- The paper introduces SFedKD, a novel sequential federated learning approach that mitigates catastrophic forgetting by leveraging discrepancy-aware multi-teacher knowledge distillation.
- It employs a teacher selection mechanism based on class distribution discrepancies, extending decoupled knowledge distillation to a multi-teacher framework.
- Experiments on diverse datasets demonstrate that SFedKD outperforms current FL methods in accuracy and stability under high data heterogeneity.
SFedKD: Sequential Federated Learning with Discrepancy-Aware Multi-Teacher Knowledge Distillation
Introduction
This paper addresses the challenge of catastrophic forgetting in Sequential Federated Learning (SFL) due to data heterogeneity across clients. Traditional Federated Learning (FL) concatenates client models to create a global model, but in SFL, models train sequentially across clients, which helps with convergence but often leads to forgetting previous client-specific knowledge. SFedKD introduces a methodology to counteract this forgetting by employing discrepancy-aware multi-teacher knowledge distillation. This approach involves selecting multiple teacher models from prior rounds that cover the knowledge space, applying distinct weights for each model's contributions based on local class distribution discrepancies, and extending single-teacher Decoupled Knowledge Distillation (DKD) approaches to the multi-teacher setting. Additionally, the paper proposes a complementary-based teacher selection mechanism to optimize teacher selection for comprehensive coverage and efficiency.
Problem and Framework
The proposed framework operates over several rounds. In each round, a sequence of clients is sampled, and the server applies a selection mechanism to determine which teacher models from the previous round will guide the current training process. The teacher models are chosen based on how well they complement each other to provide comprehensive knowledge across classes. This framework trains models sequentially and utilizes a discrepancy-aware weighting scheme for knowledge distillation. The overarching goal is to balance new learning and retention of prior knowledge, reducing catastrophic forgetting.
