- The paper demonstrates that LLMs trained via reinforcement learning with dense rewards show improved tactical reasoning but remain below human-level strategic performance.
- It employs a RLVR framework using chess puzzles and dense reward signals from a pre-trained chess action-value network to optimize move prediction.
- Despite enhancements via supervised fine-tuning, LLMs struggle with fundamental chess rules, indicating a need for integrated domain-specific pre-training.
Insights into Strategic Reasoning through Chess in LLMs
The paper "Can LLMs Develop Strategic Reasoning? Post-training Insights from Learning Chess" investigates the feasibility of developing strategic reasoning in LLMs via reinforcement learning using chess as a benchmark task. The study focuses on understanding whether LLMs can learn the complex, multi-step reasoning required for strategic games like chess without explicitly encoding chess-specific knowledge into the models during pre-training.
Methodology
The authors employ a reinforcement learning with verifiable rewards (RLVR) framework to train LLMs for chess strategic reasoning. Two LLMs, Qwen2.5 and Llama3.1, are fine-tuned using a dataset of chess puzzles, with their performance evaluated based on their ability to predict optimal moves.
The study leverages dense reward signals derived from a pre-trained chess action-value network, which functions as a domain expert by scoring moves based on their estimated win probability. This method contrasts with the typical sparse reward systems, providing a continuous feedback mechanism allowing the models to improve move quality via graded feedback.
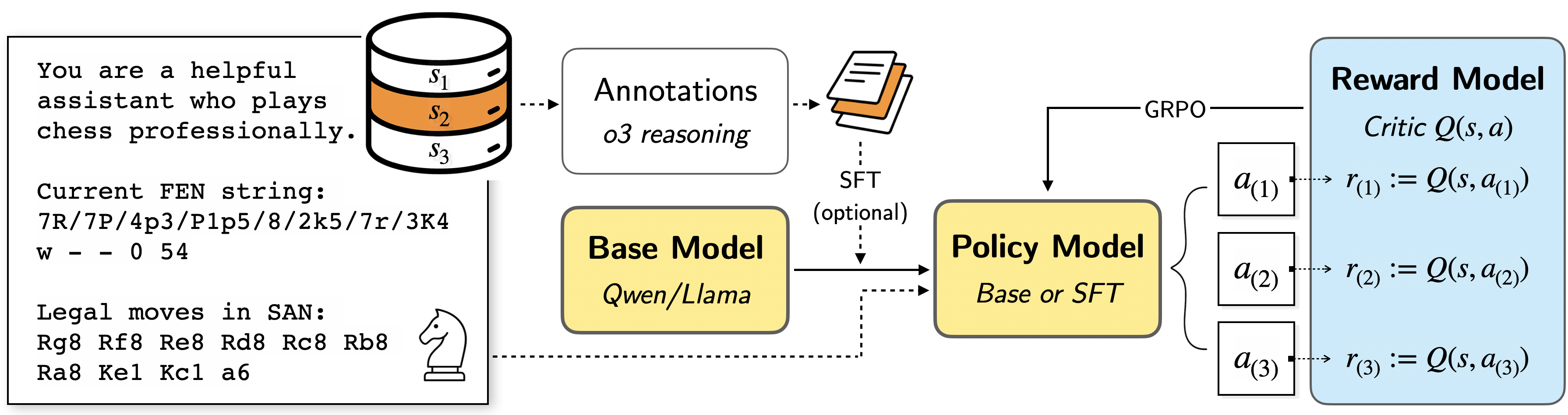
Figure 1: Overview of LLM chess training pipeline using GRPO for policy improvement with dense rewards.
Experimental Results
The study demonstrates that models trained with dense rewards significantly outperform those trained with sparse, binary rewards. Dense feedback allows the models to learn more nuanced strategic decision-making, enhancing puzzle-solving accuracy. However, both models plateau well below human expert level accuracy, around 25-30%, indicating a persistent limitation in learning depth strategic reasoning skills purely through RL.
Figure 2: Evaluation performance comparison of RL fine-tuned models.
