- The paper introduces a novel co-design that integrates MFA attention and hardware-aware MoE FFN to significantly lower LLM decoding costs.
- It demonstrates key results including a 74% throughput increase on Hopper GPUs and efficient scaling via a multi-stage pipeline.
- The work emphasizes system innovations like the AFD inference system and StepMesh library, enabling flexible, cost-effective heterogeneous deployments.
Step-3: Model-System Co-design for Cost-effective LLM Decoding
Introduction
Step-3 introduces a 321B-parameter vision-LLM (VLM) that advances the state-of-the-art in cost-effective LLM decoding through a rigorous model-system co-design. The work addresses the critical bottleneck of hardware inefficiency during the decoding phase, especially for long-context reasoning, by integrating a novel Multi-Matrix Factorization Attention (MFA) mechanism and a distributed inference system based on Attention-FFN Disaggregation (AFD). The result is a model that, despite activating more parameters per token than its contemporaries, achieves lower decoding costs and higher throughput, setting a new Pareto frontier for LLM inference.
Figure 1: The Pareto frontier of recent models regarding activated parameters and decoding costs. Step-3 achieves the highest attention effective rank among compared models.
Model Architecture and Innovations
Step-3 is built on a Transformer backbone with 61 layers and a hidden dimension of 7168. The key architectural innovations are:
- Multi-Matrix Factorization Attention (MFA): MFA applies low-rank matrix factorization to the Query-Key (QK) circuit, enabling efficient scaling of attention heads and dimensions while minimizing KV cache overhead. MFA achieves an attention effective rank of 16,384, matching or exceeding leading models.
- MoE FFN Design: The FFN layers employ a shared expert MoE configuration, inspired by DeepSeekMoE, with MoE applied to all but the first four and last layers. This yields 316B LLM parameters (321B including vision), with 38B activated per token.
- Full FP8 Quantization: Step-3 is quantized to FP8 throughout, enabling aggressive memory and compute efficiency without accuracy loss.
This architecture is specifically optimized for the decoding phase, leveraging the AFD system to decouple attention and FFN execution and maximize hardware utilization.
Attention-FFN Disaggregation (AFD) System
AFD is a distributed inference paradigm that separates attention and FFN layers into distinct subsystems, each mapped to hardware best suited for their computational and memory profiles. The design goals of AFD include:
- Independent Hardware Scaling: Attention and FFN can be deployed on heterogeneous hardware, optimizing for memory bandwidth (attention) and compute throughput (FFN).
- Pipeline Parallelism: A multi-stage pipeline (typically three stages: attention, FFN, communication) is orchestrated to overlap computation and communication, minimizing idle time and meeting strict SLA targets (e.g., 50ms per output token).
- Batch Size Optimization: By decoupling attention and FFN, AFD ensures that FFN always operates at an ideal batch size for high MFU, independent of attention-side constraints.
- Reduced Deployment Scale: Compared to EP-only architectures (e.g., DeepSeek-V3's 320-GPU deployment), Step-3 achieves similar or better throughput with as few as 32 GPUs.
Figure 2: Module disaggregation in AFD architecture. FFN can be deployed in TP-only, EP-only, or hybrid TP+EP configurations.
Figure 3: Communication topology and the multi-stages pipeline of the AFD architecture.
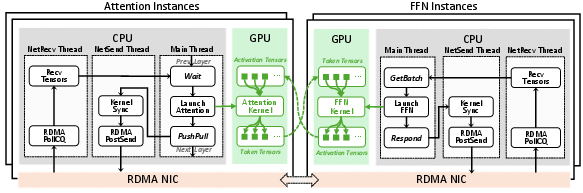
Figure 4: StepMesh communication workflow tailored for AFD.
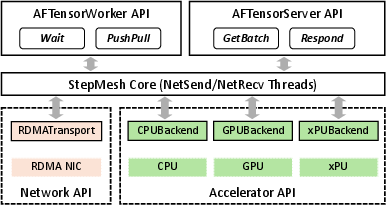
Figure 5: StepMesh framework for multiple accelerators. AFTensorWorker and AFTensorServer APIs are for attention and FFN instances, respectively.
