Pretraining Large Language Models with NVFP4
Abstract: LLMs today are powerful problem solvers across many domains, and they continue to get stronger as they scale in model size, training set size, and training set quality, as shown by extensive research and experimentation across the industry. Training a frontier model today requires on the order of tens to hundreds of yottaflops, which is a massive investment of time, compute, and energy. Improving pretraining efficiency is therefore essential to enable the next generation of even more capable LLMs. While 8-bit floating point (FP8) training is now widely adopted, transitioning to even narrower precision, such as 4-bit floating point (FP4), could unlock additional improvements in computational speed and resource utilization. However, quantization at this level poses challenges to training stability, convergence, and implementation, notably for large-scale models trained on long token horizons. In this study, we introduce a novel approach for stable and accurate training of LLMs using the NVFP4 format. Our method integrates Random Hadamard transforms (RHT) to bound block-level outliers, employs a two-dimensional quantization scheme for consistent representations across both the forward and backward passes, utilizes stochastic rounding for unbiased gradient estimation, and incorporates selective high-precision layers. We validate our approach by training a 12-billion-parameter model on 10 trillion tokens -- the longest publicly documented training run in 4-bit precision to date. Our results show that the model trained with our NVFP4-based pretraining technique achieves training loss and downstream task accuracies comparable to an FP8 baseline. These findings highlight that NVFP4, when combined with our training approach, represents a major step forward in narrow-precision LLM training algorithms.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary: Pretraining LLMs with NVFP4
1. What is this paper about?
Training very large AI LLMs takes huge amounts of time, computer power, and energy. One way to make training faster and cheaper is to use numbers with fewer bits (lower precision) during the math. This paper introduces a new way to train LLMs using 4-bit numbers, called NVFP4, and shows how to keep training stable and accurate even with such small numbers.
2. What questions were they trying to answer?
- Can big LLMs be trained with 4-bit numbers (NVFP4) and still match the accuracy of training with 8-bit numbers (FP8)?
- What tricks are needed to make 4-bit training stable for very long training runs?
- Is NVFP4 better than an older 4-bit format (MXFP4)?
- What speed and memory savings can NVFP4 offer in real training?
3. How did they do it? (Methods explained simply)
Think of storing and doing math on numbers like saving images: the more you compress, the faster and smaller things get, but details can be lost. The team designed NVFP4 to “compress” numbers cleverly so training stays accurate.
Key ideas behind NVFP4:
- NVFP4 keeps numbers in small tiles (16 values at a time) and uses two levels of scaling:
- A fine, per-tile scale stored in 8-bit format to fit local values nicely.
- A broader, per-tensor scale in 32-bit format to preserve overall range.
- Smaller tiles (16 vs. 32 in older formats) better match the local size of values, which reduces errors.
- The hardware (NVIDIA Blackwell Tensor Cores) natively supports NVFP4, making the math very fast and memory-efficient.
To make 4-bit training work smoothly, they combined four practical techniques:
- Keep some sensitive layers in higher precision: about 15% of the network (mostly near the end) uses BF16 or FP8, because those layers need more detail.
- Random Hadamard transforms: imagine loud spikes in audio being spread out so no single point is too loud. This transform spreads “outlier” values across many values so they fit better in 4 bits. They apply this only to the inputs used when computing weight gradients, using 16×16 tiles and a random sign pattern.
- 2D scaling of weights: instead of scaling in just one direction, they scale weight tiles in both directions (16×16 blocks). This keeps the weight values consistent between the forward and backward passes, so the learning rules line up correctly.
- Stochastic rounding for gradients: when a value sits between two 4-bit options, they flip a “fair coin” to decide whether to round up or down. This prevents consistent rounding bias and improves learning stability.
The hardware part:
- NVIDIA Blackwell GPUs have special cores (Tensor Cores) that run NVFP4 math quickly, support precise scaling, and even support stochastic rounding in hardware.
- Compared to FP8, NVFP4 can deliver 2× to 3× higher math throughput and about half the memory usage for operands, which is a big win for speed and cost.
