- The paper introduces an adaptive mutual distillation framework where a large local teacher model guides a smaller shared student model to reduce communication costs.
- It leverages dynamic gradient approximation using SVD to compress exchanged gradients, ensuring robust model convergence with minimal data transfer.
- Experimental results on benchmark datasets show that FedKD scales effectively with an increasing number of clients while maintaining competitive prediction accuracy.
FedKD: Communication Efficient Federated Learning via Knowledge Distillation
Introduction
Federated learning (FL) is a pivotal technique for training models over decentralized data, ensuring user privacy by keeping data localized. However, traditional FL methods struggle with high communication costs, especially when transferring large model updates across clients and servers. The paper "FedKD: Communication Efficient Federated Learning via Knowledge Distillation" (2108.13323) addresses this challenge by introducing a novel framework that leverages knowledge distillation to enhance communication efficiency.
FedKD Framework
The core innovation of FedKD lies in its adaptive mutual distillation architecture, where each client maintains both a large teacher model and a smaller shared student model. The teacher model remains local, while the student model is periodically transferred between clients and the central server, significantly reducing the communication overhead.
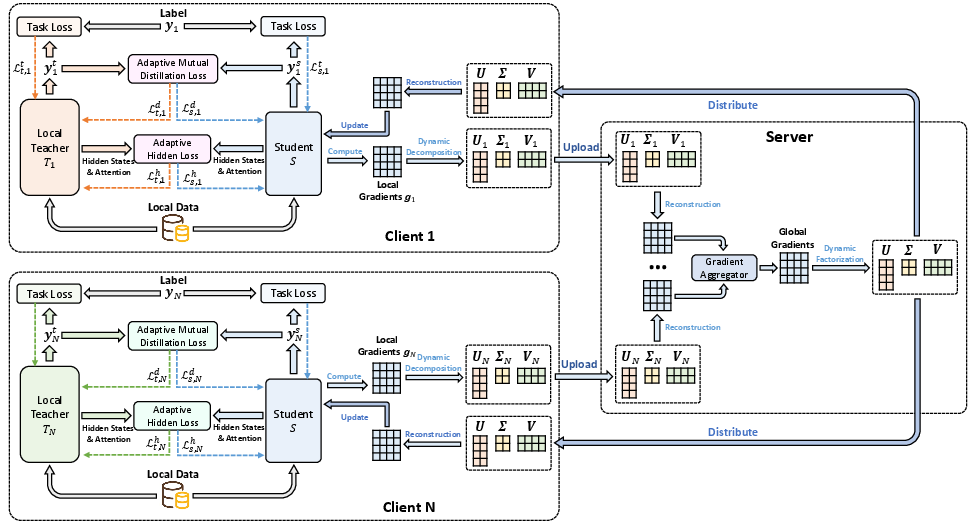
Figure 1: The framework of our FedKD approach.
The adaptive nature of the distillation process is guided by the prediction quality of each model, ensuring that only reliable knowledge is transferred. This is achieved through a dynamic adjustment of distillation intensity based on the correctness of predictions, aiming to prevent the negative effects of noisy or unreliable knowledge exchange.
Dynamic Gradient Approximation
Another highlight of the approach is the use of dynamic gradient approximation via Singular Value Decomposition (SVD). This technique compresses the gradients exchanged during communication, further reducing the data payload. By dynamically adjusting the precision of these gradients, FedKD ensures robustness in model convergence with minimal communication cost.
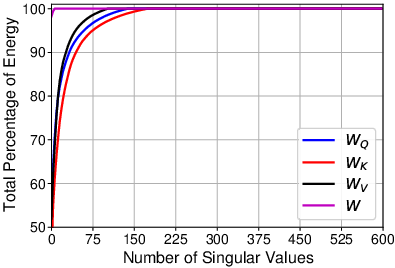
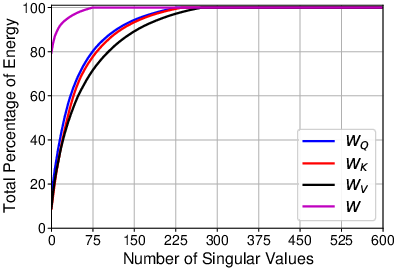
Figure 2: Cumulative energy distributions of singular values of different parameter gradient matrices. W_Q: query parameters, W_K: key parameters, W_V: value parameters, W: feed-forward network parameters.
Experimental Results
The paper provides extensive empirical evidence across several benchmark datasets, demonstrating that FedKD achieves competitive performance with a substantially lower communication burden compared to traditional FL methods. Specifically, the experiments conducted on the MIND and SMM4H datasets show that FedKD outperforms existing methods both in prediction accuracy and communication efficiency.
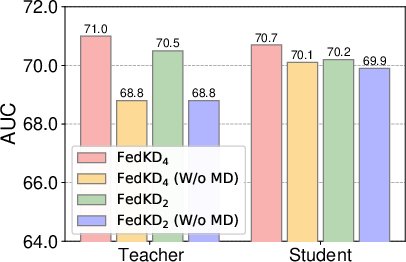
Figure 3: Influence of mutual distillation on the student and teacher models.
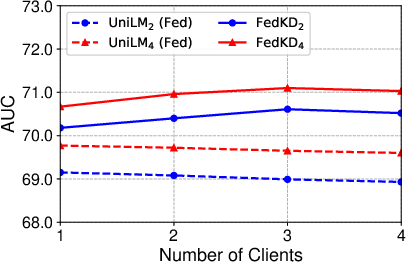
Figure 4: Influence of client number.
Impact on Client and Server Communication
Client number and aggregation strategies play a crucial role in FL. The experiments reveal that FedKD maintains its efficacy even as the number of clients increases, suggesting its scalability and robustness in real-world scenarios. This adaptability makes FedKD a promising candidate for widespread FL deployments where communication costs are a primary concern.
Future Directions
The implications of FedKD extend beyond mere communication efficiency. By successfully integrating knowledge distillation into federated learning, it opens avenues for further research into adaptive learning strategies in decentralized environments. Future work could consider extending this framework to other types of models and broader application domains.
Additionally, exploring different configurations of teacher and student models, such as varying their architectures or incorporating multitask learning paradigms, could further enhance the framework’s adaptability to diverse datasets and use cases.
Conclusion
In conclusion, FedKD presents a significant advancement in federated learning by effectively merging knowledge distillation with communication efficiency strategies. This framework not only tackles the high communication costs traditionally associated with FL but also sets the stage for further innovations in privacy-preserving decentralized learning. Its robust performance and communication savings underline the potential for practical applications across various domains where data privacy and communication bandwidth are critical considerations.