- The paper introduces FedFD, which leverages feature distillation with orthogonal projections to improve knowledge aggregation in heterogeneous federated learning.
- The paper demonstrates FedFD’s superiority with up to a 16.09% test accuracy improvement over traditional methods on CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets.
- The paper highlights the efficiency and stability of FedFD, reducing communication rounds and storage requirements while effectively integrating diverse client models.
Feature Distillation for Model-Heterogeneous Federated Learning
Introduction
The paper "Feature Distillation is the Better Choice for Model-Heterogeneous Federated Learning" introduces FedFD, a method designed to enhance the performance of federated learning (FL) systems with heterogeneously structured models. By leveraging feature distillation instead of logit-based approaches, FedFD aims to efficiently aggregate client models' diverse knowledge while minimizing the instability observed in traditional methods. This technical paper thoroughly explores the proposed method's advantages compared to other state-of-the-art techniques and analyzes its potential applications.
Methodology
FedFD proposes using feature-based distillation to align the feature representations with orthogonal projections, addressing the limitations inherent in logit-based knowledge transfer. Logit distillation in homogeneous settings typically benefits from the shared structure among models, enabling a stable knowledge aggregation process. However, this paper highlights the instability and ineffective knowledge transfer when logit distillation is blindly applied to heterogeneous models due to the diverse feature spaces client models may operate within.
To counter these challenges, FedFD maintains a comprehensive projection layer for each unique feature group aggregated from the client-side models. This approach ensures consistent feature alignment, highlighting the potential of hierarchical feature alignment in reducing server storage costs. Orthogonal projections play a crucial role in this method, helping navigate knowledge conflicts arising from merging feature representations produced by diverse model architectures.
Experimental Evaluation
Empirical evaluations were conducted using CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets, each partitioned heterogeneously to simulate real-world data distribution. The server model, mainly a ResNet-18, aggregated knowledge from various client-side models varying in computational complexities. The extensive experiments demonstrated that FedFD consistently outperformed other baselines, achieving up to a 16.09% improvement in test accuracy. These results underscore FedFD's scalability and robustness against data heterogeneity and model architecture variability.
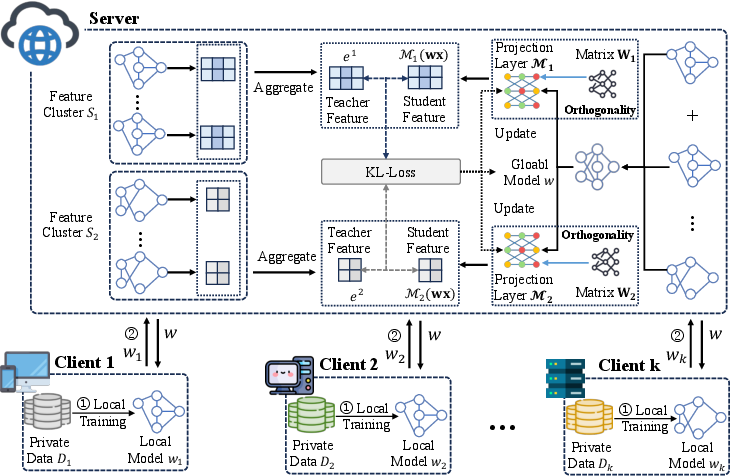
Figure 1: The framework of FedFD. Before knowledge distillation, each client first trains on its local dataset and then uploads its local model to the server.
Communication Efficiency and Convergence
FedFD exhibits superior communication efficiency, requiring fewer communication rounds to attain target accuracy when contrasted with both homogeneous and heterogeneous federated learning (FL) methods. While traditional logit distillation is prone to instability and potential convergence issues in heterogeneous settings, FedFD's sophisticated feature-based approach mitigates these concerns, ensuring a more consistent and efficient aggregation process across diverse models.
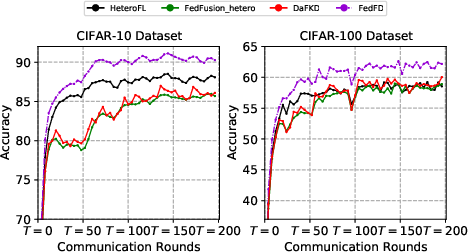
Figure 2: Convergence and efficiency comparison of various methods on two datasets.
Ablation Studies and Sensitivity Analysis
The ablation studies confirmed the significance of each FedFD component, with orthogonal projections proving particularly essential for mitigating cross-model feature space conflicts. Additionally, sensitivity analyses reflected FedFD's adaptability to different datasets and model distributions, affirming its potential for broad applicability across distinct FL scenarios.
Conclusion
The FedFD framework concretely advances the field of model-heterogeneous federated learning by prioritizing feature distillation over traditional logit-based approaches, proving to be a well-optimized, innovative structure facilitating effective knowledge integration across varied client models. The method's practical implications indicate significant potential for future research and development in distributed learning frameworks, particularly focusing on orthogonal projections and feature alignment opportunities. As Federated Learning continues evolving and LLMs gain prominence, the principles discussed and refined within FedFD could guide future explorations into federated frameworks accommodating even more diverse computational models.