- The paper introduces CausalVQA, a novel benchmark that evaluates causal reasoning in video models using physically grounded questions.
- The dataset features five question types—including counterfactual and hypothetical—that elucidate the challenges for current multimodal models.
- Evaluation reveals a performance gap of over 22% between top AI models and human baselines, highlighting areas for improvement.
"CausalVQA: A Physically Grounded Causal Reasoning Benchmark for Video Models" Summary
Introduction to CausalVQA
The CausalVQA benchmark addresses a significant gap in video question answering (VQA) by focusing on causal reasoning in real-world scenarios. Traditional VQA benchmarks either emphasize superficial perceptual understanding of videos or narrow physical reasoning within controlled simulations. CausalVQA provides a robust assessment by posing video-based questions in five categories: counterfactual, hypothetical, anticipation, planning, and descriptive. This benchmark highlights the challenges current multimodal models face in leveraging spatial-temporal reasoning and physical principles to predict outcomes.
The creation of CausalVQA involved quality control measures to ensure models answer based on visual understanding rather than trivial shortcuts. An essential finding during testing was the substantial performance gap between state-of-the-art multimodal models and human performance, particularly in anticipation and hypothetical question types.
Dataset Design and Methodology
The CausalVQA dataset is constructed from egocentric videos sourced from the EgoExo4D dataset. The process involved several steps to ensure diversity and relevance of question-answer pairs, including:
- Video Selection: Focused on goal-directed activities with rich interactions, such as sports and cooking.
- Question Generation: Annotators created visually grounded questions emphasizing causal understanding.
- Distractor Generation: Used vision LLMs (VLMs) to generate plausible incorrect answers.
- Quality Control: Involved human reviews and model-based checks to remove questions answered through superficial cues.
The resulting dataset includes 1,786 items categorized by question type and difficulty, designed to rigorously test visual and causal reasoning capabilities.
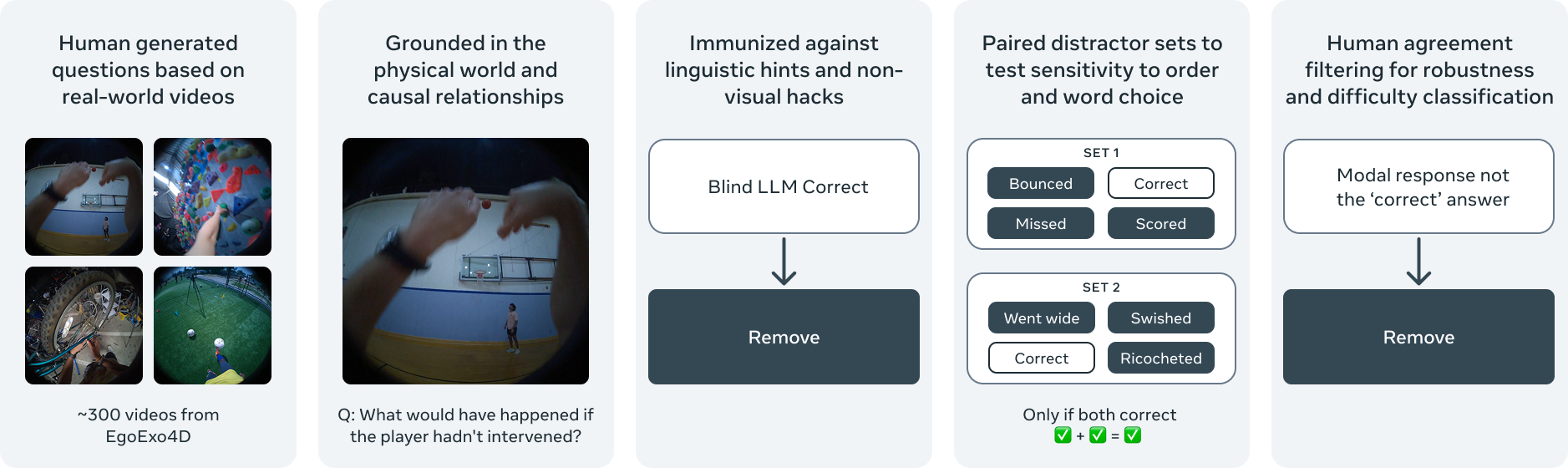
Figure 1: Process of generating and curating question-answer pairs for CausalVQA. Multiple steps were incorporated to ensure diversity and visual groundedness, reducing susceptibility to shortcuts.
Evaluation and Results
The benchmark was evaluated using both contemporary closed models, like GPT-4o and Gemini 2.5 Flash, and open multimodal models, such as PerceptionLM and Qwen2.5VL. Key findings indicate that:
- There is a significant gap of over 22% in overall performance between the best model and human baseline on reasoning questions.
- Anticipation and hypothetical questions posed the most significant challenges for models, highlighting their struggle in predicting potential outcomes and understanding counterfactual scenarios.
- The best-performing models, like Gemini 2.5 Flash, achieved a paired score of only 61.66% compared to human performance at 84.78%.
CausalVQA distinguishes itself from other benchmarks by emphasizing realistic scenarios and requiring models to possess deep causal reasoning capabilities. Unlike synthetic benchmarks such as CLEVRER and ContPhy, which use controlled environments, CausalVQA excels in realism and diversity by relying on actual video footage. Furthermore, it addresses shortcut mitigation through a carefully curated setup that demands genuine visual reasoning.
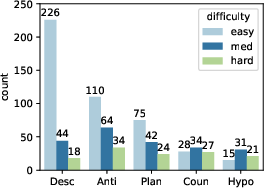
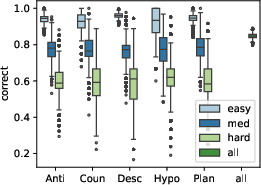
Figure 2: Number of question pairs for each question category and difficulty level.
The benchmark also contrasts with long-form video understanding benchmarks like EgoSchema, by focusing on short-horizon causal reasoning which is crucial for real-time AI applications.
Implications and Future Directions
CausalVQA serves as a significant step toward developing AI systems with robust real-world reasoning capabilities. It presents a clear challenge to current models in understanding cause-and-effect dynamics inherent in physical interactions. Moving forward, potential improvements in CausalVQA could include expanding the dataset's scope and integrating more modalities, such as audio, to enrich the multimodal reasoning experience.
Research informed by CausalVQA may lead to architectures that better understand and predict interactions between objects and humans, ultimately advancing AI's ability to assist in complex real-world tasks.
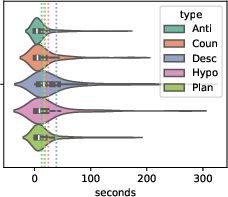
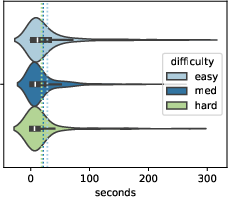
Figure 3: Clip duration distribution by question category. Dotted vertical lines indicate means.
Conclusion
CausalVQA offers a comprehensive evaluation framework for testing multimodal AI models on crucial aspects of physical reasoning and causal understanding. By doing so, it paves the way for substantial advancements in AI's ability to comprehend and engage with the physical world, while also setting a baseline to inspire future developments in this challenging domain.