Reasoning Enhancement through SFT
Subsequent evaluation involves using supervised fine-tuning (SFT) with OpenAI o3-generated reasoning traces. Despite the enriched pre-training with reasoning traces, models still display similar performance ceilings when subsequently trained through RL, suggesting limited augmentation in strategic capabilities.
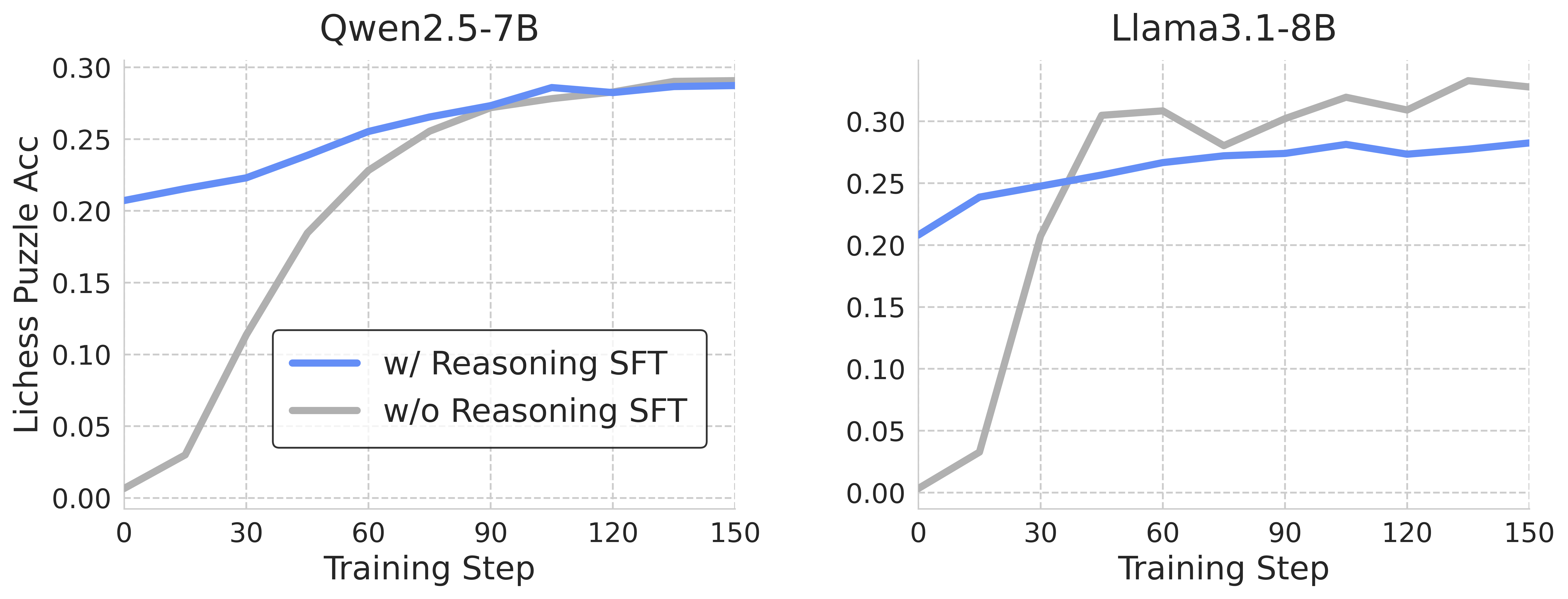
Figure 3: Evaluation performance of models trained with reasoning SFT followed by RL fine-tuning.
Diagnostic Evaluation
A diagnostic assessment highlights that models struggle with fundamental chess rules comprehension, supporting the hypothesis that the deficient internal model of chess mechanics stifles strategic reasoning development.
Discussion
Despite notable progress in tactical reasoning through dense reward learning, the research reveals intrinsic limitations in LLMs' ability to autonomously develop profound strategic understanding in chess through RL alone. The finding aligns with broader research suggesting that RL tends to amplify existing capabilities rather than develop new reasoning skills de novo.
