- The paper challenges the traditional dichotomy between aleatoric and epistemic uncertainties by demonstrating its inadequacy for LLM agents.
- The authors analyze empirical findings to show how simplistic models yield broad, misleading uncertainty estimates in dynamic interactive settings.
- The paper proposes novel research avenues such as underspecification uncertainties, interactive learning, and narrative output to improve uncertainty quantification.
Uncertainty Quantification Reassessment for LLM Agents
Introduction
The paper "Position: Uncertainty Quantification Needs Reassessment for Large-LLM Agents" (2505.22655) embarks on a critical analysis of uncertainty quantification paradigms, specifically targeting the dichotomy between aleatoric and epistemic uncertainties within the context of LLMs. Whereas traditional machine learning frameworks neatly separate these forms of uncertainty, the current work posits that this methodology is inadequate for the dynamic and interactive environments in which LLMs operate.

Figure 1: The traditional view on uncertainties suggests a clear black-and-white dichotomy between aleatoric and epistemic uncertainty.
Critique of Traditional Uncertainty Dichotomy
Historically, uncertainty quantification bifurcates into aleatoric and epistemic. Aleatoric uncertainty is purportedly irreducible and stems from inherent data noise, while epistemic uncertainty can be minimized with additional knowledge or data. The paper showcases that such definitions are paradoxical when applied to LLM scenarios. For example, binary predictions exhibit diverse interpretations of epistemic uncertainty. Some frameworks deem maximum epistemic uncertainty when models starkly disagree (Figure 2), whereas others minimize it when options are concise.
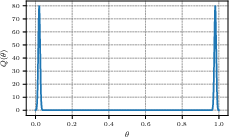
Figure 2: In binary prediction, some perceive maximum epistemic uncertainty where others see minimal epistemic uncertainty.
Aleatoric uncertainties also present challenges. Using simplistic models can yield broad uncertainty estimates, questioning whether these are intrinsically irreducible or a result of model inadequacy. The paper emphasizes that many schools of thought dispute the irrevocability of certain uncertainties, positing data-uncertainty perspectives that call for model class reconsideration (Figure 3).
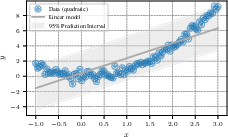
Figure 3: Using simple models for complex data results in wide uncertainty estimates—whether irreducible or reducible is debated.
Moreover, these uncertainties frequently interweave, contradicting the expectation of disentanglement. The paper references empirical studies accentuating the entanglement in estimations (Figure 4), challenging the validity of strictly additive decomposition strategies.