4. What did they find?
- They trained a very strong 12-billion-parameter model on 10 trillion tokens (that’s a very long training run) using NVFP4. The training loss (a measure of how well the model is learning) stayed within about 1% of the FP8 baseline during most of training, widening slightly to ~1.5% at the very end when the learning rate decayed.
- On many real-world tests (like reasoning, math, and general knowledge), the NVFP4-trained model matched the FP8 model’s accuracy. For example, on MMLU-Pro (a tough knowledge test), NVFP4 achieved 62.58% vs. 62.62% for FP8—essentially the same. There was a small dip on some coding tasks, likely due to noisy evaluation near the final checkpoint.
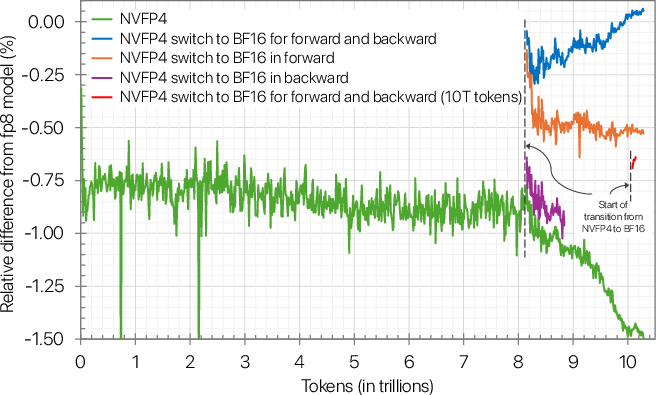
- If you need to close the tiny loss gap, switching back to higher precision near the end of training “heals” the difference.
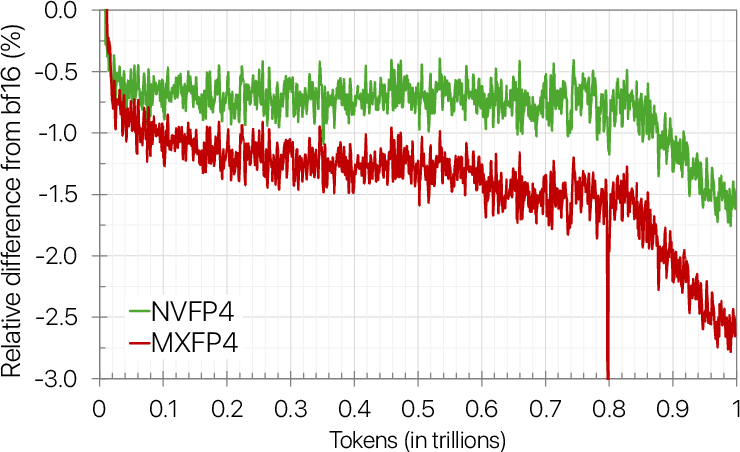
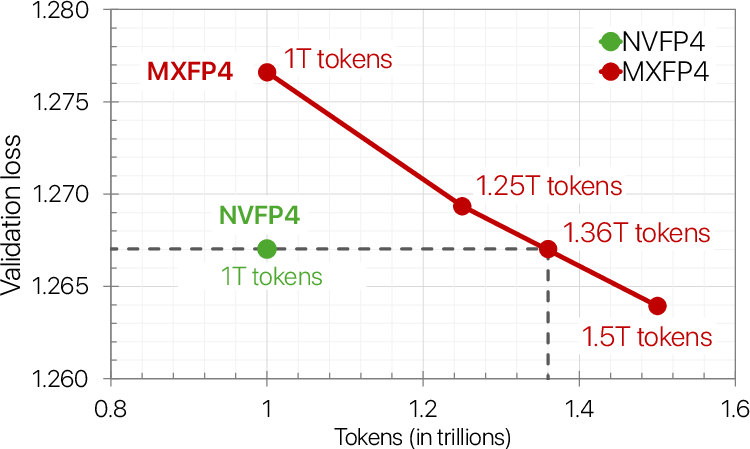
- NVFP4 vs. MXFP4: NVFP4 converged better. In tests with an 8B model, MXFP4 needed about 36% more training tokens to reach the same final loss as NVFP4, meaning NVFP4 is more efficient.
