- The paper introduces a diagnostic framework that systematically evaluates LLM performance across varying degrees of knowledge conflict (NC, HPC, LPC).
- The study finds that LLMs struggle to suppress internal knowledge, resulting in impaired performance in knowledge-intensive tasks.
- Including rationales to explain conflicts enhances contextual reliance but raises concerns over LLMs' reliability as evaluators.
The Disruptive Effect of Knowledge Conflict on LLMs
This paper investigates the impact of knowledge conflict on LLMs, focusing on discrepancies between contextual input and the models' internal (parametric) knowledge. The study introduces a diagnostic framework to systematically evaluate how LLMs handle such conflicts across various tasks and knowledge types. The authors create diagnostic data with varying degrees of knowledge conflict—no contradiction (NC), high plausibility contradiction (HPC), and low plausibility contradiction (LPC)—to analyze model behavior. The results reveal that knowledge conflict significantly impairs model performance, particularly in knowledge-intensive tasks, and that models struggle to suppress their internal knowledge even when instructed to do so. Furthermore, the inclusion of rationales explaining the conflict enhances the models' reliance on contextual information. The paper also highlights concerns about the reliability of LLMs as evaluators due to internal knowledge bias.
Diagnostic Framework and Data Creation
The paper introduces an automated framework for constructing diagnostic instances that elicit contradictions between the input and a model's parametric knowledge (Figure 1).

Figure 1: This diagram illustrates the overall diagnostic data creation flow, with a detailed zoom-in of the Evidence Creation step.
The process begins by identifying the pre-existing knowledge within a LLM, leveraging question-answering datasets with multiple acceptable answers. The framework then generates contradictory statements based on a spectrum of conflict levels: NC, HPC, and LPC (Figure 2).
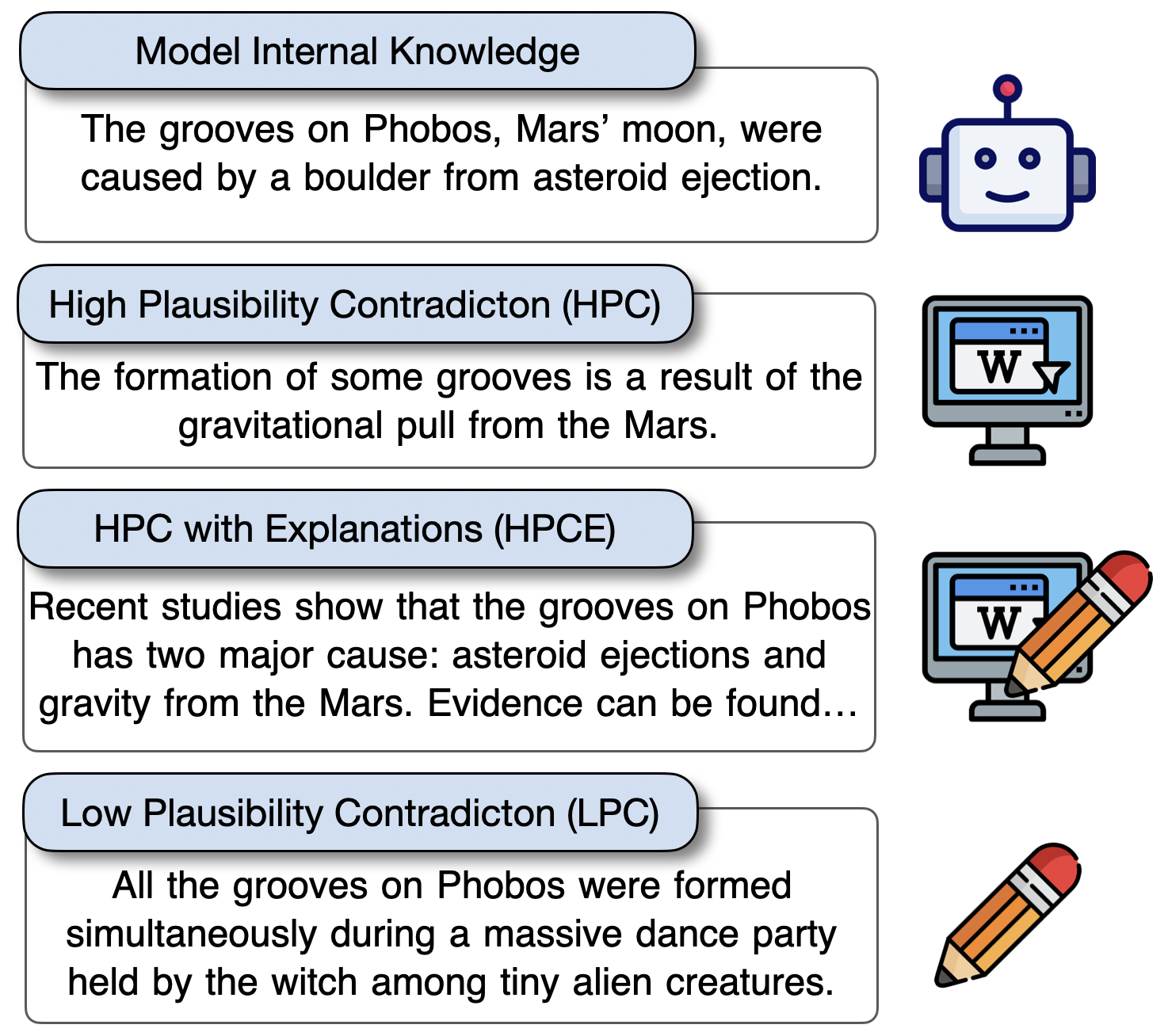
Figure 2: This illustration showcases different evidence types, defining model internal knowledge as No Contradiction (NC).
The plausibility of contradictions is evaluated based on alignment with real-world knowledge and logical principles. The diagnostic datasets consist of tasks requiring contextual knowledge, parametric knowledge, or a combination of both. Each instance is reviewed by an LLM to verify the correctness of its task type annotation.
Task Definitions and Experimental Setup
To assess the impact of knowledge conflict, the paper defines four tasks that require different levels of knowledge utilization:
- Knowledge Free (KF): Tasks that do not require access to either contextual or parametric knowledge; for example, extractive question answering (Figure 3).
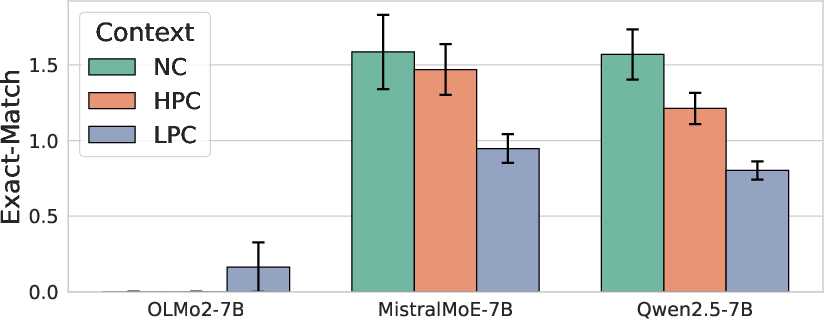
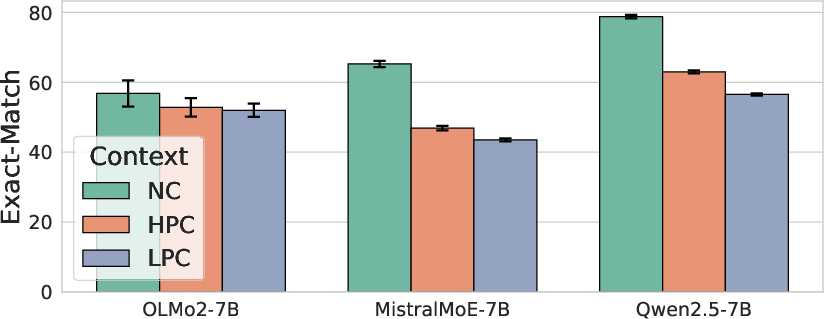
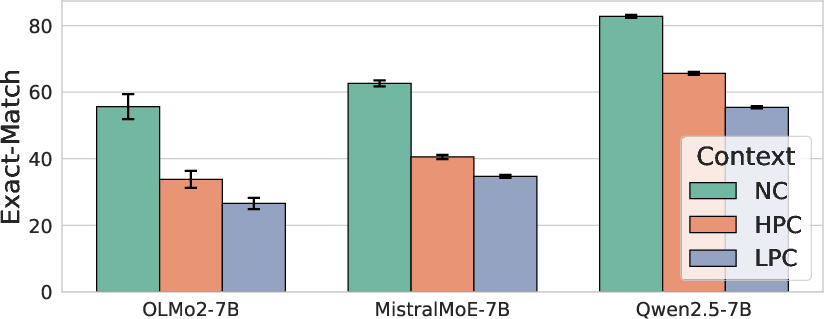
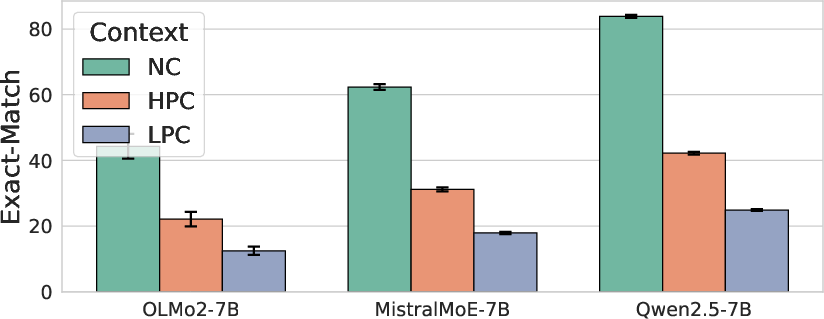
Figure 3: This figure presents an example of a knowledge free task.
