- The paper introduces the healing method as a primary defense against adversarial unlearning that maintains model performance.
- It leverages a reserve of similar training elements to replace those maliciously removed, ensuring minimal performance deterioration.
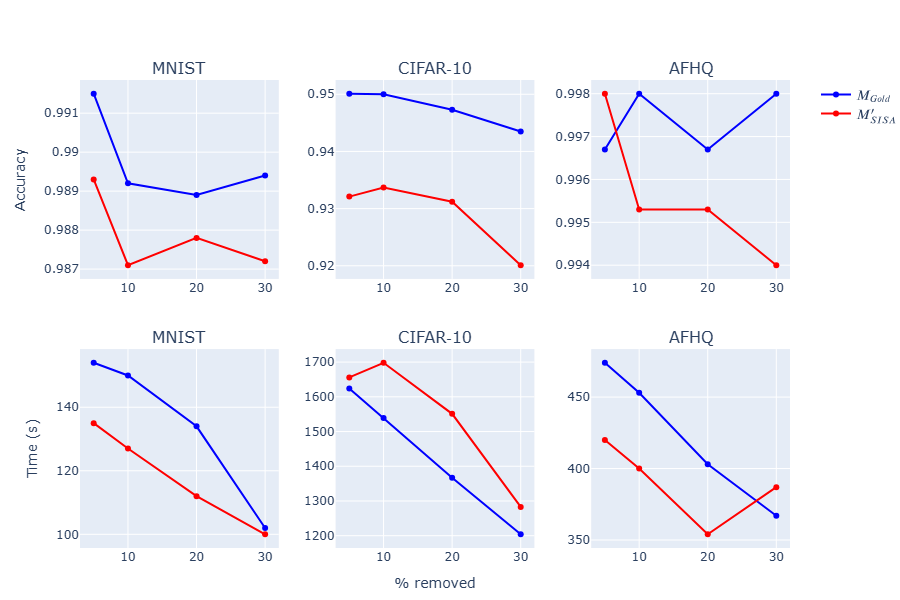
- Experimental results on MNIST, CIFAR-10, and AFHQ demonstrate the healing approach's superiority over traditional defense strategies.
Protecting Models Against Adversarial Unlearning
Introduction
The paper "How to Protect Models against Adversarial Unlearning?" (2507.10886) investigates the critical issue of adversarial unlearning within machine learning models. Adversarial unlearning occurs when a malicious entity sends unlearn requests to a model with the aim of degrading its performance. This paper presents an innovative method for safeguarding model performance against such adversarial threats. It underscores the necessity to understand the impact of these attacks and proposes a strategy termed "healing" that mitigates negative effects from both spontaneous and adversarial unlearning requests.
Adversarial Unlearning: Challenges and Risks
Unlearning involves the removal of specific knowledge or training examples from a machine learning model. This is necessary in scenarios such as data privacy compliance (e.g., GDPR) or removing incorrect or harmful information from a model’s training data. However, this paper highlights that unlearning can be leveraged maliciously. If executed without safeguards, adversarial entities can issue requests to unlearn strategic pieces of data, thereby maximally degrading the model's performance.
The paper identifies critical factors that influence the adversary's capabilities, including the type of model architecture, data selection for unlearning, and the adversary's knowledge about the model and its training data. Therefore, models must be robust against such potential exploits to protect their efficacy.
Proposed Solution: The Healing Method
The primary contribution of this paper is the healing method, designed to counteract the adverse effects of unlearning. Healing involves partially replacing unlearned elements with similar ones to stabilize the model while preserving desired model attributes. The strategy relies on maintaining a reserve of "spare elements" which can substitute those removed during the unlearning process. This method emphasizes the semblance between the removed and replacement elements and involves constructing a well-defined reserve set to mitigate performance loss.
The approach deviates from conventional corrective strategies such as fine-tuning or knowledge distillation, focusing instead on maintaining model performance through strategic element replacement during the unlearning process.
Experimental Validation
The paper's experimental framework assesses multiple backbone models and unlearning strategies on datasets such as MNIST, CIFAR-10, and AFHQ. The effectiveness of the healing method is validated against several unlearning techniques, including Naive, SISA, Fisher Unlearning, and Influence Unlearning. These experiments demonstrate that:
Implications and Future Directions
The findings in this paper highlight the inherent risks in the unlearning processes that can be exploited. With the increasing legal and ethical demands for unlearning capabilities in AI models, devising robust mechanisms to prevent adversarial tampering becomes imperative.
Future research avenues include refining the similarity metrics for selecting replacement elements, extending healing techniques to generative and reinforcement learning models, and optimizing resource allocation for maintaining a minimal reserve element set for effective healing. Understanding the interactions between benign and malicious unlearn requests could offer deeper insights into fortifying model integrity.
In conclusion, this paper presents a comprehensive exploration into the vulnerabilities introduced by adversarial unlearning and delivers a pragmatic solution to protect against them. The healing approach offers a promising avenue for maintaining model performance and reliability in the face of potential adversarial threats.