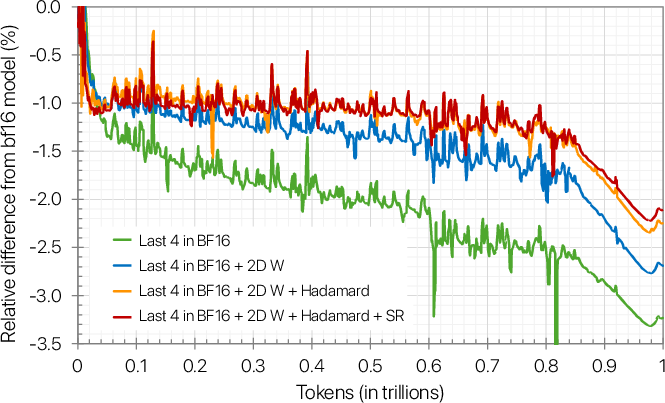
- Ablation studies (removing one technique at a time) showed that each of the four techniques above was important. Removing any one of them made training worse.
5. Why does this matter? (Implications)
Training LLMs with 4-bit precision that still match 8-bit accuracy is a big step forward. It means:
- Faster training, lower costs, and less energy use, which makes building and improving powerful AI models more accessible.
- The method works at very large scales and long training lengths, paving the way for even bigger and better models.
- NVFP4 reduces token and time budgets compared to older 4-bit formats, so teams can train more efficiently.
- The approach is supported in open-source tools (Transformer Engine), making it easier for others to adopt.
- Future work could make even more of the model 4-bit, extend NVFP4 to attention and communication paths, and apply it to larger models and new architectures like mixture-of-experts.
In short, this paper shows that smart number handling (NVFP4 plus the four techniques) can keep training accurate while cutting speed and memory costs—helping the next generation of AI models arrive faster and more efficiently.
Practical Applications
Below are actionable, real‑world applications grounded in the paper’s findings, methods, and innovations. Each item names the use case, links it to sectors, sketches likely tools/products/workflows, and lists key assumptions/dependencies that affect feasibility.
Immediate Applications
- Industrial LLM pretraining cost and energy reduction
- Sectors: software/AI infrastructure, cloud, energy
- What: Migrate FP8 training recipes to NVFP4 to cut math cost (2–3× throughput vs FP8) and roughly halve memory for GEMM operands; maintain accuracy with the paper’s recipe (2D weight scaling, Wgrad-only Random Hadamard transforms, stochastic rounding on gradients, selective high‑precision layers).
- Tools/workflows: NVIDIA Transformer Engine support for NVFP4; PyTorch/Megatron-LM integrations; job templates that pin the final ~10–15% of blocks in BF16/MXFP8; precision schedule (“healing”) that switches to BF16/FP8 late in training if minimal loss gaps are critical.
- Assumptions/dependencies: Access to NVIDIA Blackwell GPUs with FP4 Tensor Cores and stochastic rounding; training is GEMM‑dominated; RHT/2D scaling overhead is managed; acceptance of mixed precision layers.
- Cloud FP4 training SKUs and SLAs
- Sectors: cloud providers, MLOps
- What: Offer “FP4-optimized pretraining” instances with documented TCO/throughput gains and a reference recipe (NVFP4 + methodology).
- Tools/workflows: Instance images with pre-installed CUDA/cuBLASLt/Transformer Engine; monitoring dashboards exposing quantization stats (amax, scale histograms, saturation rate), SR usage, and loss parity vs FP8.
- Assumptions/dependencies: Cloud fleet includes GB200/GB300; customer workloads are compatible (no custom ops blocking FP4).
- Academic mid‑scale pretraining within limited budgets
- Sectors: academia, non‑profits
- What: Run 1–12B parameter pretraining with NVFP4 to fit grants/compute allocations while maintaining benchmark parity; reallocate savings to more ablations or longer token horizons.
- Tools/workflows: Reference configs for sequence lengths up to 8k, WSD learning rates, 2D weight scaling, Wgrad RHT(d=16), and SR-on-gradients.
- Assumptions/dependencies: Access to Blackwell (campus cluster or cloud); ability to keep sensitive layers in BF16; evaluations in BF16.