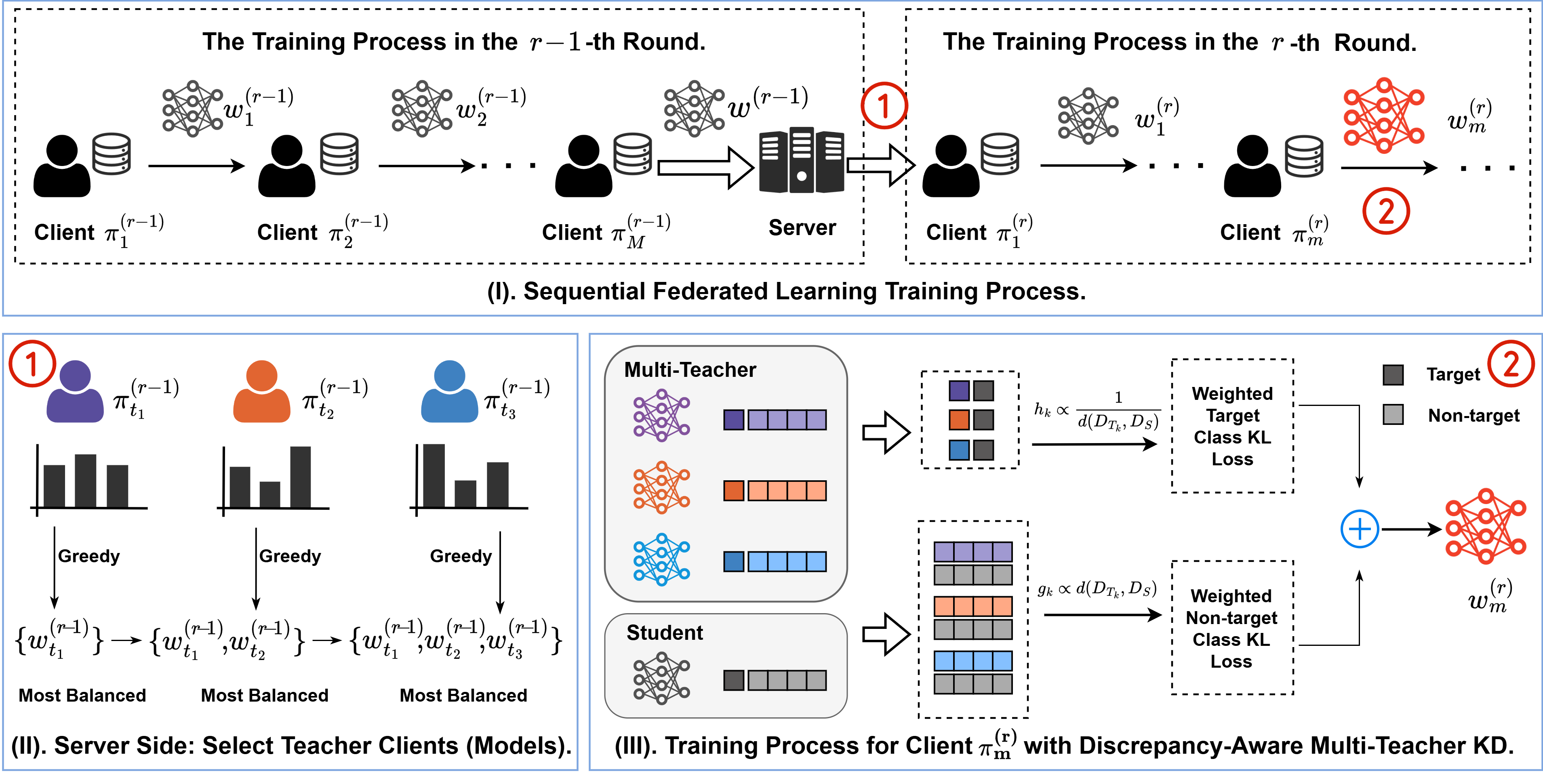
Figure 1: The overview of our proposed SFedKD, illustrating the sequential training and teacher selection process with discrepancy-aware multi-teacher knowledge distillation.
Discrepancy-Aware Multi-Teacher KD
The paper extends DKD to accommodate multiple teacher models. SFedKD's novelty lies in the assignment of distinct weights to teachers' target and non-target class knowledge, allowing precise alignment of knowledge distillation to overcome catastrophic forgetting. Teacher model contributions during distillation are weighted based on the discrepancy between their local class distributions and the current client’s dataset distribution. This fine-grained approach ensures personalized knowledge assimilation while keeping the model consistently effective across diverse classes.
Teacher Selection Mechanism
The selection mechanism identifies redundant teachers—those whose knowledge overlaps excessively. By maximizing knowledge space coverage—the complementarity of teacher selections—SFedKD ensures diverse, yet relevant, distillation guidance. This approach is framed as a variant of the maximum coverage problem, solved via a greedy algorithm. The selected teachers provide diverse class coverage and avoid diluting distilled information, leading to efficient training with reduced computational overhead.
Experimental Findings
Experiments were conducted across multiple datasets (Fashion-MNIST, CIFAR-10, CINIC-10, CIFAR-100, and HAM10000). SFedKD consistently outperformed state-of-the-art FL methodologies. The discrepancy-aware multi-teacher KD effectively mitigated catastrophic forgetting, showing superior accuracy, especially under conditions with high data heterogeneity.
