLMs) against harmful visual inputs by extending text-aligned safety mechanisms to the visual modality. The method involves training input vectors, referred to as security tensors, that can be applied during inference to either the textual or visual modality, effectively transferring textual safety alignment to visual processing without modifying the model’s parameters. The paper demonstrates that security tensors significantly improve LVLMs' ability to reject diverse harmful visual inputs while maintaining performance on benign tasks.
Background and Motivation
LVLMs, which integrate LLMs with visual modules, are vulnerable to harmful image inputs because the safety mechanisms developed for text-based LLMs do not naturally extend to visual modalities. This discrepancy arises because the visual understanding stage occurs after the language module's training, causing inconsistencies in encoding across modalities that can be exploited by malicious visual inputs. Existing methods to address this issue often involve fine-tuning model parameters using additional visual safety datasets, leading to disjointed security architectures and high computational costs. The paper posits that a more effective approach would leverage the language module’s intrinsic capacity to distinguish malicious content by directly perturbing input representations to align harmful visual patterns with textual safety-aligned semantic space.
Methodology: Security Tensors
The core of the proposed method is the introduction of security tensors, which are trainable input perturbations injected into either the textual or visual modalities. These tensors are designed to activate the language module’s pre-trained textual safety mechanisms in response to visual inputs. The security tensors are optimized using a curated dataset comprising three subsets:
- Safety Activation (SA) Set: Malicious image-text pairs paired with rejection outputs train the model to associate harmful visual patterns with the language module’s pre-trained safety mechanisms.
- Text Contrast Benign (TCB) Set: Benign image-text queries with syntactic/structural similarity to malicious inputs ensure that the tensors learn visual safety cues rather than exploiting textual artifacts.
- General Benign (GB) Set: General benign image-text pairs maintain the model’s performance on harmless tasks, preventing over-restriction.

Figure 1: Examples of image-text query for SA, TCB, and GB ets, highlighting the intentional textual similarity between the TCB and SA sets.
Implementation Details
Textual security tensors, denoted as δt, are learnable vectors in the embedding space of LVLMs and are inserted between the image and text token embeddings. The perturbed embedding sequence $\tilde{\mathbf{E}$ is formulated as:
$\tilde{\mathbf{E} = [\mathbf{E}_{\text{img}; \delta_t; \mathbf{E}_{\text{text}],$
Visual security tensors, denoted as δv, are applied to the preprocessed image space. By operating on the preprocessed image rather than the raw input image, δv can adapt to arbitrary input resolutions.
Experimental Evaluation
The authors conducted experiments to evaluate the effectiveness and generalization ability of the security tensors. The models were tested on both "seen-category" samples (harmful image categories present in the training set) and "unseen-category" samples (novel harmful categories absent in training). The Harmless Rate (HR), defined as the proportion of queries that the LVLM successfully refuses to answer, was used as the primary metric for security performance. Benignness was assessed using the False Rejection Rate (FRR) and the MM-Vet score.
The experimental results indicate that both textual and visual security tensors significantly enhance the visual safety of LVLMs. The effectiveness of the security tensors correlates positively with the inherent safety of the language module in each LVLM. Both δv and δt improve the model's safety performance on harmful image categories in the training dataset and generalize well to unseen malicious categories. In terms of benignness, the introduction of δv and δt causes minimal performance degradation.
