- The paper introduces Switch Sparse Autoencoders, a novel approach that routes activations through specialized expert networks for efficient dictionary learning.
- It employs a dual-loss training strategy balancing reconstruction error and routing loss, achieving an order-of-magnitude reduction in compute requirements.
- Empirical evaluations demonstrate that FLOP-matched Switch SAEs outperform dense TopK SAEs in reconstruction efficiency while maintaining competitive performance.
Efficient Dictionary Learning with Switch Sparse Autoencoders
"Efficient Dictionary Learning with Switch Sparse Autoencoders" presents a novel architecture known as Switch Sparse Autoencoders (SAEs) designed to reduce computational costs inherent in scaling sparse autoencoders to LLMs. The paper provides a comprehensive evaluation of Switch SAEs and contrasts their performance against standard TopK and dense SAEs.
Introduction
Sparse autoencoders serve as a tool for deconstructing neural network activations into interpretable features. They face challenges when scaling to high-width autoencoders required for large frontier models due to substantial compute demands. Switch SAEs, inspired by sparse mixture of expert models, address these challenges by routing activation vectors among specialized "expert" autoencoders, thereby optimizing computational efficiency.
Switch Sparse Autoencoder Architecture
Switch SAEs comprise multiple smaller expert SAEs and a learnable routing mechanism that determines which expert should handle a specific input. This architecture draws on the principles behind sparse mixtures of experts and the Switch layer architecture, previously shown to scale models while maintaining computational efficiency [Fedus et al., 2022]. The rationale behind Switch SAEs is providing a path for substantial reductions in training FLOPs while simultaneously enabling scalability to a greater number of features.
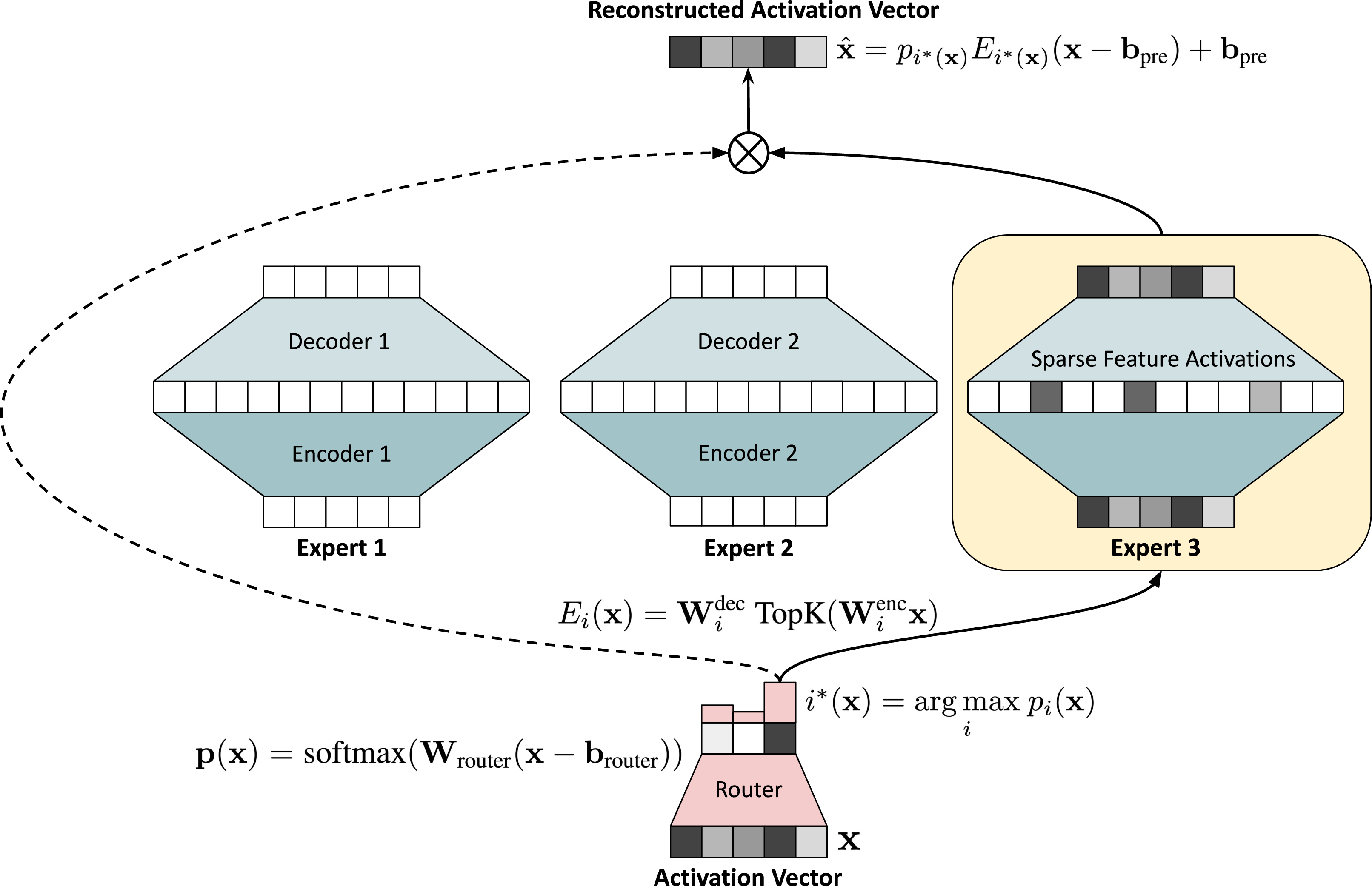
