On the importance of tail assumptions in climate extreme event attribution
Abstract: Extreme weather events are becoming more frequent and intense, posing serious threats to human life, biodiversity, and ecosystems. A key objective of extreme event attribution (EEA) is to assess whether and to what extent anthropogenic climate change influences such events. Central to EEA is the accurate statistical characterization of atmospheric extremes, which are inherently multivariate or spatial due to their measurement over high-dimensional grids. Within the counterfactual causal inference framework of Pearl, we evaluate how tail assumptions affect attribution conclusions by comparing three multivariate modeling approaches for estimating causation metrics. These include: (i) the multivariate generalized Pareto distribution, which imposes an invariant tail dependence structure; (ii) the factor copula model of Castro-Camilo and Huser (2020), which offers flexible subasymptotic behavior; and (iii) the model of Huser and Wadsworth (2019), which smoothly transitions between different forms of extremal dependence. We assess the implications of these modeling choices in both simulated scenarios (under varying forms of model misspecification) and real data applications, using weekly winter maxima over Europe from the Météo-France CNRM model and daily precipitation from the ACCESS-CM2 model over the U.S. Our findings highlight that tail assumptions critically shape causality metrics in EEA. Misspecification of the extremal dependence structure can lead to substantially different and potentially misleading attribution conclusions, underscoring the need for careful model selection and evaluation when quantifying the influence of climate change on extreme events.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved issues that the paper leaves open, aimed at guiding future research.
- Causal identifiability under spatial dependence: The paper acknowledges SUTVA violations (interference and heterogeneity) but does not provide a formal identification strategy under spatial interference. Develop and evaluate causal estimators that explicitly model interference (e.g., spatial potential outcomes, network/spatial causal models) and assess bias in AR/PN estimates when SUTVA is violated.
- Unconfoundedness and covariate control: No covariates are used to condition on confounding climate drivers (e.g., ENSO, NAO, aerosol loadings). Establish covariate-adjusted attribution frameworks and quantify how inclusion of large-scale modes affects estimates of p0, p1, AR, PN.
- Positivity in climate attribution: Positivity is assumed but not operationalized in the climate context where only one “treated” world exists. Formalize what positivity means for climate simulations (e.g., counterfactual ensembles) and devise diagnostics to check it.
- Double-model uncertainty propagation: Probabilities p0 and p1 are derived from statistical models fitted to climate model outputs, but uncertainty from both layers (climate model structural/ensemble uncertainty and statistical model parameter/structural uncertainty) is not jointly propagated. Build hierarchical uncertainty quantification (e.g., Bayesian multi-model ensembles, nested bootstrap) to deliver intervals for AR/PN that reflect both sources.
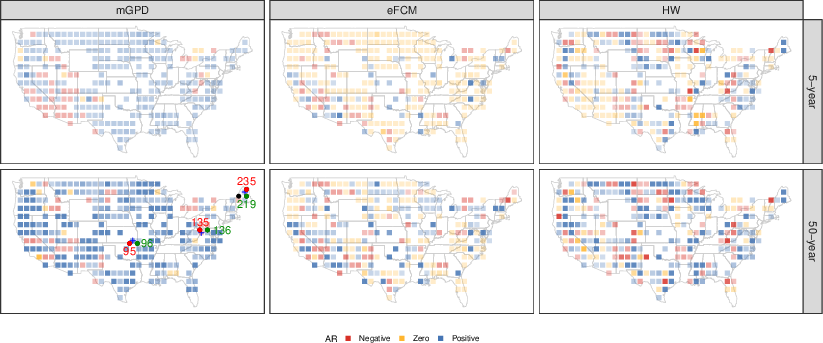
- Sensitivity to thresholding choices: The choice of u (90th percentile) and v (5- and 50-year return levels) is fixed, with no sensitivity analysis. Quantify how AR/PN vary with threshold selection, including automated threshold diagnostics (stability plots, cross-validation) and robust methods for nonstationary thresholds.
- Weight-vector optimization and overfitting: The data-driven optimization of weights w to maximize PN or AR lacks regularization or out-of-sample validation. Develop penalized or cross-validated procedures to prevent overfitting, report the variability of w*, and assess the impact of weight selection uncertainty on AR/PN.
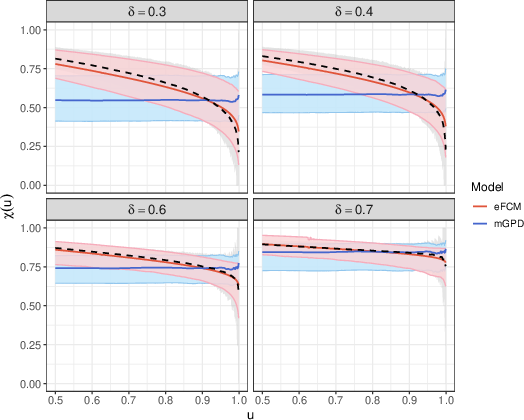
- High-dimensional scalability and dependence beyond pairs: Dependence assessment relies on bivariate χ(u). Investigate higher-order extremal dependence (e.g., concurrent exceedances across many sites, extremal variograms) and computational scalability for d≫2 (typical grids) with accurate uncertainty quantification.
- Temporal dependence and declustering: Applications use 7-day maxima but do not address residual temporal dependence, storm persistence, or declustering rigorously. Evaluate attribution metrics under explicit spatiotemporal dependence models and test robustness to different temporal aggregation/declustering schemes.