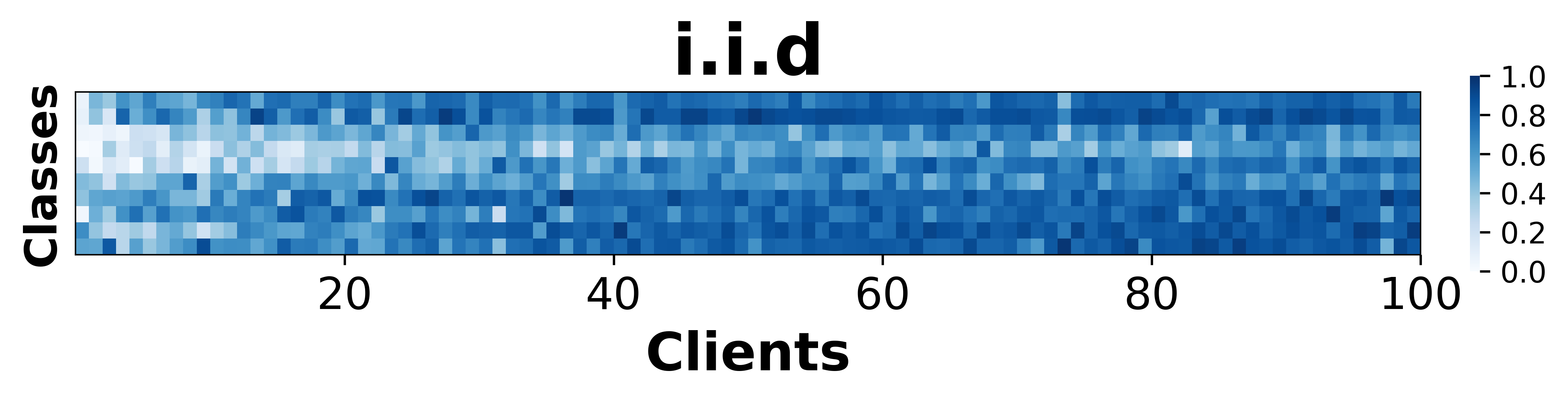
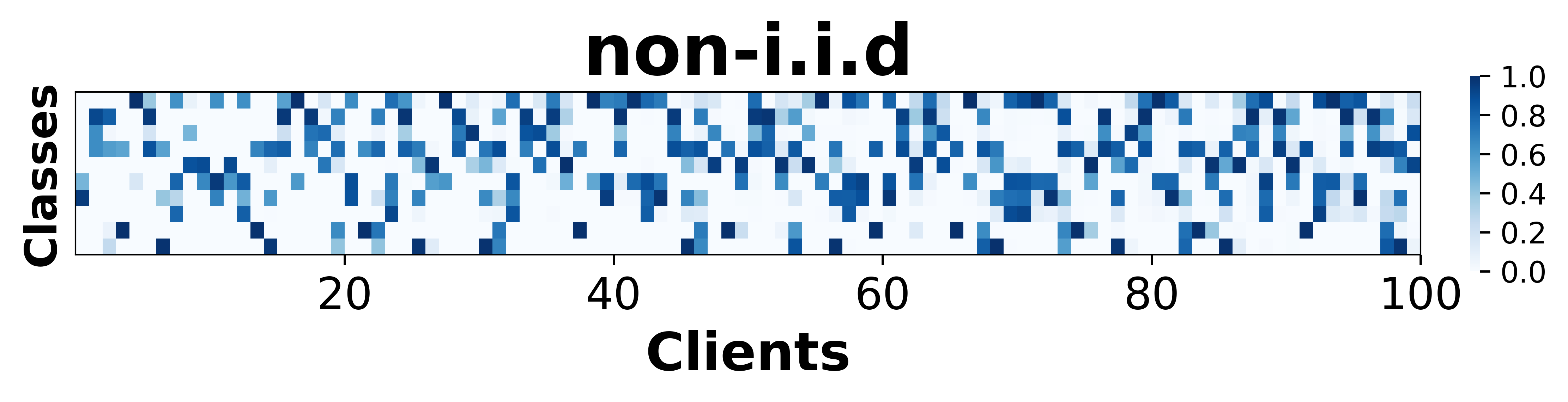