Figure 1: Switch Sparse Autoencoder Architecture. The router computes a probability distribution over expert SAEs and routes the input activation vector to the expert with the highest probability. The figure depicts the architecture for d=5, N=3, M=12.
Training Methodologies
Switch SAEs utilize a dual-loss training strategy balancing reconstruction mean squared error (MSE) and an auxiliary routing loss designed to ensure balanced usage of expert networks. This balance is crucial to prevent bottlenecks caused by uneven expert utilization. The total loss is optimized using the Adam optimizer with a load balancing hyperparameter to tune the influence of the auxiliary loss component.
Empirical Results
Scaling Analysis
Benchmarked against dense TopK SAEs, Switch SAEs displayed favorable scaling laws with improved reconstruction error per compute unit. Notably, Switch SAEs achieved equivalent reconstruction performance with approximately an order of magnitude reduction in computational resources as dense TopK SAEs.
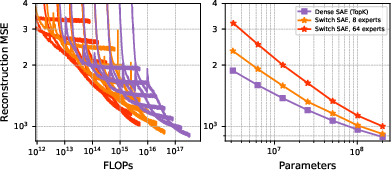
Figure 2: Scaling laws for Switch SAEs. We train dense TopK SAEs and Switch SAEs of varying size with fixed k=32. Switch SAEs achieve better reconstruction than dense SAEs at a fixed compute budget.
The performance comparison of Switch SAEs against TopK, ReLU, and Gated SAEs demonstrates the Pareto efficiency of FLOP-matched Switch SAEs, which dominate the performance of these architectures across both MSE and recovered loss metrics. However, at constant width, Switch SAEs exhibit slightly degraded reconstruction capabilities compared to TopK SAEs.
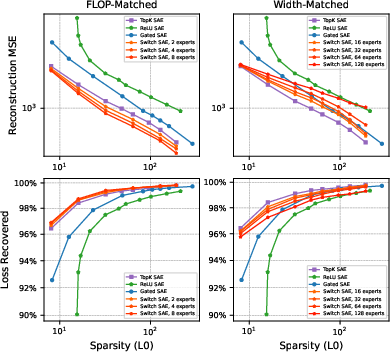
Figure 3: Pareto frontier of sparsity versus reconstruction mean squared error and loss recovered. FLOP-matched Switch SAEs Pareto-dominate TopK SAEs using the same amount of compute.
Feature Geometry and Interpretation
Feature analysis reveals increased feature duplication within Switch SAEs, where similar features appear across multiple experts. t-SNE projections of the SAE features indicate distinct clustering for encoder features, aligning with specific experts, albeit accompanied by redundant isolated feature grouping.