- Vertical/domain model pretraining under tighter SLAs
- Sectors: healthcare, finance, legal, industrial engineering, multilingual
- What: Pretrain domain‑specific LLMs (e.g., clinical, financial, multilingual) with NVFP4 to hit time/cost targets while preserving accuracy vs FP8; use “heal to BF16” in the decay phase for critical‑loss targets.
- Tools/workflows: Domain data blends; automated checkpoint gating on domain evals; precision scheduler to BF16/MXFP8 only at the end.
- Assumptions/dependencies: Data pipelines and evals already in place; acceptable to keep embeddings/attention/non‑linearities in higher precision as per paper.
- Faster exploratory HPO and ablations
- Sectors: software/AI research, MLOps
- What: Use NVFP4 to run more concurrent hyperparameter sweeps and ablations (optimizer βs, LR schedules, data blends) within fixed compute budgets.
- Tools/workflows: Orchestrators (Ray/Tuning) plus FP4-aware templates; early‑stopping on loss gap vs FP8 baseline; automatic layer sensitivity scans to minimize BF16 footprint.
- Assumptions/dependencies: Workloads dominated by GEMMs; instrumentation for loss-gap tracking.
- Capacity planning and datacenter scheduling with lower carbon intensity
- Sectors: cloud, policy/ESG, energy
- What: Incorporate FP4 options into schedulers to increase concurrent jobs per cluster and reduce kWh/job; publish ESG metrics that credit low‑precision training.
- Tools/workflows: Carbon accounting pipelines that attribute energy savings to FP4; internal guidelines to prefer FP4 pretraining when accuracy parity is demonstrated.
- Assumptions/dependencies: Metered power/telemetry; auditors accept FP4-based savings; workloads adhere to NVFP4 recipe to avoid regressions.
- Production continuous pretraining/refresh cycles at lower cost
- Sectors: AI product teams, LLMOps
- What: Adopt NVFP4 for regular model refreshes (data recency, safety updates) to shrink cycle time and cost; switch to BF16/MXFP8 only for final checkpoints if needed.
- Tools/workflows: CI/CD pipelines with precision schedules; drift monitors using downstream task panels (MMLU, GSM8K, code suites).
- Assumptions/dependencies: Stable parity on product‑critical tasks; allowance for small coding-task variance noted in the paper.
- Training recipe/productization
- Sectors: software tooling, compilers
- What: Package NVFP4 training as reusable components: 2D weight scaling modules, Wgrad‑only RHT(d=16) kernels with random sign vectors, SR‑on‑gradients toggles, and per‑layer precision maps.
- Tools/workflows: Transformer Engine operators; PyTorch modules for NVFP4 quantization with global amax scans; validation harnesses that compare against FP8 loss curves.
- Assumptions/dependencies: Upstreaming/maintenance of kernels; overhead of global-amax pass is amortized or fused; attention/softmax remain in higher precision as per current recipe.
- Lower-cost AI services for end users (indirect)
- Sectors: consumer and enterprise software
- What: Translate training cost savings into cheaper API pricing, more frequent model updates, and broader language coverage.
- Tools/workflows: Pricing calculators incorporating FP4 savings; roadmap acceleration due to higher training throughput.
- Assumptions/dependencies: Providers pass savings on; accuracy meets product thresholds.
Long‑Term Applications
- All‑FP4 training paths (beyond linear layers)
- Sectors: software/AI infrastructure, hardware
- What: Extend NVFP4 to attention paths, embeddings, normalization, and communication collectives to eliminate remaining high‑precision islands.
- Tools/products: End‑to‑end FP4 kernels; collectives with FP4 packing/scaling; attention softmax stabilization methods in FP4.
- Assumptions/dependencies: New algorithms to maintain stability; further ablations to quantify quality impact.
- Trillion‑parameter and MoE pretraining with FP4
- Sectors: frontier AI labs, cloud
- What: Use NVFP4 to reduce cost/time for trillion‑parameter dense and MoE models; explore scaling laws indicating token reductions similar to the NVFP4>MXFP4 advantage.
- Tools/workflows: Expert routing with FP4‑aware communication; per‑expert precision policies; precision‑adaptive schedulers.
- Assumptions/dependencies: Network/comm bottlenecks do not erase FP4 gains; MoE stability with FP4 is demonstrated.
