- The paper introduces a scalable synthetic dataset that rigorously benchmarks multiple OCR engines on low-resourced languages, achieving notable metrics such as a 2.61% WER for Sinhala.
- The paper employs a novel synthetic corpus generation methodology with uniform character distribution and diverse font coverage to overcome data scarcity in Sinhala and Tamil OCR.
- The paper highlights challenges in word boundary detection and glyph ambiguity, emphasizing the need for improved postprocessing in real-world digital applications.
Zero-shot OCR for Low-Resourced South Asian Scripts: A Comparative Evaluation on Sinhala and Tamil
Background and Motivation
The paper "Zero-shot OCR Accuracy of Low-Resourced Languages: A Comparative Analysis on Sinhala and Tamil" (2507.18264) addresses persistent gaps in Optical Character Recognition (OCR) for low-resourced South Asian languages, focusing specifically on Sinhala and Tamil—both abugida-derived, rounded scripts with highly distinct graphemic inventories. Despite advances in OCR for high-resource Latin-based scripts, the literature demonstrates substantial challenges for LRLs: token complexity, insufficient annotated data, and visual ambiguity due to script morphology and font variation. These factors limit the applicability of established OCR methodologies and demand rigorous comparative analyses of both commercial and open-source OCR engines in truly zero-shot scenarios.
An illustrative comparison of Sinhala and Tamil rounded scripts underpins the motivation for improved OCR support and highlights glyph similarities that exacerbate recognition ambiguity.
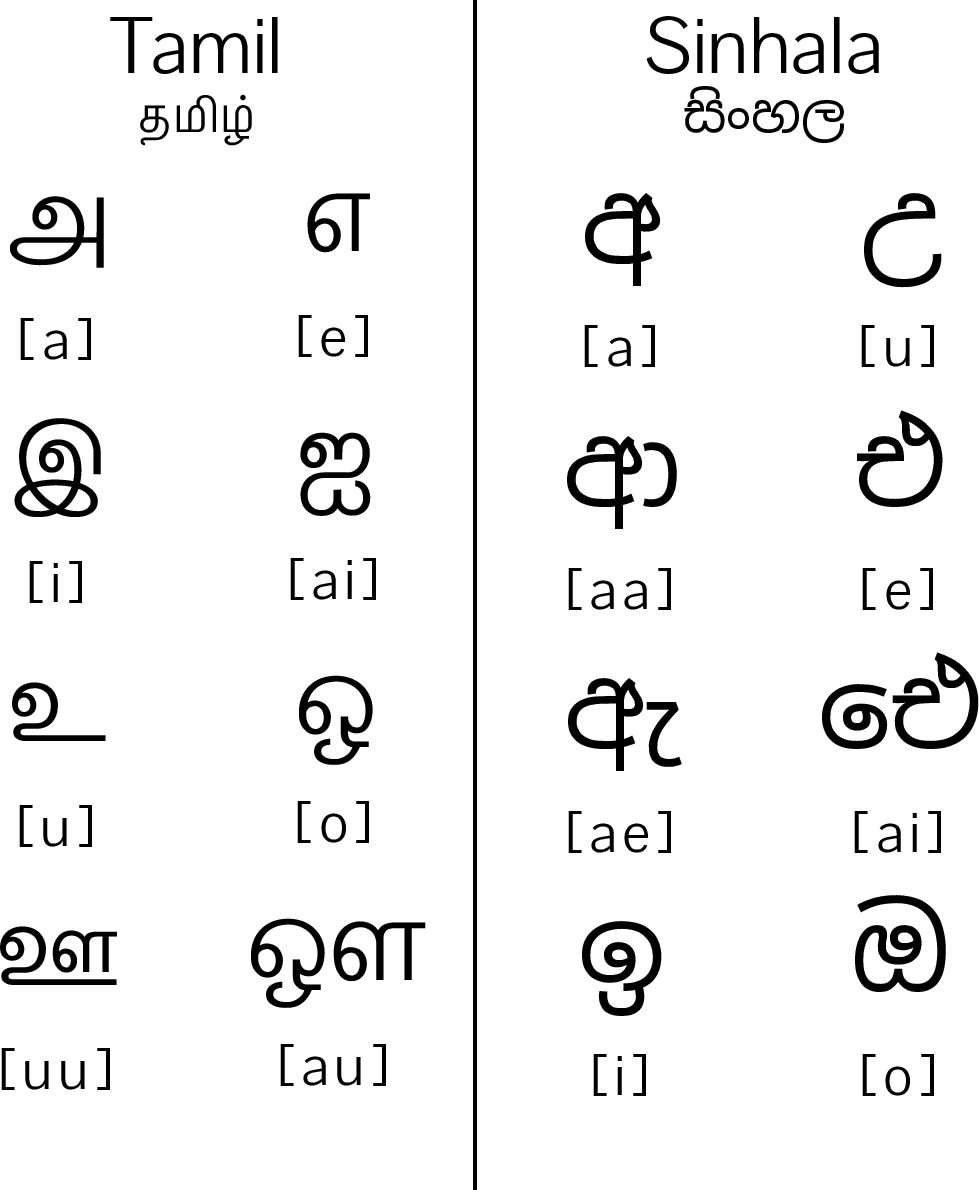
Figure 1: An example of the use of rounded script in Tamil and Sinhala languages.