Decoding Cost Analysis
A central contribution is the rigorous analysis of decoding costs, decomposed into attention and FFN components, and mapped to hardware characteristics (compute, memory bandwidth, and cost). Key findings include:
- Decoding Cost is Not Proportional to Parameter Count: Neither total nor activated parameter count reliably predicts decoding cost. For example, Qwen-3 MoE 235B, despite 65% fewer total parameters than DSv3, achieves only 10% lower decoding cost on its optimal hardware.
- Attention Design Dominates Decoding Cost: With AFD, attention cost (KV cache and computation) is the primary determinant of total decoding cost, especially as context length increases.
- Hardware-aligned Arithmetic Intensity: MFA's arithmetic intensity (128) is well-matched to the compute-memory-bandwidth ratios of a range of accelerators (H800, H20, A800, Ascend 910B), enabling high efficiency across hardware tiers.
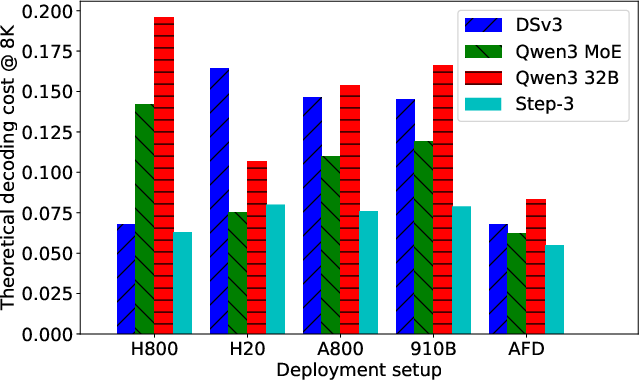
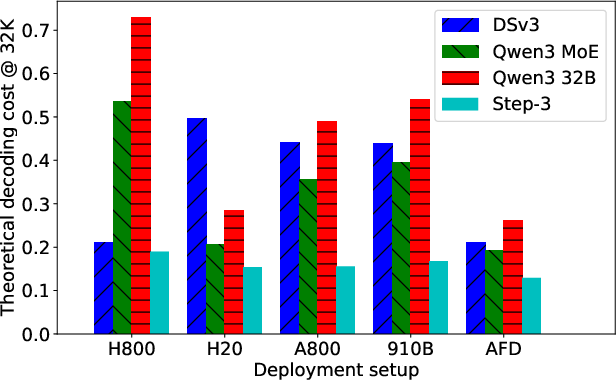
Figure 6: Decoding costs (per 1M tokens) of different models and inference configurations. Step-3 achieves the lowest cost despite the highest activated parameters.
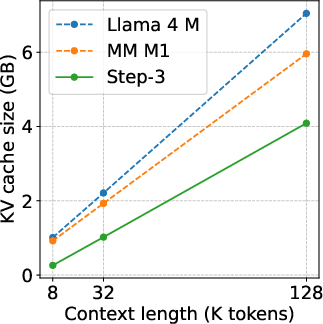
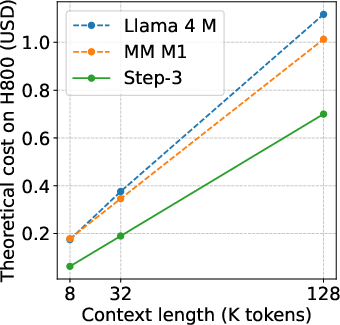
Figure 7: Total KV cache size and decoding cost comparison on H800 with hybrid linear attention models like MiniMax M1 and Llama 4 Maverick.