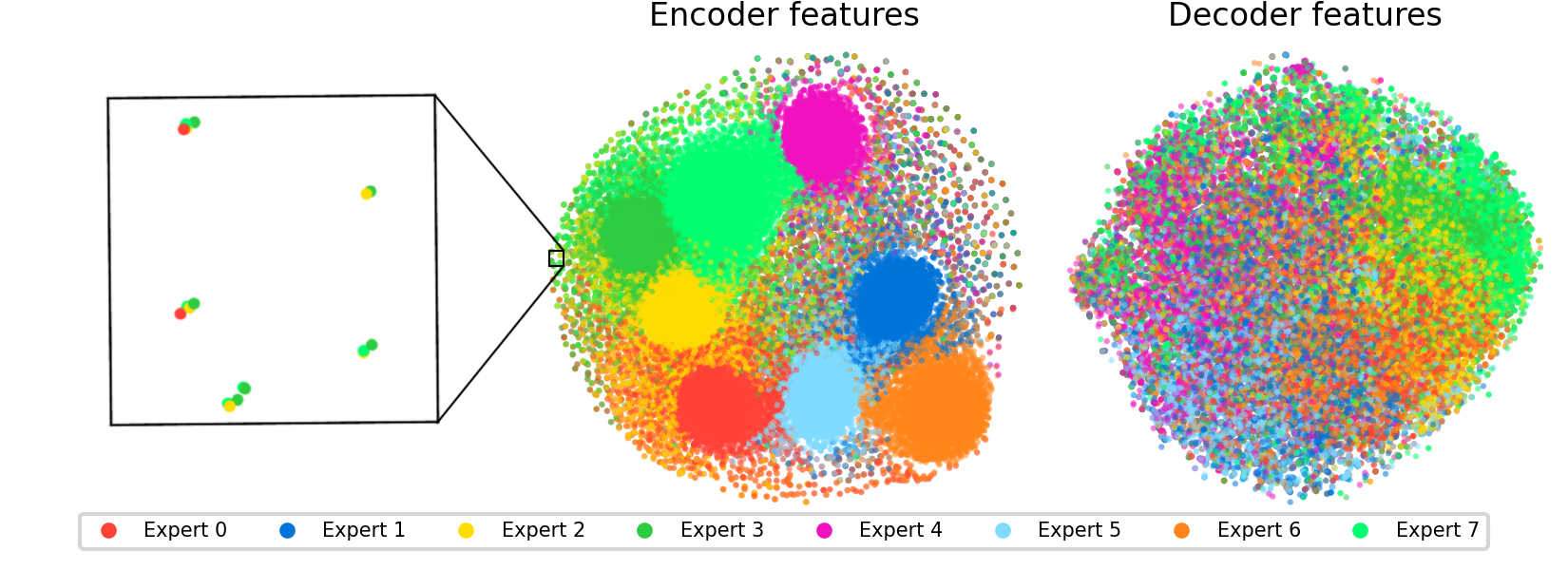
Figure 4: t-SNE projections of encoder and decoder features for a Switch SAE with 65k total features and 8 experts.
Additionally, automated interpretability assessments indicate analogous interpretability levels between FLOP-matched Switch SAEs and TopK counterparts, while the width-matched configurations, though showing a higher rate of true positive detections, have decreased true negative accuracy.
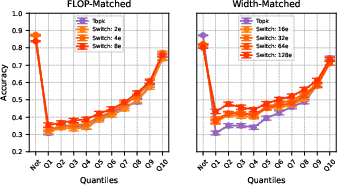
Figure 5: Automated interpretability detection results across SAE feature activation quantiles for 1000 random features.
Conclusion
Switch SAEs demonstrate a significant advancement toward computationally efficient sparse encoding, presenting a pathway for scaling sparse autoencoders to larger models without compromising interpretability or dramatically increasing computational overhead. Moving forward, this architecture offers promising potential for application within extensive GPU-cluster scenarios, where each expert can occupy individual GPU resources, thereby enhancing training efficiency. Future research might explore deduplication strategies, novel routing algorithms, and multi-expert activations to further refine and optimize the model's performance.