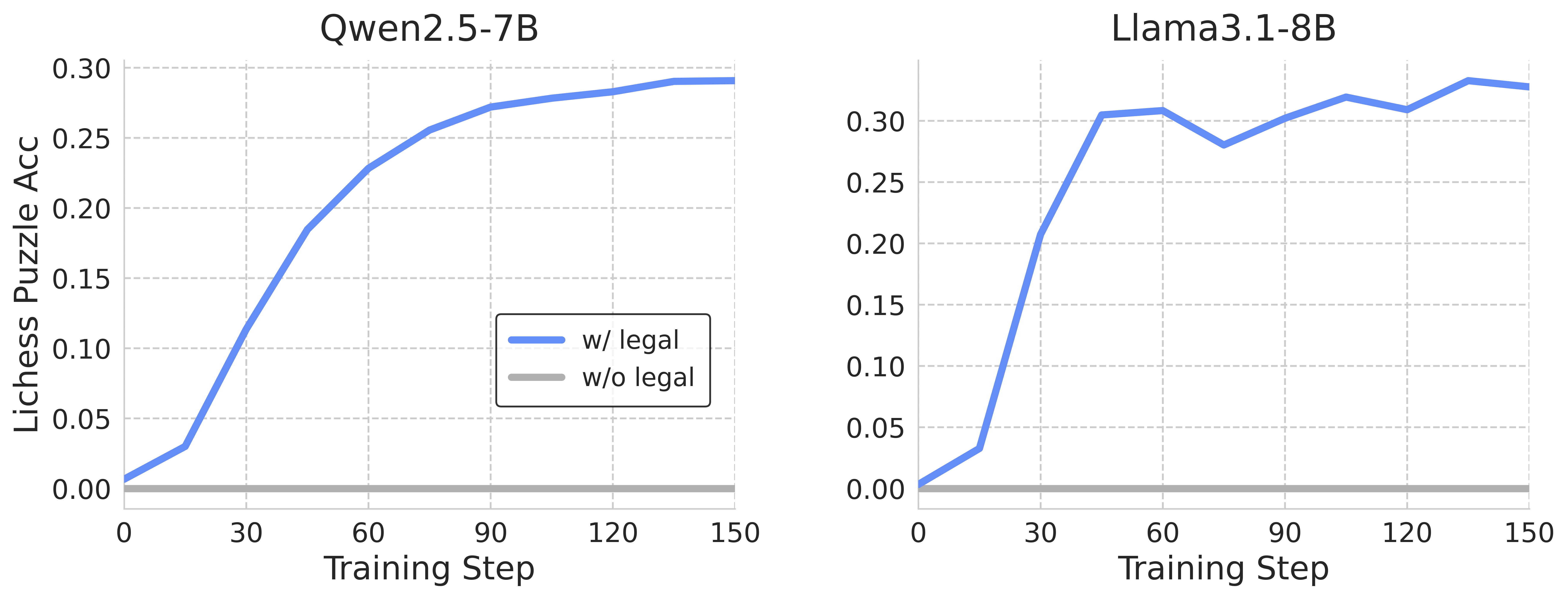
Figure 4: Evaluation performance comparison with and without legal moves in input prompts showcasing dependency on explicit prompt information.
The study speculates that the fundamental issue lies in the lack of domain-specific knowledge during pre-training. This shortfall impedes the models' ability to comprehend and optimize state transitions and effective strategy formulation inherently required by strategic games like chess.
Conclusion
The research concludes that current LLMs, when isolated from rich domain-specific pre-training, exhibit subpar strategic reasoning capabilities, limited by inherent deficiencies in understanding tactical components and state dynamics of chess. Future directions may explore integrating more comprehensive pre-training with strategic task-specific knowledge to address these challenges, facilitating the autonomous development of strategic reasoning in LLMs. This study serves as a critical insight into the requisites for effective strategic competence in AI models, emphasizing the need for enriched learning paradigms that transcend mere reward optimization.