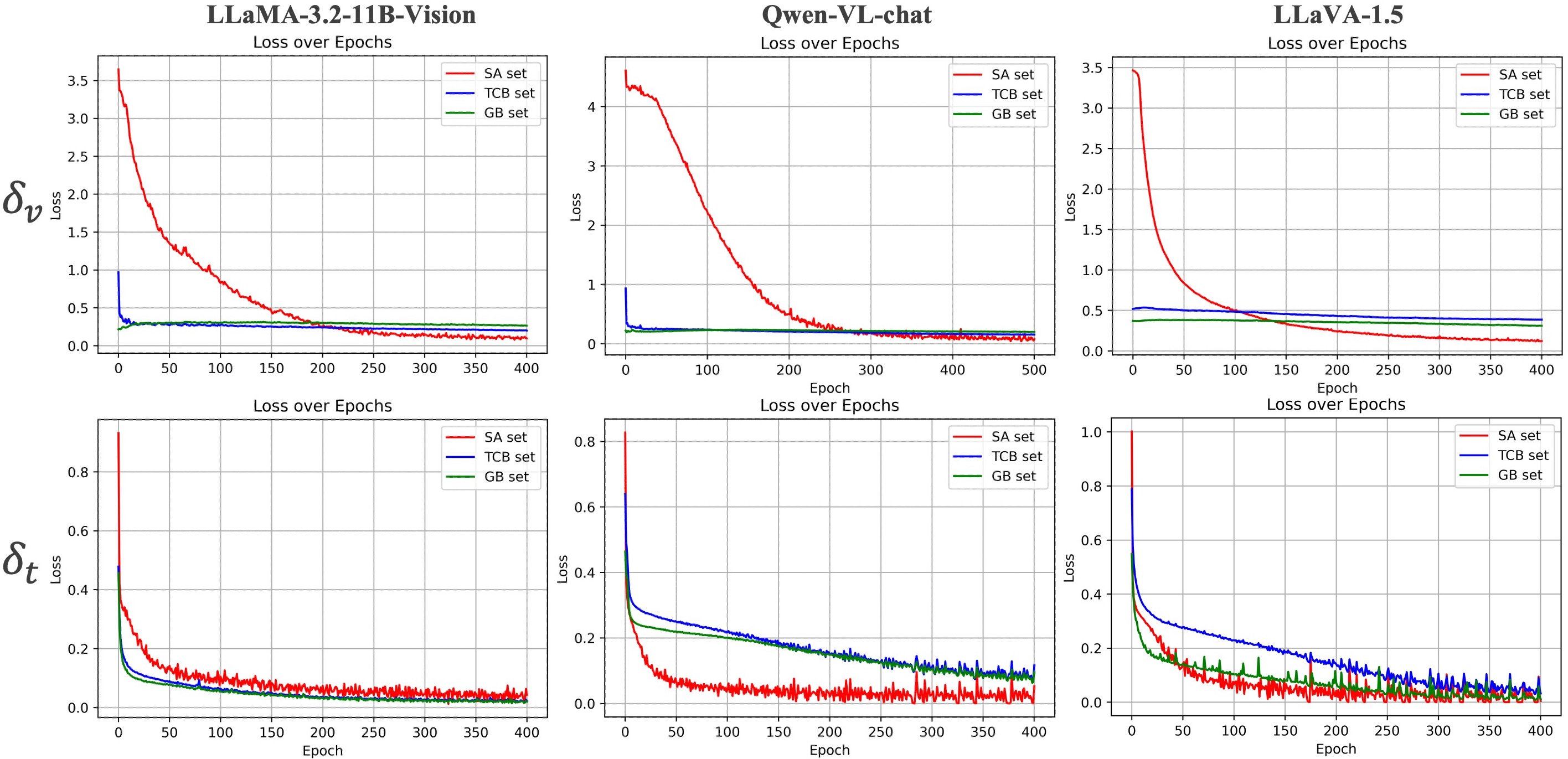
Figure 2: Training loss curves for δv and δt across LVLMs, showing visual and textual tensor training loss values across epochs.
Internal Analysis: Safety Layer Activation
The paper includes an internal analysis of the LVLM's hidden-layer representations to understand how security tensors achieve cross-modal safety activation. The analysis identifies "safety layers" within the LVLM’s language module that play a crucial role in distinguishing malicious textual content from benign content. The introduction of either visual or textual security tensors reactivates these safety layers during harmful image-text processing, aligning their activation patterns with those seen in text-based safety scenarios. This suggests that security tensors successfully extend the language module’s pre-trained textual safety mechanisms to handle visual content.
