- The paper introduces a nonlinear Targeted Causal Reduction (nTCR) method that extends traditional causal models to explain reinforcement learning policies.
- It employs a normality regularization and an interpretable function class to ensure interventional consistency and temporal feature decomposition.
- Experimental validations on synthetic models, the Pendulum environment, and robot table tennis demonstrate nTCR’s effectiveness in uncovering policy biases and reward variations.
Learning Nonlinear Causal Reductions for RL Policy Explanation
The paper "Learning Nonlinear Causal Reductions to Explain Reinforcement Learning Policies" (2507.14901) addresses the challenge of understanding the behavior of trained RL policies by introducing a causal perspective. It formulates the problem as a Causal Model Reduction (CMR), where the system of actions, environment variables, and rewards is treated as a complex low-level causal model. The approach involves perturbing policy actions during execution to learn a simplified high-level causal model that explains the relationships between actions and cumulative rewards.
Background and Methodology
The paper builds upon the foundations of Structural Causal Models (SCMs) and Causal Model Reductions (CMRs). SCMs provide a mathematical framework for representing cause-effect relationships in complex systems, while CMRs offer dimensionality reduction techniques that map detailed low-level causal models to approximate high-level descriptions. The key criterion for a good reduction is interventional consistency, ensuring that the high-level model responds to interventions in ways that correspond to the original model's behavior.
The authors extend the Targeted Causal Reduction (TCR) framework (2507.14901) to nonlinear settings, introducing nonlinear TCR (nTCR). TCR focuses on explaining a specific target variable of interest by creating an interpretable formulation where changes in the target variable are explained through a high-level causal mechanism. The nonlinear extension allows the capture of complex relationships that cannot be adequately represented by linear maps.
(Figure 1)
Figure 1: From Reinforcement Learning Policies to Causal Explanations.
To formulate the problem as a TCR problem, the low-level endogenous variables are defined consisting of states and actions Xπ(1) and rewards Xπ(0), where the interventions are Iπ(1), and the target variable is the cumulative reward Y.
The nTCR approach incorporates a normality regularization term to encourage the high-level cause distribution to be Gaussian, enhancing interpretability and theoretical validity. The total optimization objective for nTCR then becomes $\mathcal{L}_{\text{total} = \mathcal{L}_{\text{cons} + \eta_{\text{norm} \mathcal{L}_{\text{norm}$.
Theoretical Guarantees
The paper provides theoretical guarantees of solution uniqueness for a broad class of nonlinear models, ensuring unambiguous explanations despite the identifiability challenges of nonlinear systems. It demonstrates both the existence and uniqueness of reductions with exact interventional consistency for a broad class of nonlinear causal models.
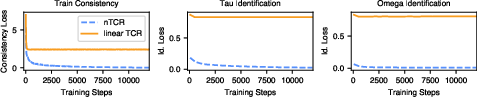
Figure 2: Identification of Ground-Truth Solutions for Synthetic Low-Level Models. Consistency loss (left) and the identification losses measuring agreement with the ground-truth solutions (definition in \Cref{app:synthetic_experiments}) for the τ- and ω-functions (middle and right) over the reduction training run.
Interpretable Function Class
To maintain interpretability in the nonlinear setting, the paper introduces an interpretable nonlinear function class that leverages the temporal structure of RL episodes. This function class decomposes the state space into individual features represented as time series, allowing for the identification of which features, at which time steps, contribute most significantly to the high-level causal explanation.
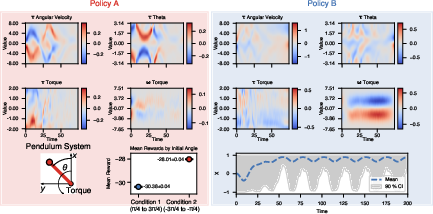
Figure 3: % Pendulum task. The top two rows show the learned nTCR tau- and omega-maps for two policies A and B. The heatmaps show the learned reductions tau_1j(xj) and omega_1j(ij), where j indexes the state/action variables (angular velocity, theta, and torque). Note that since we only intervene on the torque, this is the only variable for which there is a nonzero omega-map. The bottom left plot shows the pendulum system setting. The middle plot on the bottom row shows the mean reward for Policy A for pendulums starting in the left quadrant (Condition 1) and those starting in the right quadrant (Condition 2). The standard error of the mean is shown (the error bars are smaller than the data point in the plot). The bottom right plot shows the mean x-position of the pendulum for episodes under Policy B and the 90\% confidence interval.
Experimental Validation
The authors validate their approach through experiments on synthetic causal models and practical RL tasks. Experiments on synthetic data demonstrate that nTCR can find unique solutions that perfectly minimize the causal consistency loss. In the Pendulum environment, nTCR identifies trajectory groups with significant reward variations and uncovers biases in trained policies. Additionally, the approach is applied to a robot table tennis simulation, revealing key factors influencing policy performance.
Conclusion
The paper presents a valuable contribution to the field of explainable reinforcement learning by introducing a nonlinear extension of the Targeted Causal Reduction framework. The nTCR approach provides a principled and interpretable method for understanding the behavior of RL policies, with theoretical guarantees and experimental validation. The development of nonlinear TCR marks a significant step forward in policy-level explanations, offering insights into complex behavioral patterns that remain hidden to linear approaches.