- Contextual Knowledge (CK): Tasks that require the model to gather relevant knowledge from the given context.
- Parametric Knowledge (PK): Tasks that require the model to rely exclusively on its parametric knowledge.
- Parametric-Contextual Knowledge (PCK): Tasks that explicitly ask the model to integrate both internal knowledge and external context.
- Retrieval Augmented Generation (RAG): Simulates the standard RAG setting where models are not explicitly instructed to prioritize parametric or contextual knowledge.
The authors evaluate the instruction-tuned versions of Mistral-7B, OLMo2-7B, and Qwen2.5-7B on these tasks. The diagnostic data comprises 2,893 instances for Mistral-7B, 177 instances for OLMo, and 6,217 instances for Qwen2.5-7B, with each instance including NC, HPC, and LPC evidence types.
Key Findings and Analysis
The study reveals several key insights into the behavior of LLMs under knowledge conflict:
- Conflict Impairs Performance: Model performance consistently decreases when presented with instances that contradict their parametric knowledge. Performance follows the order NC > HPC > LPC across models and knowledge-centric tasks.
- Inability to Suppress Internal Knowledge: Models struggle to fully suppress their internal knowledge, even when explicitly instructed to rely solely on the provided context. This is evident in the CK tasks, where models still exhibit a clear NC > HPC > LPC performance ordering despite being told to ignore their own beliefs.
- Preference for Plausible Contexts: When exposed to conflicting passages, models favor the more plausible one. In the RAG setting, accuracy is higher on (NC, HPC) pairs than on (NC, LPC) pairs, indicating a preference for passages that align with real-world knowledge.
- Rationales Strengthen Context Reliance: Providing rationales that explain the conflict increases a model's reliance on contextual information. In PK and PCK tasks, the inclusion of rationales (HPCE) leads the model to depend more on the contextual knowledge.
- Unreliable LLMs as Judges: Knowledge conflict can lead to unreliable LLM-based evaluations. The study finds that LLMs used as evaluators may exhibit bias due to their internal knowledge, resulting in inaccurate evaluations.
Implications and Discussion
The findings of this paper have significant implications for both the application and evaluation of LLMs. The study underscores the importance of understanding and mitigating the effects of internal knowledge bias, particularly when using LLMs in knowledge-intensive tasks. The inability of models to fully suppress their internal knowledge raises concerns about the validity of model-based evaluations, as LLMs may inadvertently incorporate their own beliefs when assessing the correctness of generated content.
The paper discusses the challenge of disentangling memory and instruction following in LLMs, noting that all behavior is associated with the models' learned parameters, which inevitably encode their parametric knowledge. The authors suggest that future research should focus on developing conflict-resolution strategies for LLMs, enabling them to reconcile contradictory information rather than favoring one knowledge source over the other.
Conclusion
This paper provides a comprehensive analysis of the role of context-memory conflict in model performance. The diagnostic framework introduced in the study enables the systematic evaluation of LLMs under varying degrees of knowledge conflict. The findings highlight the importance of mitigating the effects of internal knowledge bias and question the reliability of model-based evaluations in settings where models act as judges over content that may conflict with their parametric knowledge. Future research should focus on developing conflict-resolution strategies for LLMs and disentangling knowledge from instruction following.