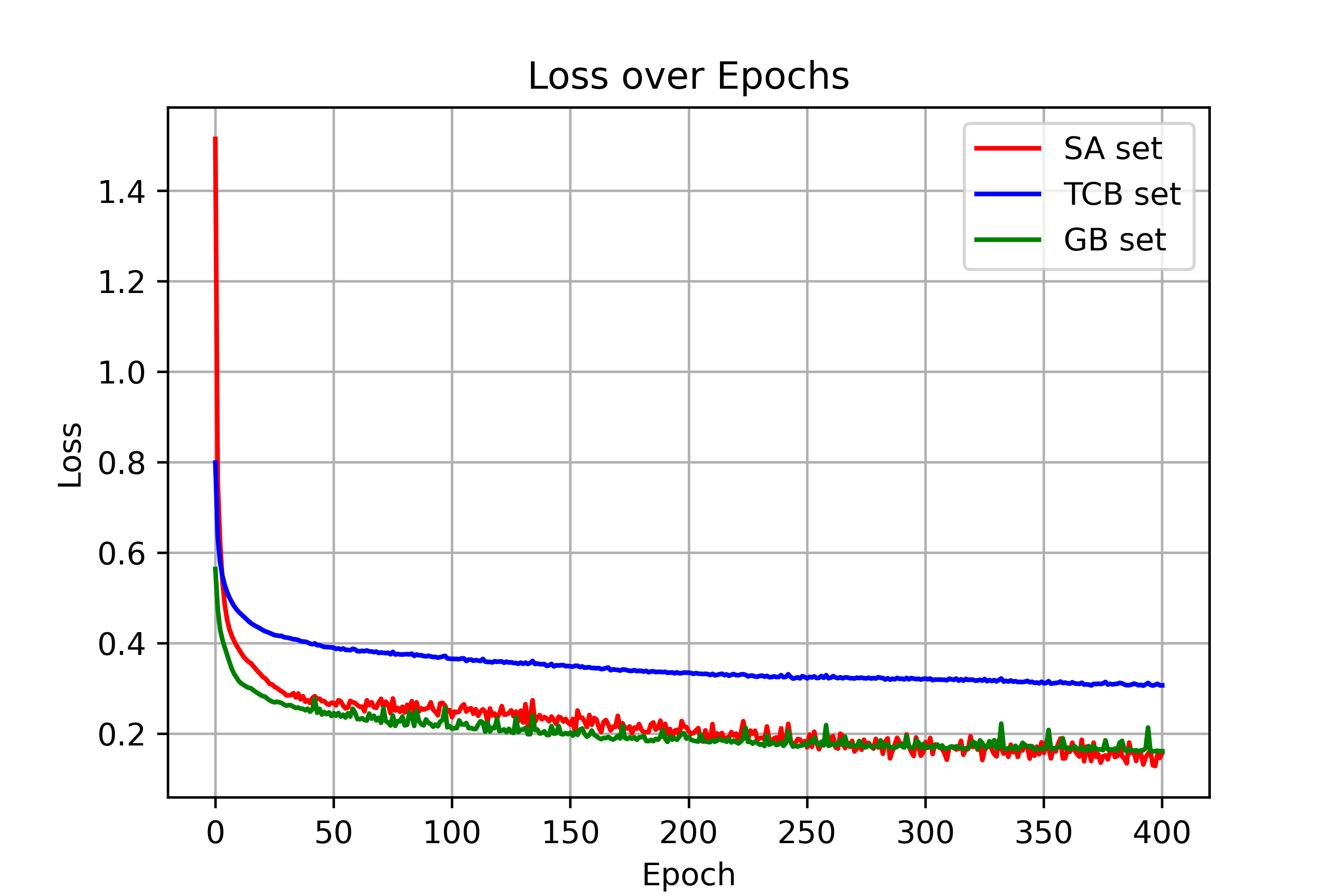
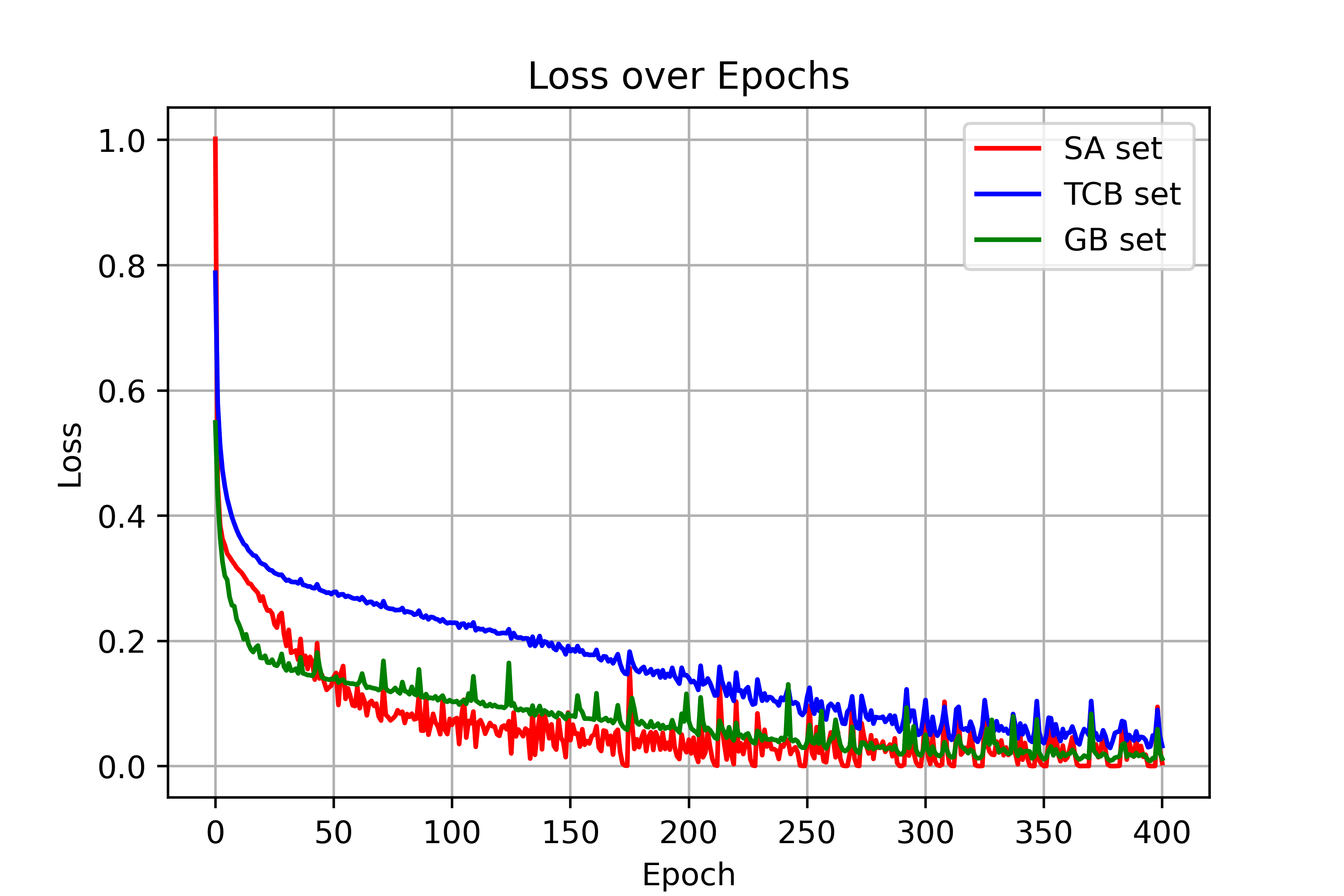
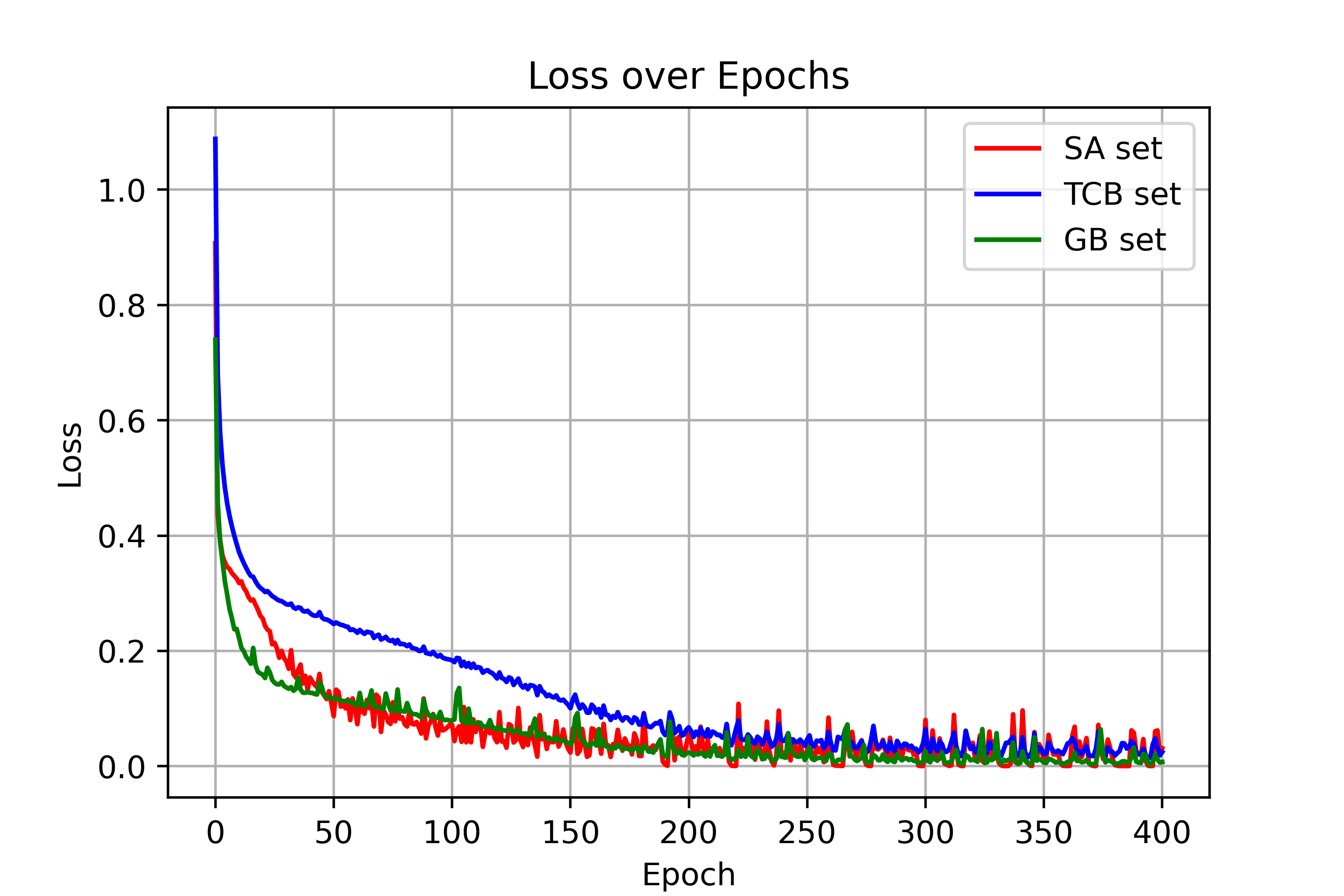
Figure 3: (n=10)
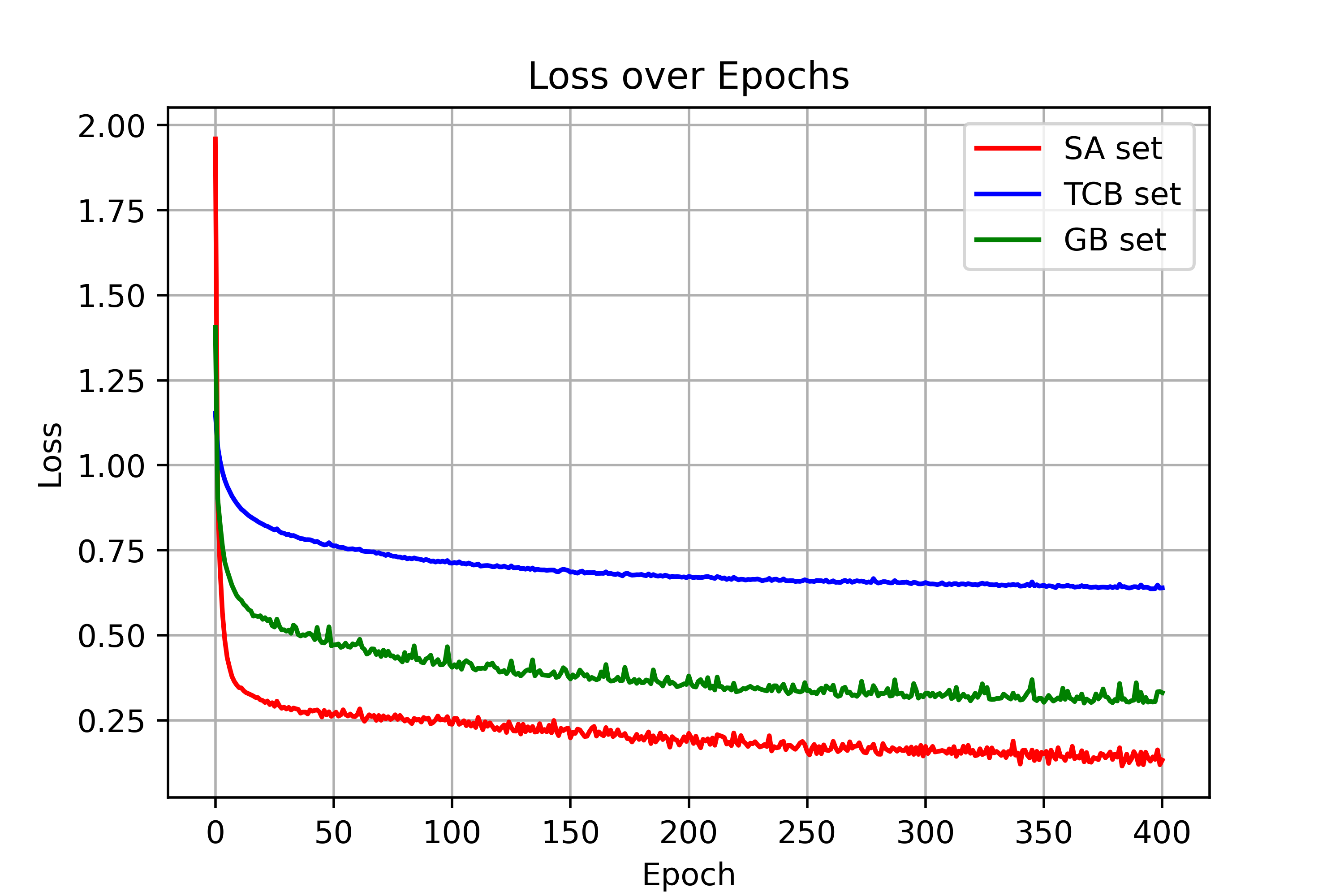
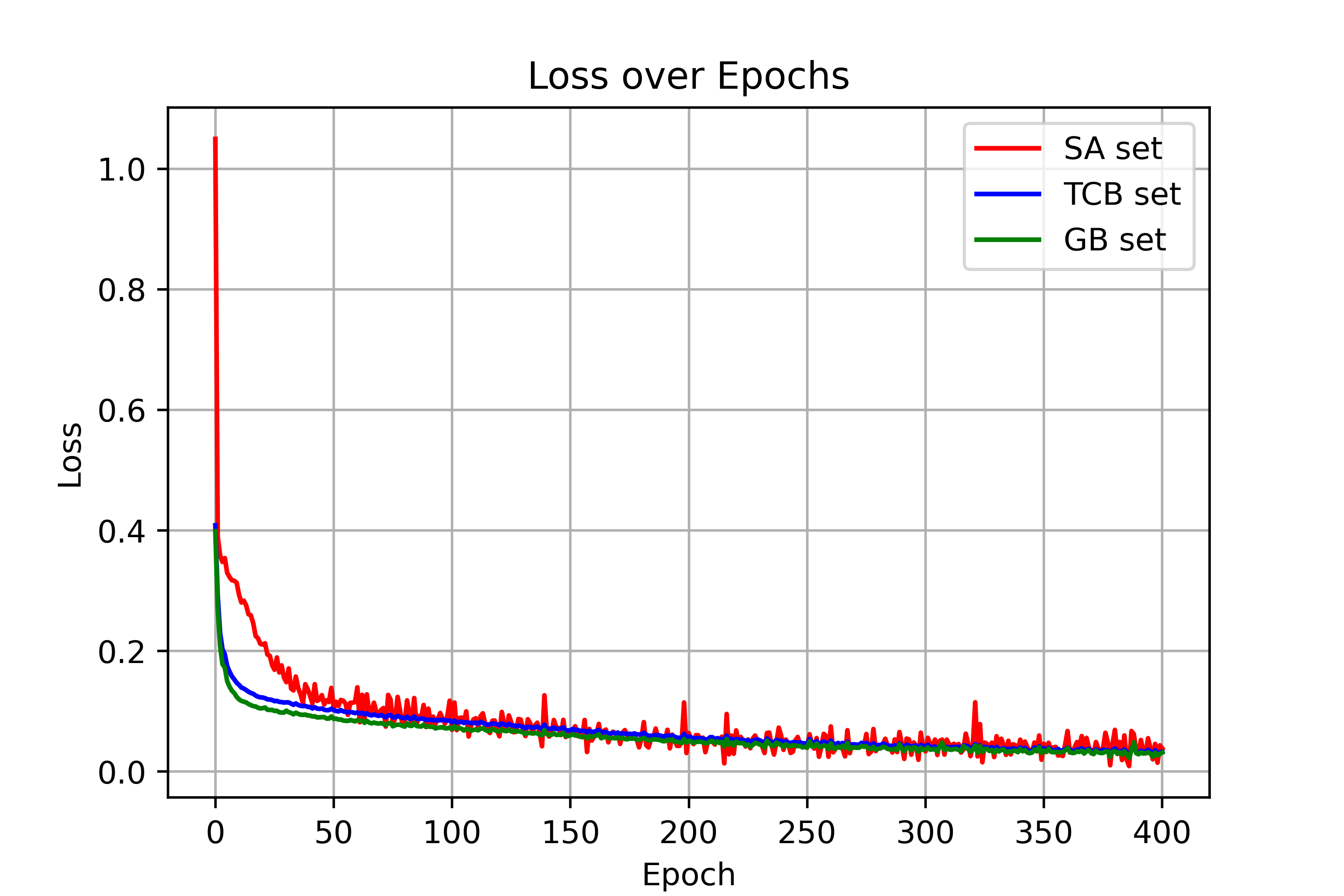