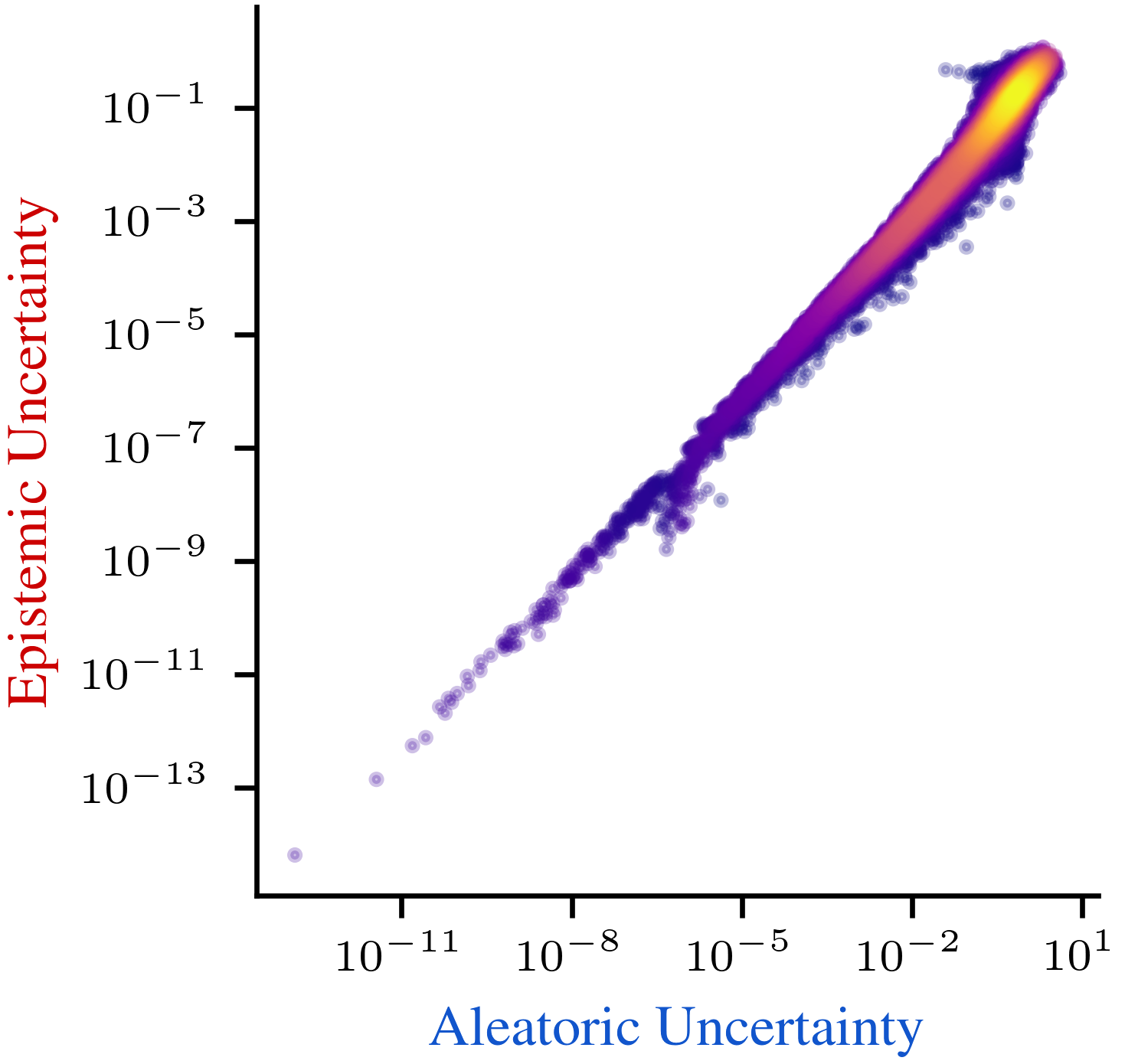
Figure 4: Aleatoric and epistemic uncertainties often cannot be disentangled across various methods.
Novel Research Directions
The paper advocates for evolving how uncertainties are addressed in interactive LLM environments. It outlines three novel research avenues:
Underspecification Uncertainties: These arise when user inputs are incomplete or ambiguous, making traditional dichotomies obsolete. The paper urges a focus on more dynamic uncertainty definitions that account for the flexible input nature in LLM interactions.
Interactive Learning: Unlike traditional active learning, interactive learning prioritizes task-specific knowledge acquisition during LLM interactions—rather than improving overall model performance. This necessitates developing methods that intelligently query users to refine underspecified questions without disengaging the user.
Output Uncertainties: Moving beyond scalar representations, LLMs should effectively communicate uncertainties in narrative form, providing context-rich explanations of ambiguities and potential resolutions. This narrative output could inherently convey the reasoning behind uncertainty, thereby enhancing decision-making frameworks.
Alternative Perspectives
The paper also acknowledges counter-positions to its thesis. It recognizes continuing value in aleatoric and epistemic uncertainty quantification for conventional machine learning tasks, particularly for training LLMs. Despite the conflicts outlined with these traditional approaches, they remain widespread and useful benchmarks in many structured applications.
Additionally, interactive learning could be addressed by next-token prediction models trained on existing interaction datasets, although this does not inherently resolve the requirement for faithful internal uncertainty reflection.
Finally, numerical uncertainty outputs, though likely less informative for human users than narrative forms, retain their utility in automated systems where simple thresholds guide decision processes.
Conclusion
In conclusion, this paper asserts that the dichotomy between aleatoric and epistemic uncertainties is restrictive and insufficient for LLM agents engaging in nuanced human-computer interactions. The suggested novel avenues aim to evolve uncertainty quantification towards more intuitive, contextually informed frameworks, fostering more transparent and interactive LLM deployments. The challenges and opportunities outlined provide a roadmap for future research in dynamic uncertainty assessment and communication within AI systems.