Prior work on Sinhala OCR predominantly targets Tesseract-based architectures, often post-processing their outputs with linguistic heuristics to mitigate segmentation and classification errors. Multi-style printed text studies, such as those using hybrid ANN models with zone-based feature extraction, exhibit training/test accuracy disparities and remain dataset specific.
For Tamil, earlier Tesseract-centric systems adopted custom OCR alphabets and multiscale font training, achieving moderate accuracy. Recent developments, e.g., Nayana OCR, leverage VLMs with synthetic data augmentation and LoRA for rapid adaptation to Tamil. VLM-based methods exhibit significant improvements over both Tesseract and PaddleOCR in WER and sentence-level translation correlation metrics, underlining the importance of synthetic and cross-modal training sets.
Dataset Creation and Methodological Rigor
Given the absence of standardized, large-scale annotated datasets for these scripts, the study adopts synthetic corpus generation strategies for both languages. The Sinhala benchmark leverages an open repository with variation across five commonly used font families. In contrast, the Tamil synthetic dataset was constructed by extracting textual sequences from OPUS/OpenSubtitles, subjecting them to length filtration, random sampling to achieve parity with Sinhala data sizes, and rendering instances over six visually distinct Google Fonts. Importantly, the process ensures uniform character distribution, background consistency, and the absence of extraneous scripts for clean evaluation.
The dataset creation pipeline for Tamil is systematized and reproducible, a critical contribution for assessing generalization in zero-shot benchmarks.

Figure 2: Overview of the Tamil synthetic OCR dataset creation.
Empirical diversity within the Tamil testbed is evidenced by sentence rendering in various fonts:

Figure 3: Three examples of Tamil sentences from our dataset in the fonts Hind Madurai, Anek Tamil, and Kavinar, respectively.
OCR Systems Benchmarked
Six engines were benchmarked:
- Cloud Vision API (commercial, Google)
- Document AI (commercial, Google)
- Tesseract 5.5.0 (open-source, recurrent-LSTM)
- Surya (open-source, built on EfficientViT for detection, Donut/GQA/MoE for recognition)
- EasyOCR (open-source, ResNet+LSTM+CTC)
- Subasa OCR (web-based, fine-tuned Tesseract for Sinhala only)
Commercial engines required cloud-based integrations, while open-source engines were locally scriptable with standard Python wrappers (e.g., pytesseract, EasyOCR module).
Evaluation Protocol
Performance was assessed with five canonical and translation-aligned metrics:
This multifaceted evaluation captures both sub-lexical and lexical fidelity, translation proximity (BLEU, METEOR), and nearest-neighbor edit distances, illuminating error propagation in segmentation-sensitive scripts.
Quantitative Results and Analysis
Surya achieves best-in-class accuracy for Sinhala, with WER of 2.61%, METEOR of 0.9723, and ANLS at 0.9920—metric saturation indicative of robust segmentation and recognition on clean, synthetically diverse data. For Tamil, Document AI is dominant, recording the lowest CER at 0.78%—yet with comparatively higher WER (11.98%), signaling persistent difficulties in word boundary inference and agglutinative morphology resolution.