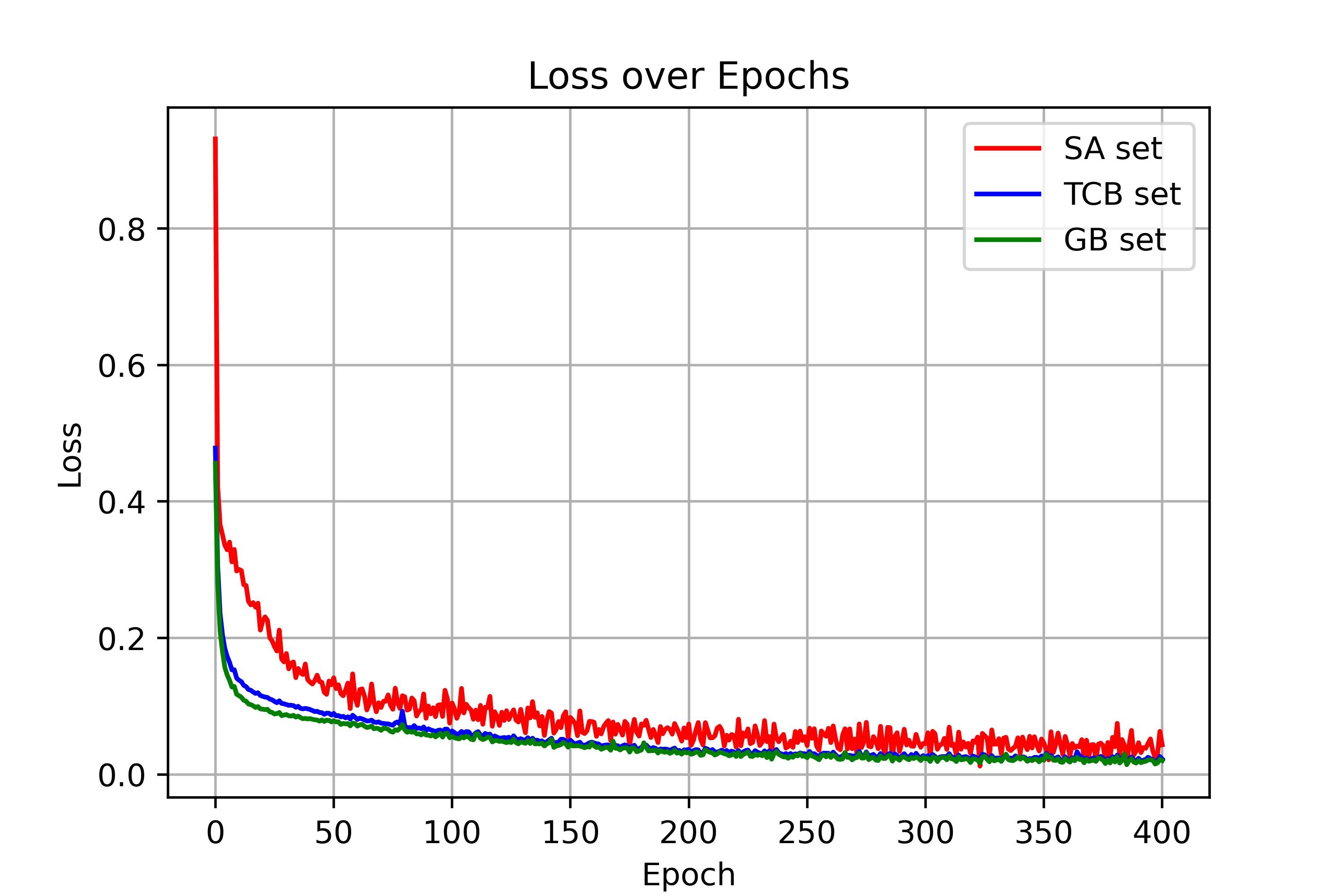
Figure 4: (n=10)

Figure 5: Examples of adversarial image-text query examples for SA and new TCB test set, highlighting the intentionally designed textual similarity between the two sets.
Ablation Studies
Ablation studies were conducted to assess the importance of the Text Contrast Benign (TCB) set. The results indicated that training security tensors without the TCB set led to a significant drop in the harmless rate and increased false rejection rate, suggesting that the TCB set is crucial for guiding the security tensors to attend to visual information.
Conclusion
The paper demonstrates that text-aligned safety mechanisms in LVLMs can be effectively extended to the visual modality via input-level security tensors. The security tensors act as a bridge between modalities, enabling LVLMs to generalize safety behavior from text to vision while preserving performance on benign inputs. This approach not only improves robustness against visual threats but also provides insights into cross-modal safety alignment, offering a practical pathway for improving safety in multimodal models.