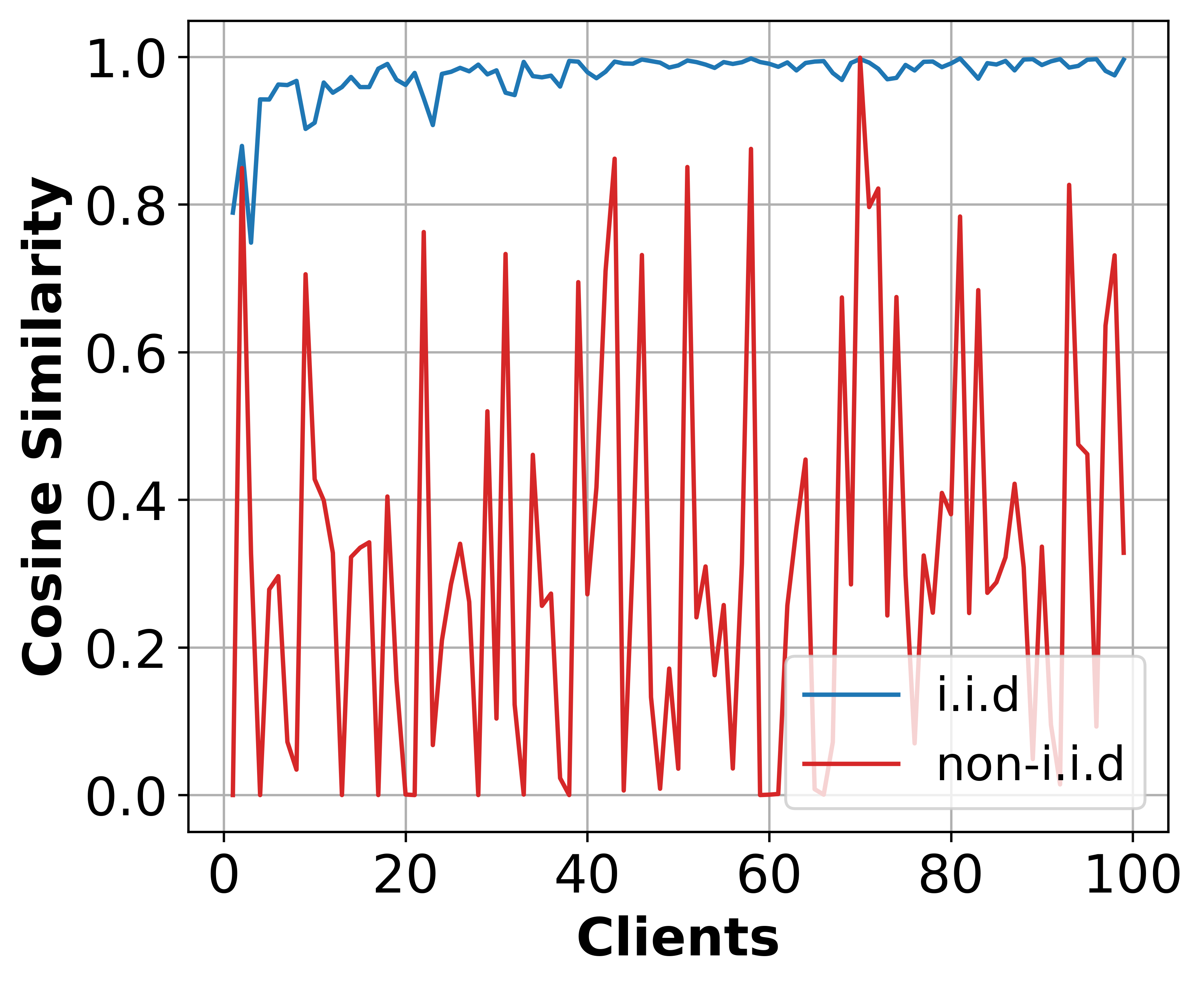
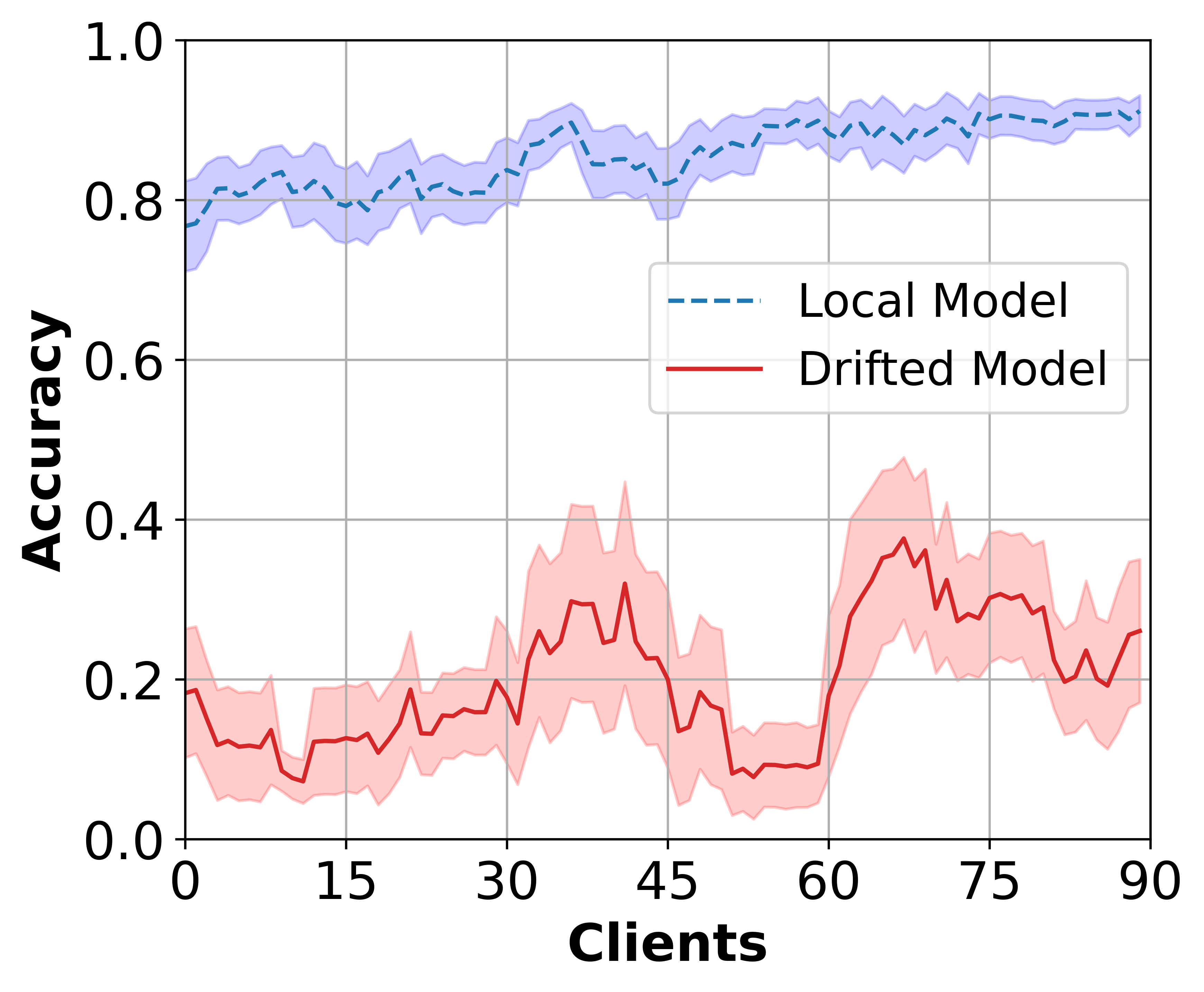