- Auto‑precision controllers and compilers
- Sectors: software tooling, compilers
- What: Automated systems that choose per‑layer precision, apply 2D scaling, schedule RHT, and trigger “healing” to higher precision based on live loss/gradient statistics.
- Tools/products: Compiler passes for precision annotations; runtime observers for amax/outlier density; auto‑tuning of RHT dimension and SR scopes.
- Assumptions/dependencies: Robust proxies for divergence risk; integration with graph compilers (e.g., TorchInductor, XLA).
- FP4‑native checkpoints and logistics
- Sectors: MLOps, model distribution
- What: New checkpoint formats that co‑store FP4 values, E4M3 block scales, and FP32 tensor scales to reduce storage/egress while preserving exact training state reconstructions.
- Tools/products: Checkpoint converters; verifiers that round‑trip to BF16/FP32 with bounded error; registry metadata for quantization state.
- Assumptions/dependencies: Optimizer states may still require FP32; reproducibility guarantees must be validated.
- Multimodal FP4 training (vision, speech, robotics)
- Sectors: vision, speech, robotics, autonomous systems
- What: Extend NVFP4 methodology to multimodal encoders/decoders; tailor RHT/2D scaling to convolutional and attention-heavy backbones.
- Tools/products: FP4 quantization recipes for ViTs, diffusion U-Nets, ASR/TTS stacks; robotics foundation model training with FP4.
- Assumptions/dependencies: Modality‑specific numerics may need different block sizes/scales; attention paths need FP4‑stable designs.
- Federated and edge FP4 fine‑tuning
- Sectors: mobile/edge, privacy
- What: Explore FP4 for on‑prem or federated fine‑tuning to reduce compute/energy at the edge while keeping accuracy; combine with LoRA/adapter methods.
- Tools/workflows: FP4‑aware LoRA layers; secure aggregation with FP4 packing; device‑adaptive precision controllers.
- Assumptions/dependencies: Edge hardware with FP4 support; stable FP4 fine‑tuning algorithms.
- Green AI standards and procurement policy
- Sectors: policy/ESG, government, enterprises
- What: Create procurement guidelines and reporting standards that recognize low‑precision training as a best practice for reducing emissions.
- Tools/products: Benchmarks and disclosure templates for precision usage; certification programs recognizing FP4 adoption.
- Assumptions/dependencies: Independent validation that FP4 maintains quality; consensus on carbon accounting for precision changes.
- Outlier‑aware data pipelines and curricula for FP4
- Sectors: academia, AI research
- What: Curate data blends and curricula that minimize FP4‑unfriendly outliers late in training; automate dataset phase transitions to reduce loss gaps.
- Tools/workflows: Outlier density analyzers; adaptive curriculum schedulers aligned with precision phases; data blend optimization.
- Assumptions/dependencies: Measurable link between data phases and FP4 stability; generalization across domains.
- Hardware co‑design for FP4 era
- Sectors: semiconductors, systems
- What: Architect memory hierarchies and Tensor Core micro‑ops that reduce overhead of global amax passes, accelerate 2D scaling, and fuse RHT transforms.
- Tools/products: ISA support for fused encode/scale/quantize; on‑device amax reduction primitives; configurable FP4 block sizes.
- Assumptions/dependencies: Sufficient demand for FP4‑first training; software stacks exploit new primitives.
- Lower‑cost AI access for society (indirect, scaled impact)
- Sectors: education, SMEs, public sector
- What: As FP4 reduces pretraining cost, more specialized and multilingual models become economically viable, improving access in education and public services.
- Tools/workflows: Public‑domain models trained with FP4; curricula using affordable models; government AI services with lower operating cost.
- Assumptions/dependencies: Sustained parity across tasks; open licensing and responsible release practices.
Notes on feasibility: The paper demonstrates parity on a 12B hybrid Mamba‑Transformer trained over 10T tokens, with clear recipes: 2D weight scaling (16×16), Wgrad‑only Random Hadamard transforms (d=16 with random sign vectors), stochastic rounding on gradients, and selective high‑precision layers (~10–16%). Results rely on Blackwell FP4 Tensor Cores and Transformer Engine support; attention/softmax and several non‑linearities remain in higher precision for now.