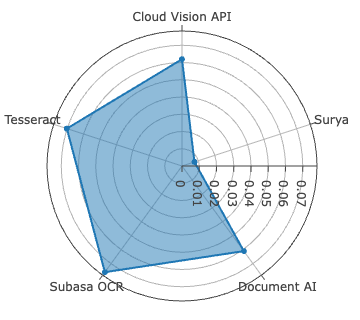
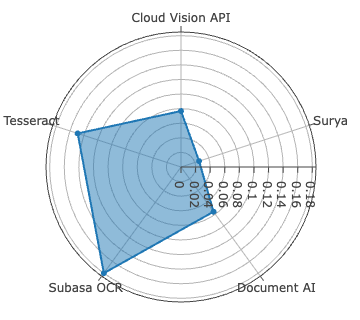
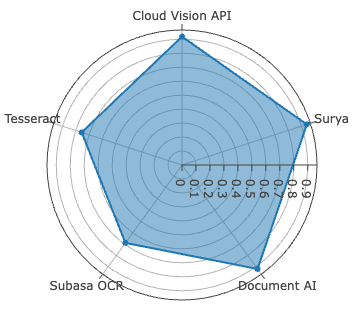

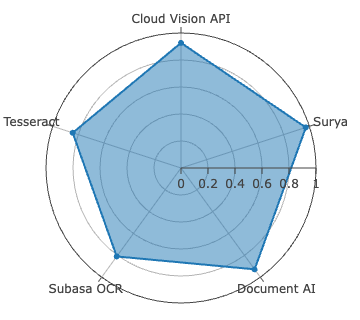
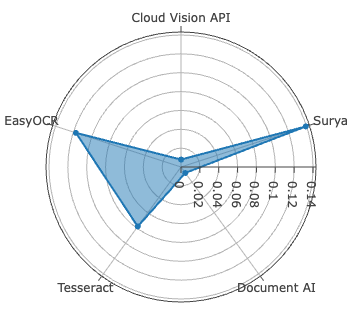
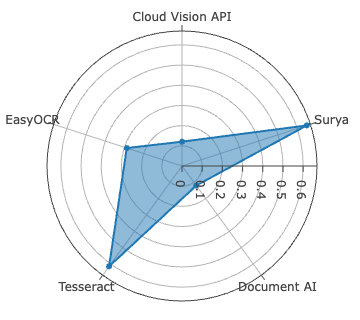
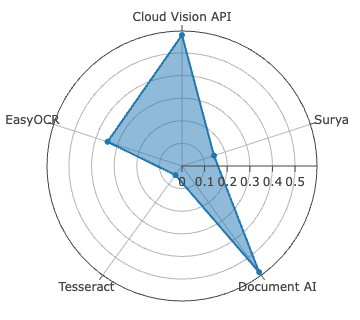
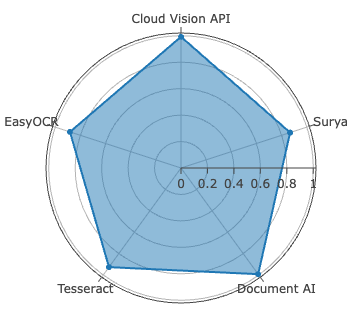
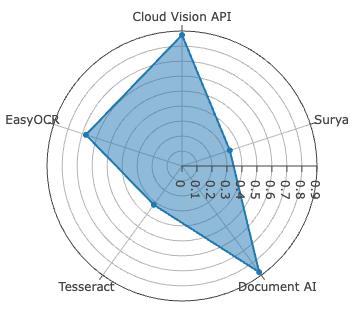
Figure 4: CER evaluation for Sinhala and Tamil across all systems—Surya leads on Sinhala, Document AI on Tamil, both with low CER outliers.
The Open Source Tesseract 5.5.0 notably surpasses the fine-tuned Subasa variant on Sinhala, contradicting prior claims of the latter’s superiority and illustrating rapid progress in general release LSTM architectures even for LRLs.
EasyOCR, lacking Sinhala support, shows competitive metrics among open-source alternatives for Tamil, but both commercial engines exceed it in all dimensions.
Despite high CER performance, all systems display diminished BLEU scores on Tamil relative to Sinhala, exposing compounding errors in word boundary detection, glyph clustering, and script-specific diacritic positioning. Character-level error analysis identifies non-linear correlations between raw error counts versus CER due to differences in alphabet size (Sinhala: 60, Tamil: 247), and character frequency distributions.
Practical Implications, Limitations, and Prospects
The findings have direct relevance for digitization workflows in environments where commercial licenses are cost-prohibitive or training data for fine-tuning is not available. Surya and Document AI set clear upper bounds for zero-shot performance on printed LRL scripts, though true complexity is understated by the use of synthetic, noiseless benchmarks.
The synthetic data approach, while necessary due to data scarcity, omits diverse real-world distortions (e.g., skew, blur, historic print flaws), so the transferability of the metrics to real document corpora is not guaranteed. As such, practical deployment for archival digitization or legal text recovery remains nontrivial.
For future research, expansion of the synthetic corpus with more ecological noise, challenging backgrounds, and additional font coverage is essential. Incorporating camera-captured datasets and multi-source domain adaptation would increase result generalizability. From a systems perspective, improved postprocessing for script-specific tokenization and integration of grapheme cluster models could alleviate word boundary error inflation.
The demonstrated superiority of recent open-source and commercial APIs over legacy fine-tuned systems suggests that rapid cross-lingual advances hinge on both continual architecture improvements and the systematic development of high-diversity LRL benchmarks.
Conclusion
This comparative study provides robust empirical evidence on the current state of zero-shot OCR for low-resourced South Asian scripts, highlighting that competitive accuracy—at least on synthetic, standardized content—is within reach of selected open-source and commercial engines without language-specific adaptation. The introduction of a scalable synthetic Tamil OCR testbed complements existing Sinhala resources and establishes a baseline for future LRL OCR research. Progress in font diversity handling and segmentation hints at convergence between commercial and open-source engines, but real-world deployment will require further advances in noise robustness and script morphomics.
Ongoing development of realistic annotated benchmarks and targeted model improvements remains imperative for closing the accuracy gap with Latin-based scripts and fulfilling the digitization needs of linguistically diverse populations.