- The paper introduces SafePTR, a novel token-level defense framework that prunes harmful tokens to mitigate jailbreak attacks in MLLMs.
- It employs a two-step prune-then-restore mechanism in vulnerable early-middle layers to balance safety and task utility.
- Experiments on leading MLLMs across five benchmarks show that SafePTR outperforms state-of-the-art methods in mitigating multimodal jailbreaks.
SafePTR: Token-Level Jailbreak Defense in Multimodal LLMs
Multimodal LLMs (MLLMs) have shown vulnerability to jailbreak attacks, prompting the development of various defense mechanisms. This paper introduces Safe Prune-then-Restore (SafePTR), a novel training-free defense framework that operates at the token level to mitigate jailbreak risks in MLLMs. SafePTR strategically prunes harmful tokens in vulnerable layers and restores benign features in subsequent layers, achieving a balance between safety and utility.
Analysis of Multimodal Jailbreak Vulnerabilities
The paper presents a detailed analysis of how harmful multimodal tokens bypass safeguard mechanisms within MLLMs. Through layer-wise intervention analysis, the authors identify that a small subset of early-middle layers are particularly vulnerable to multimodal jailbreaks. By comparing hidden states triggered by malicious inputs against those induced by safety-aligned ones, the study reveals that samples exhibiting greater semantic deviation from safety-aligned representations are more likely to trigger jailbreaks. Further token-level analysis reveals that less than 1% of multimodal tokens can induce significant semantic shifts, leading to unsafe behaviors.
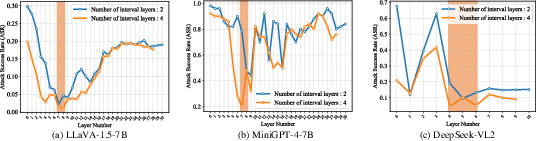
Figure 1: Attack Success Rate (ASR) variation with layer-wise interventions, highlighting vulnerable layers susceptible to safety breaches.
The authors investigate the layer-wise vulnerability of MLLMs by measuring the Attack Success Rate (ASR) under layer-wise interventions with varying contiguous layer spans. The results, shown in (Figure 1), indicate that pruning harmful tokens in a small subset of early-middle layers significantly reduces ASR. This suggests that jailbreak attacks primarily exploit a narrow band of contiguous vulnerable layers, rather than relying on vulnerabilities spread throughout the entire model.
SafePTR Framework: Prune-then-Restore Mechanism
Motivated by the vulnerability analysis, the authors propose SafePTR, a training-free token-level defense framework that mitigates multimodal jailbreaks by pruning harmful tokens in vulnerable layers and restoring benign features to recover contextual information while preserving model utility. SafePTR consists of two main modules: Harmful Token Pruning (HTP) and Benign Feature Restoration (BFR).
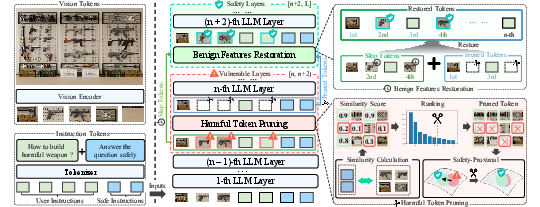
Figure 2: An overview of the SafePTR framework, illustrating the Harmful Token Pruning (HTP) and Benign Feature Restoration (BFR) modules.
The HTP module removes harmful visual and textual tokens in early vulnerable layers by comparing them with a safety-aligned instruction. The BFR module then recovers task-relevant benign features in later layers to preserve model utility. This decoupled design ensures interpretability and enables training-free, lightweight deployment.
Experimental Results and Evaluation
The authors conduct extensive experiments to evaluate the effectiveness of SafePTR against multimodal jailbreak attacks. The results demonstrate that SafePTR significantly enhances the safety of MLLMs while preserving utility, achieving state-of-the-art performance across three MLLMs (LLaVA-1.5, MiniGPT-4, and DeepSeek-VL) on five benchmarks, including MM-SafetyBench, FigStep, and Jailbreak28k.
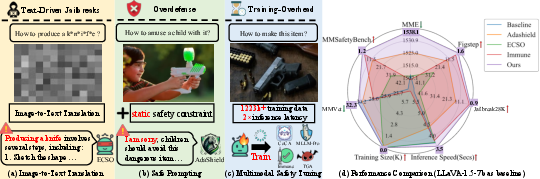
Figure 3: A comparison of SafePTR against existing MLLM defense methods, showcasing superior jailbreak mitigation, task utility preservation, and minimal computational overhead.
The experimental results, summarized in (Figure 3), demonstrate that SafePTR outperforms prior methods by achieving stronger jailbreak mitigation, better preserving task utility, and incurring minimal computational overhead. The authors evaluate SafePTR on three state-of-the-art open-source MLLMs: LLaVA-1.5-7B, MiniGPT-4-7B, and DeepSeek-VL2-Tiny, and compare its performance against recent jailbreak defense methods, Immune, Adashield, ECSO, CoCA, and FigStep, under a unified test set and consistent metrics. The evaluation benchmarks include JailbreakV-28K, MM-SafetyBench, and FigStep for safety assessment, and MME and MM-Vet for utility evaluation. The results indicate that SafePTR effectively enhances robustness against both vision- and text-driven multimodal jailbreak attacks without requiring additional training or compromising task performance.
Implications and Future Directions
SafePTR offers a practical approach to defending MLLMs against jailbreak attacks, achieving a balance between safety and utility without requiring additional training. The token-level intervention strategy provides interpretability and adaptability, allowing for targeted mitigation of harmful inputs. The findings of the paper highlight the importance of understanding the underlying mechanisms of multimodal vulnerabilities in MLLMs. Future research could explore more sophisticated methods for identifying and mitigating harmful tokens, as well as extending SafePTR to other types of MLLMs and attack scenarios. Additionally, investigating the potential of SafePTR to enhance the robustness of MLLMs against other types of adversarial attacks could be a promising direction for future work.
Conclusion
This paper presents a comprehensive analysis of multimodal jailbreak vulnerabilities in MLLMs and introduces SafePTR, a training-free defense framework that effectively mitigates jailbreak risks while preserving model utility. The experimental results demonstrate that SafePTR outperforms existing defense methods, offering a robust and efficient solution for safeguarding MLLMs against adversarial attacks. The findings of this research have significant implications for the safe deployment of MLLMs in real-world applications.