Glossary
- 2D block scaling: A quantization scheme that scales weights over two spatial dimensions (e.g., 16×16 blocks) to keep forward and backward quantized representations consistent. "utilizes two-dimensional (2D) block scaling to maintain same quantized representations across forward and backward passes,"
- amax: The maximum absolute value within a set (e.g., a tensor block), used to choose scale factors for quantization. "Scale factors are typically chosen so that the absolute maximum value (amax) within a block maps to the FP4 maximum representable,"
- Ablation study: An experiment that removes or alters one component at a time to assess its impact on performance or convergence. "Ablation studies confirm that each component of this methodology is important for 4-bit training,"
- AGIEval English CoT: A chain-of-thought variant of the AGIEval benchmark used to evaluate reasoning ability. "AGIEval English CoT"
- ARC Challenge: A benchmark testing grade-school science reasoning with challenging multiple-choice questions. "ARC Challenge"
- BF16: Brain floating point with 16 bits (8 exponent, 7 mantissa, 1 sign) used for training stability and efficiency. "GEMM operations consume FP4 tensors as inputs and produce outputs in BF16 or FP32."
- Binade: A range of floating-point numbers sharing the same exponent; losing a binade reduces available dynamic range. "and can potentially lose up to one binade of dynamic range"
- Blackwell GPUs: NVIDIA’s Blackwell architecture GPUs with native support for microscaling formats and FP4/FP8 Tensor Core operations. "NVIDIA Blackwell GPUs provide native support for general matrix multiplications (GEMMs) for a wide range of microscaling formats"
- Dgrad: The GEMM computing activation gradients in backpropagation. "a GEMM in the forward pass (Fprop), and separate GEMMs to compute activation gradients (Dgrad) and weight gradients (Wgrad) in the backward pass."
- E2M1: A floating-point layout with 1 sign bit, 2 exponent bits, and 1 mantissa bit (used for FP4 elements). "In MXFP4, each element is represented as E2M1"
- E4M3: A floating-point layout with 1 sign bit, 4 exponent bits, and 3 mantissa bits (used here for block scale factors). "block scale factors are stored in E4M3 rather than UE8M0"
- FFN: Feed-Forward Network, the MLP sub-layer within transformer-style architectures. "These models consist of a mixture of Mamba-2, Self-Attention, and FFN blocks."
- FP32: IEEE 32-bit floating point, often used for accumulations and precise scaling. "and accumulate the partial results in higher precision to produce the final dot-product in FP32."
- FP4: 4-bit floating-point format targeted for faster, lower-memory LLM training with careful quantization. "transitioning to even narrower precision, such as 4-bit floating point (FP4),"
- FP8: 8-bit floating-point format widely adopted for accelerated LLM training. "While 8-bit floating point (FP8) training is now widely adopted,"
- Fprop: The GEMM computing the forward pass activations. "a GEMM in the forward pass (Fprop), and separate GEMMs to compute activation gradients (Dgrad) and weight gradients (Wgrad) in the backward pass."
- GEMM: General Matrix-Matrix Multiplication, the core compute primitive for neural network layers. "NVIDIA Blackwell GPUs provide native support for general matrix multiplications (GEMMs) for a wide range of microscaling formats"
- Grouped-Query Attention: An attention variant that groups query heads to share key-value heads for efficiency. "Grouped-Query Attention has 32 query heads along with 4 key-value heads."
- GSM8k CoT: The chain-of-thought version of the GSM8K grade-school math word problem benchmark. "GSM8k CoT"
- HellaSwag: A commonsense inference benchmark focused on choosing the most plausible continuation of a context. "HellaSwag"
- HumanEval+: An augmented coding benchmark for function synthesis and code generation. "HumanEval"
- Mamba-2: A selective state-space model block used as an alternative/complement to attention in hybrid architectures. "These models consist of a mixture of Mamba-2, Self-Attention, and FFN blocks."