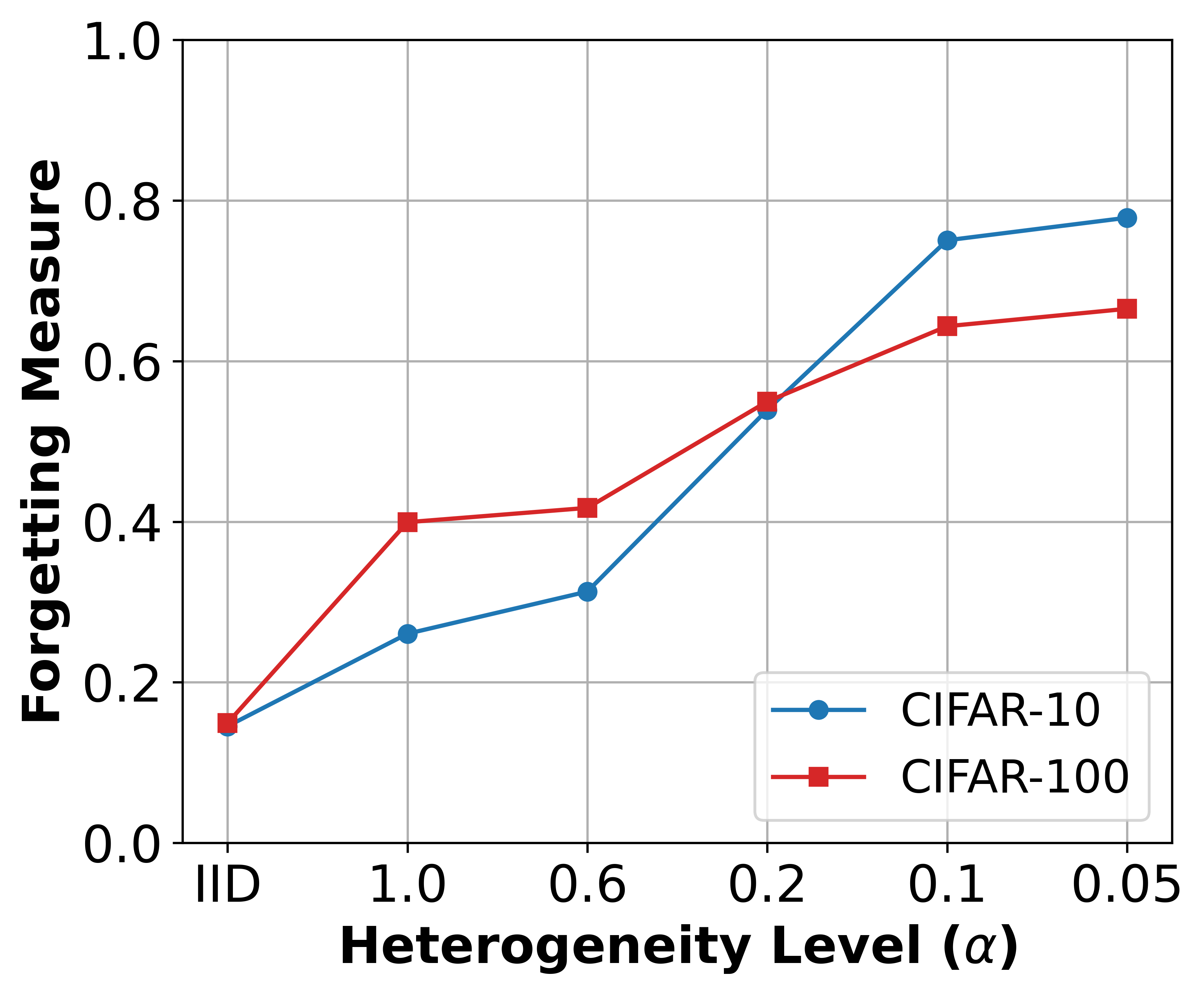
Figure 2: Class-wise accuracy demonstrating SFedKD's efficacy in maintaining consistent performance across diverse classes.
