- The paper's main contribution is demonstrating that VLMs use Binding IDs to link visual objects with textual descriptions in a synthetic shapes task.
- Factorability experiments show that swapping activations between samples validates the model's ability to associate object, color, and item attributes across modalities.
- Position independence and mean intervention tests confirm that binding vectors are robust and adaptable, enhancing the interpretability of cross-modal associations.
Investigating Mechanisms for In-Context Vision Language Binding
Introduction
The paper "Investigating Mechanisms for In-Context Vision Language Binding" (2505.22200) explores the binding mechanisms of Vision-LLMs (VLMs). The paper explores how VLMs associate visual information with textual elements using a mechanism similar to Binding IDs traditionally studied in LLMs. The authors use a synthetic task, known as the "Shapes Task," designed to evaluate how well such models can associate labeled 3D objects from images to textual descriptions, providing insight into the internal workings of state-of-the-art VLMs.
The Shapes Task
The "Shapes Task" is introduced as an experimental setup within which the capabilities of VLMs to draw contextual associations between visual and textual inputs are assessed. In this task, images display two distinct 3D objects, each associated with unique textual descriptions based on their color and an assigned item. The goal is for the VLM to ascertain which text corresponds to which object, taking cues from bindings that VLMs allegedly maintain across these multi-modal inputs.

Figure 1: Shapes Task. Given an image with two 3D objects and a text description (context), the model needs to comprehend the question and identify the correct item (token_p) contained in the queried object.
Binding ID Mechanism in VLMs
The paper posits that, like in LLMs, VLMs employ a binding mechanism where specific vectors, termed Binding IDs, encode associations between different concepts across modalities. These IDs are postulated to facilitate the necessary alignments between objects, their characteristics, and the attributes described in text. The study is structured around two principal tests: factorability and position independence, both key to validating Binding IDs' presence in VLMs.
Factorizability
In the factorability study, researchers explore whether object, color, and item activations contain binding vectors. By replacing certain activations between different samples, the study demonstrates how the model can correctly associate these exchanged attributes with different visual entities, confirming the presence of a binding mechanism that transcends simple object recognition to complex associative tasks.
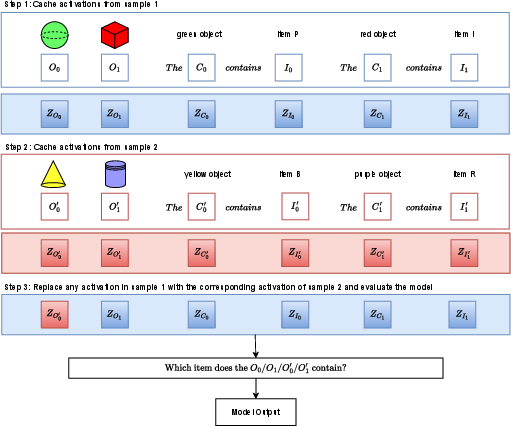
Figure 2: Causal intervention. In steps 1 and 2, activations from the first and second samples are saved. In step 3, object/color/item activations in the first sample are replaced with those from the second.
Position Independence
This test examines if binding vectors are independent of token positions within the model's architectural framework. Despite manipulating the spatial arrangement of object, color, and item vectors within the input sequence, VLMs successfully maintain correct associative mappings, reinforcing the hypothesis that bindings are position-agnostic.
Mean Interventions
To further probe into the Binding ID dynamics, the authors conduct mean intervention experiments. These involve using mean differences in activation spaces to swap the binding representations between different samples, observing a corresponding shift in model predictions. This robustly confirms the adaptability and reusability of binding vectors across contexts, bolstering the evidence for the proposed mechanism.
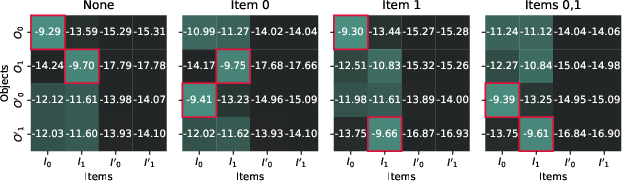
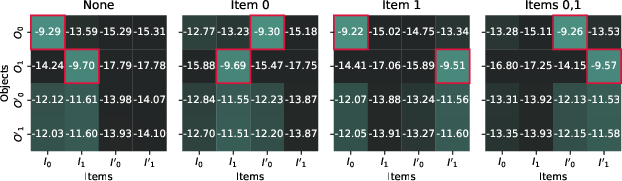
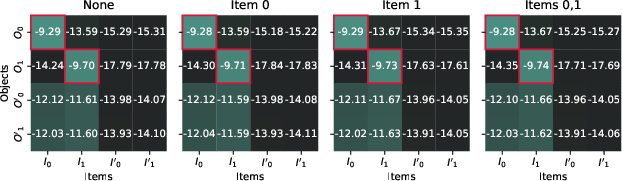
Figure 3: Object activation replacements.
Experimental Results
Empirical results reveal a clear affirmation of the existence of Binding IDs in VLMs. Through careful manipulation of activation states, it is evident that VLMs encode and utilize binding information analogous to that found in text-only LLMs. This suggests that multimodal models may share a unified approach to contextual comprehension, irrespective of input modality.
Implications and Future Directions
This study sheds light on the internal workings of VLMs, particularly in how they manage cross-modal associations. The implications are significant for advancing the interpretability and robustness of VLMs in real-world applications, especially within safety-critical domains as they integrate seamlessly with complex, context-sensitive tasks. Future research could extend these findings into more complex environments or explore ways to enhance binding representations, potentially elevating model performance in comprehensive reasoning tasks.
Conclusion
The paper offers a sophisticated examination of the binding mechanisms within VLMs, proposing that these models indeed utilize a system of Binding IDs, akin to those found in LLMs, to merge and refine information across visual and textual domains. Through meticulous experimentation, the research substantiates the hypothesis of a cohesive binding mechanism, setting the stage for subsequent explorations into more intricate cross-modal binding phenomena.