- MATH: A benchmark for mathematical problem solving with competition-level questions. "MATH"
- MBPP+: An augmented version of the Mostly Basic Programming Problems benchmark for code generation. "MBPP"
- MGSM: The multilingual version of GSM math word problems. "MGSM"
- Microscaling (MX): A family of formats that share a block-wise scale factor to balance dynamic range and precision in narrow floats. "microscaling (MX) formats~\citep{ocp} were introduced to balance dynamic range and precision."
- MMLU: Massive Multitask Language Understanding benchmark covering many academic subjects. "MMLU"
- MMLU-Pro: A harder variant of MMLU (often with few-shot or chain-of-thought settings) for advanced reasoning evaluation. "MMLU-Pro 5-shot"
- MXFP4: 4-bit microscaling floating-point format with power-of-two block scales. "MX formats include 8-bit (MXFP8), 6-bit (MXFP6), and 4-bit (MXFP4) floating-point types."
- MXFP6: 6-bit microscaling floating-point format sharing the MX design philosophy. "MX formats include 8-bit (MXFP8), 6-bit (MXFP6), and 4-bit (MXFP4) floating-point types."
- MXFP8: 8-bit microscaling floating-point format widely adopted for LLM training. "MX formats include 8-bit (MXFP8), 6-bit (MXFP6), and 4-bit (MXFP4) floating-point types."
- NVFP4: NVIDIA’s enhanced FP4 microscaling format with smaller blocks and FP8-scale factors for improved training accuracy. "NVFP4 is an enhanced 4-bit format that provides improved numerical properties over MXFP4."
- OpenBookQA: A benchmark for open-book science questions requiring reasoning over facts and commonsense. "OpenBookQA"
- PIQA: A physical commonsense reasoning benchmark about everyday situations and object usage. "PIQA"
- Random Hadamard transforms (RHT): Orthogonal transforms applied to tensors to redistribute outliers, improving narrow-precision quantization. "Our method integrates Random Hadamard transforms (RHT) to bound block-level outliers,"
- Random sign vector: A diagonal matrix of ±1 used to randomize Hadamard transforms and avoid alignment with structured outliers. "Random Hadamard transforms introduce randomness by multiplying with a random diagonal sign vector that flips the signs for entire rows or columns."
- RMSNorm: Root Mean Square Layer Normalization variant used in transformer blocks. "RMSNorm~\citep{zhang2019rmsnorm} for the normalization layers,"
- RoPE embeddings: Rotary Position Embeddings used to encode token positions in attention mechanisms. "The model uses RoPE embeddings"
- Stochastic rounding: A probabilistic rounding scheme that reduces quantization bias by rounding to nearby values with distance-proportional probabilities. "We observe that applying stochastic rounding to gradient tensors is essential for convergence in the 12B model,"
- Tensor Cores: Specialized hardware units for mixed-precision matrix math that apply block scales and accumulate in higher precision. "Tensor Cores read narrow precision inputs along with 8-bit scale factors for each block of $16$ or $32$ elements."
- Token horizon: The total span of tokens seen during training; very long horizons stress training stability. "especially in large-scale models and during long token horizons."
- Two-level scaling: A scaling strategy combining per-tensor FP32 scaling with per-block FP8 scaling to fit values into FP4 range. "NVFP4 employs a two-level scaling strategy, which combines a fine-grained FP8 scale factor with an FP32 scale applied at the tensor level."
- UE8M0: Unsigned E8M0 power-of-two format used to store block scale factors in MX formats. "stored in an unsigned E8M0 format (UE8M0), which encodes a power-of-two value"
- Warmup-Stable-Decay (WSD): A learning-rate schedule with an initial warmup, a long stable phase, then a decay phase. "Warmup-Stable-Decay~\citep{hu2024minicpm} learning rate schedule,"
- Wgrad: The GEMM computing weight gradients in backpropagation. "a GEMM in the forward pass (Fprop), and separate GEMMs to compute activation gradients (Dgrad) and weight gradients (Wgrad) in the backward pass."
- Winogrande: A commonsense benchmark focusing on pronoun/coreference disambiguation in sentences. "Winogrande"
- Yottaflops: 1024 floating-point operations; used to express the extreme compute required for frontier LLMs. "Training a frontier model today requires on the order of tens to hundreds of yottaflops,"
Collections
Sign up for free to add this paper to one or more collections.