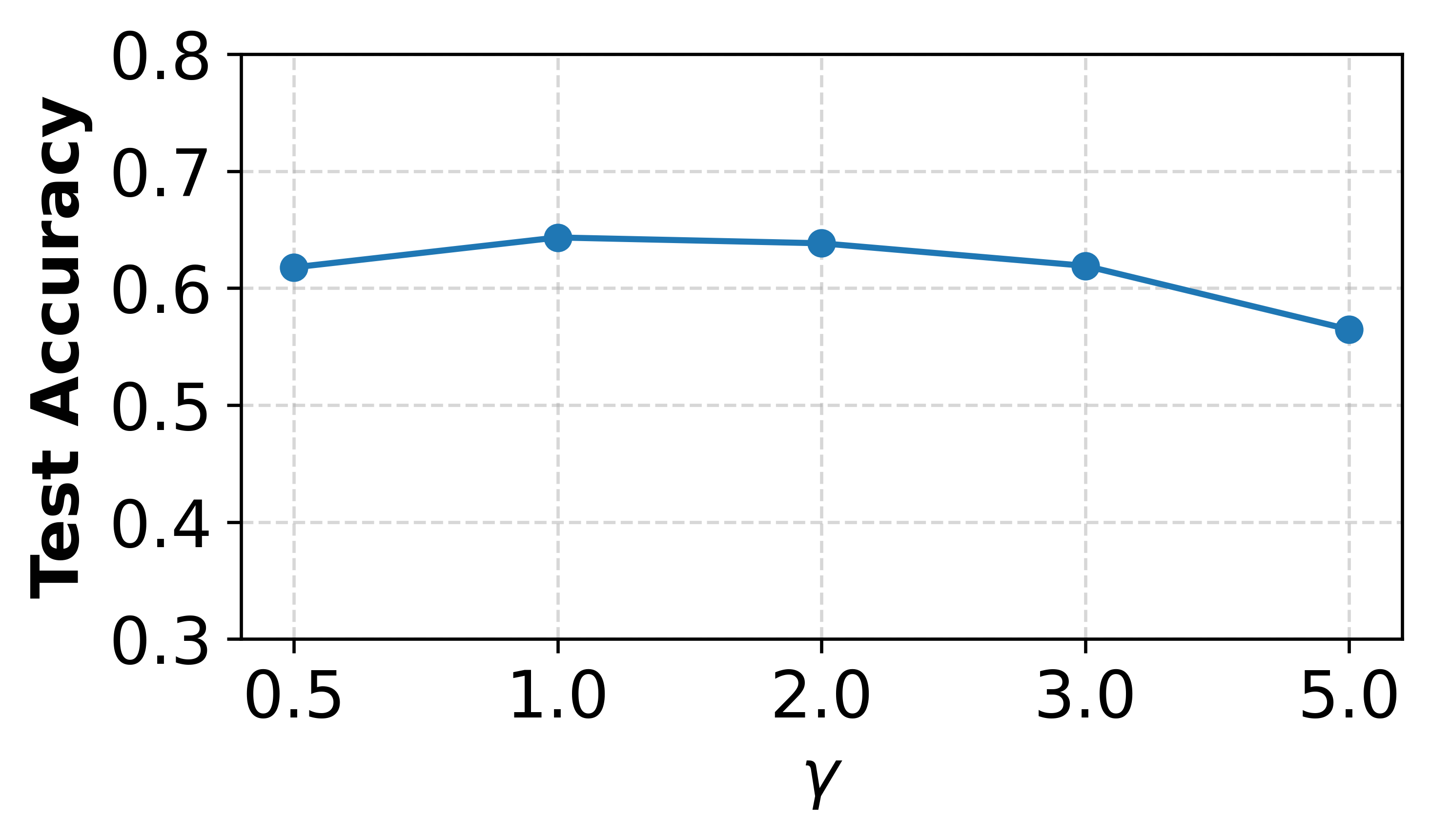
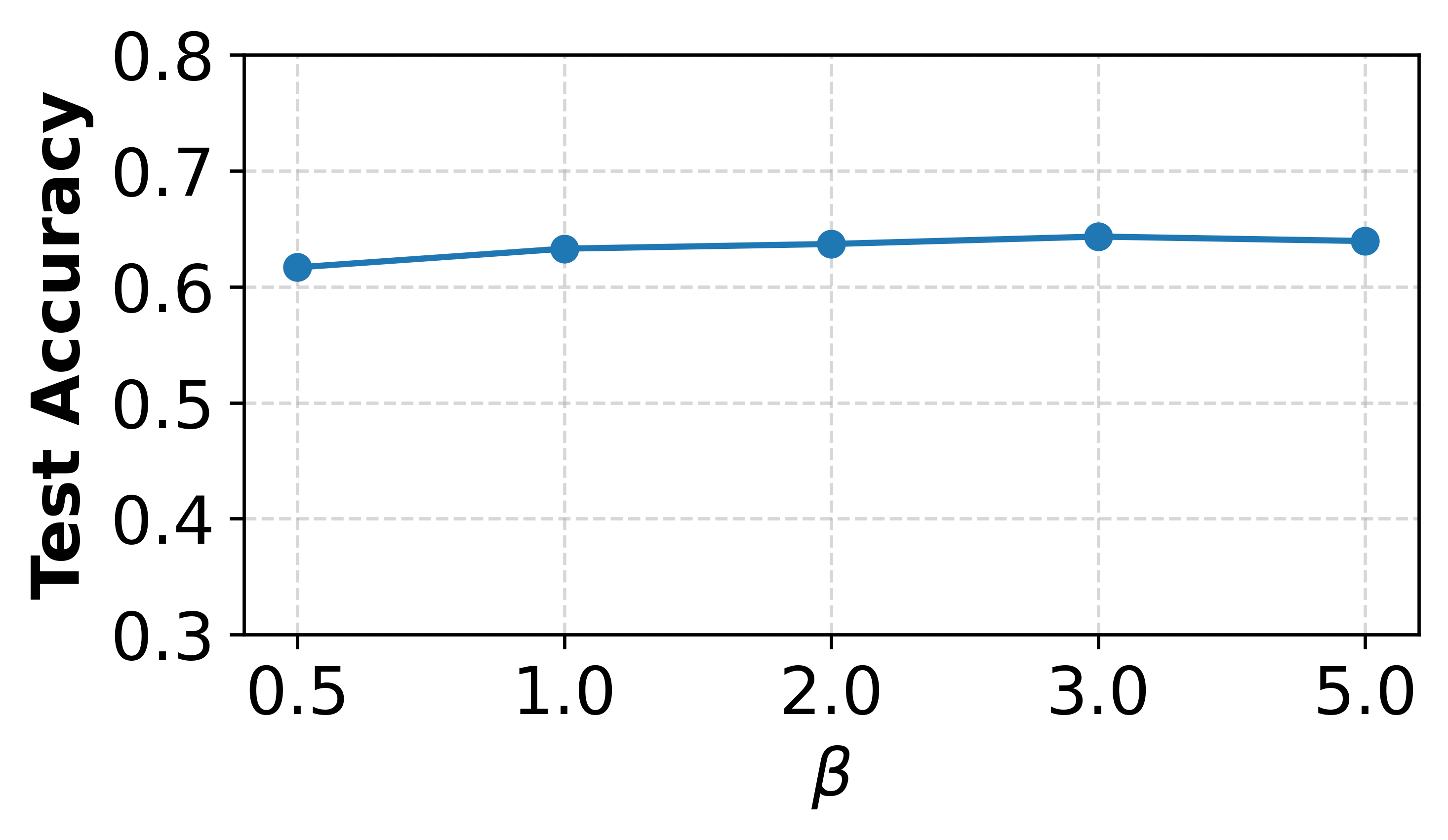
Figure 3: Impact of hyperparameter γ exploring SFedKD's sensitivity to weighting balance.
Conclusion
SFedKD presents a robust approach to mitigating catastrophic forgetting in sequential federated learning through innovative use of multi-teacher knowledge distillation. By leveraging class distribution discrepancies for fine-grained teacher guidance, and optimizing teacher selection for knowledge diversity, SFedKD significantly enhances model performance stability and efficacy across heterogeneous client datasets. The promising results indicate its potential for more resilient FL systems that maintain past knowledge while adapting to new client environments.
References
- McMahan, B., et al. Communication-efficient learning of deep networks from decentralized data.
- Zhao, B., et al. Decoupled knowledge distillation.
- Kwon, K., et al. Adaptive knowledge distillation based on entropy.
- Li, T., et al. Federated optimization in heterogeneous networks.