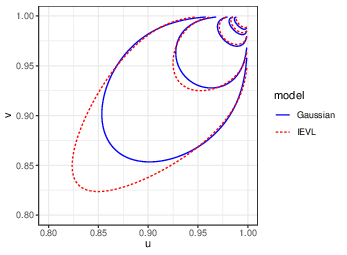
- Model selection criteria targeted to tails: Model choice is based on qualitative χ(u) comparisons and qqplots; no quantitatively justified, tail-focused selection criteria are provided. Develop tail-weighted information criteria or cross-validated scoring rules (e.g., weighted CRPS in the tail) for selecting among mGPD, eFCM, HW, and alternatives.
- eFCM asymptotic behavior and applicability: eFCM is asymptotically dependent but used in regimes where the true process may be asymptotically independent (HW with δ<0.5). Clarify theoretical conditions under which eFCM approximates finite-threshold behavior well in asymptotic independence, and quantify errors as u→1.
- HW model inference in multivariate (non-spatial) settings: The HW model is adapted from spatial to multivariate by imposing covariance structures, but its inference and goodness-of-fit in general multivariate (non-embedded) contexts are not validated. Provide estimation diagnostics, computational strategies, and theory for multivariate HW without spatial embedding.
- mGPD constraints and generator choice: The mGPD implementation assumes a common shape parameter γ and a specific generator (independent reverse exponential), which may be restrictive in heterogeneous regions. Explore heterogeneous γ across sites and alternative generators; quantify impacts on the extremal dependence and AR/PN.
- Multi-factor dependence structures: The eFCM’s single common factor may over-synchronize extremes in larger domains. Investigate multi-factor copula constructions (e.g., multiple latent factors, spatially varying factors) and test whether they reduce bias in AR/PN for heterogeneous regions.
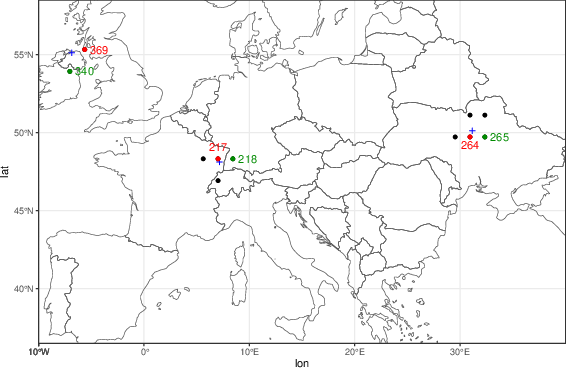
- Clustering and homogeneity testing: Cluster size (D0) and the homogeneity test pipeline are critical, yet sensitivity to D0 and cluster boundaries is not assessed. Systematically evaluate how clustering choices affect tail estimates and AR/PN, and develop adaptive clustering with uncertainty quantification.
- Ensemble design and internal variability: The paper does not specify ensemble sizes or initial-condition ensembles for factual/counterfactual worlds. Quantify the effect of internal variability and limited ensemble sizes on p0/p1 estimation and attribution metrics, and design experiments to ensure adequate sampling of rare extremes.
- Monte Carlo efficiency for rare events: Estimation of very small tail probabilities via crude Monte Carlo is variance-inefficient. Implement importance sampling or conditional simulation tailored to the fitted tail model to reduce variance and improve accuracy for extreme quantiles.
- Model misspecification beyond 2-D simulations: Simulations focus on d=2, but real applications are high-dimensional. Extend misspecification studies to higher dimensions, including realistic spatial layouts, to understand bias/variance trade-offs and computational load at scale.
- Tail-focused calibration with observations: Applications rely solely on climate model outputs; observational validation and bias correction in tails are not addressed. Calibrate tail models to observations (e.g., quantile mapping for extremes, conditional extremes calibration) and quantify how model biases alter AR/PN.
- Attribution metrics breadth: The paper centers on AR and PN (with PN results deferred to Supplementary Material) and largely omits PS and PNS in applications. Provide full-spectrum causal metrics with uncertainty and discuss interpretation differences across metrics for policy-relevant statements.
- Physical interpretability of weights and projections: Linear projections w⊤X maximize attribution metrics but their physical meaning (hydrological relevance, catchment-scale aggregation) is not examined. Integrate physical constraints or expert-informed priors on w to enhance interpretability and robustness.
- Return level estimation methodology: The procedure for computing 5- and 50-year return levels under the counterfactual is not detailed (e.g., choice of marginal tail model, stationarity assumptions). Specify and assess the return-level estimation method, including uncertainty and sensitivity to nonstationarity.
- Cross-model (CMIP) structural uncertainty: Only two climate models (CNRM, ACCESS-CM2) are analyzed; structural uncertainty across models is not explored. Extend analysis to multi-model ensembles and evaluate how tail dependence assumptions interact with inter-model spread in attribution.
- Alternative extreme-value frameworks: Conditional extremes (Heffernan–Tawn), vine copulas, and max-stable/inverted max-stable hybrids are not considered. Benchmark these against mGPD/eFCM/HW for subasymptotic and asymptotic regimes and quantify differences in AR/PN.
- Communication and decision relevance: The paper shows that tail assumptions critically affect causation metrics, but guidance for practitioners on model choice and diagnostic workflows is limited. Develop actionable protocols (diagnostic checklists, sensitivity analyses, decision thresholds) for attribution studies to avoid misleading conclusions.
Collections
Sign up for free to add this paper to one or more collections.