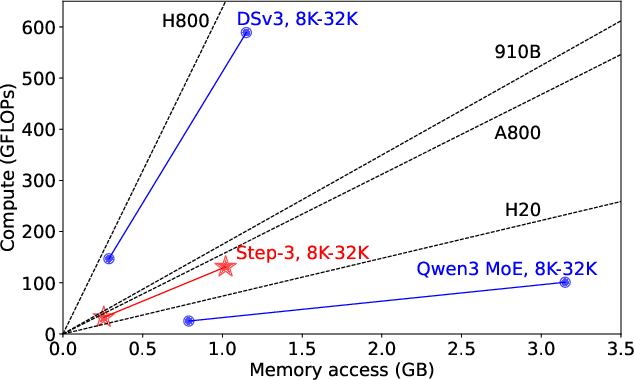
Figure 8: The compute and memory access of different attention designs during decoding, including DSv3's MLA, Qwen3 MoE's GQA, and Step-3's MFA. Hardware compute-memory-bandwidth ratios are also plotted.
Model-System Co-design: Trade-offs and Implications
Attention Arithmetic Intensity
Step-3's MFA achieves a balanced arithmetic intensity, avoiding the pitfalls of both compute-bound (e.g., DSv3's MLA) and memory-bound (e.g., Qwen3's GQA) designs. This balance allows Step-3 to maintain low decoding costs on both flagship and mid-tier hardware, and to benefit from further optimizations such as low-bit KV storage and multi-token prediction (MTP).
MoE Sparsity and Hardware Constraints
The analysis demonstrates that MoE sparsity must be tuned to hardware capabilities. Overly sparse MoE configurations, as in DSv3 and Kimi K2, lead to suboptimal MFU and network bottlenecks, especially on high-roofline hardware like H800. Step-3 selects a sparsity (≈0.08) that ensures high MFU and efficient network utilization, avoiding the need for large-scale EP deployments or restrictive MoE routing.
Hybrid and Linear Attention Models
Hybrid models (e.g., MiniMax M1, Llama 4 Maverick) that combine linear and full attention layers often fail to realize the theoretical KV cache savings due to a small number of full attention layers dominating memory access and computation. Step-3's design avoids such imbalances, ensuring that all layers contribute proportionally to efficiency.
Implementation and System Engineering
Step-3's inference system is implemented with a focus on minimal kernel overhead, efficient communication, and extensibility:
- StepMesh Communication Library: A custom GPUDirect RDMA-based library, StepMesh, is developed to meet the stringent latency and throughput requirements of AFD. It supports asynchronous, zero-SM-usage communication, NUMA-aware CPU binding, and direct GPU tensor transmission.
- Multi-stage Pipeline: The system orchestrates attention and FFN instances in a tightly coupled pipeline, with careful workload balancing to hide communication latency and maximize throughput.
- Heterogeneous Accelerator Support: StepMesh enables seamless integration of diverse hardware backends, facilitating cost-effective deployments that mix flagship and mid-tier accelerators.
Empirical Results
Step-3 demonstrates strong empirical performance:
Practical and Theoretical Implications
Step-3's co-design approach demonstrates that:
- Decoding efficiency is a function of model architecture, system design, and hardware alignment, not just parameter count.
- AFD enables flexible, hardware-agnostic deployments, reducing cost and improving reliability compared to monolithic or EP-only systems.
- MoE sparsity must be hardware-aware; over-sparsity leads to inefficiency and network bottlenecks.
- Balanced attention arithmetic intensity is critical for cross-hardware efficiency and for leveraging future optimizations (e.g., MTP, quantization).
The work also highlights the limitations of current interconnects in supporting highly sparse MoE FFNs and motivates future research into high-bandwidth domain designs.
Conclusion
Step-3 establishes a new standard for cost-effective LLM decoding through a principled model-system co-design. By integrating MFA attention, hardware-aware MoE sparsity, and the AFD inference system, Step-3 achieves superior decoding efficiency and throughput across hardware platforms. The analysis and empirical results underscore the necessity of aligning model architecture with system and hardware characteristics. Future directions include enabling MTP, exploring new attention variants, and collaborating with hardware vendors to support more aggressive sparsity in FFN layers.